

How to install hadoop in linux

How to install Hadoop on Linux: 1. Install the ssh service; 2. Use ssh to log in without password authentication; 3. Download the Hadoop installation package; 4. Unzip the Hadoop installation package; 5. Configure the corresponding Hadoop Just file.

The operating environment of this article: ubuntu 16.04 system, Hadoop version 2.7.1, Dell G3 computer.
How to install hadoop on linux?
[Big Data] Detailed explanation of installing Hadoop (2.7.1) and running WordCount under Linux
1. Introduction
After completion After configuring the Storm environment, I wanted to tinker with the installation of Hadoop. There were many tutorials on the Internet, but none of them were particularly suitable, so I still encountered a lot of trouble during the installation process. After constantly consulting the information, I finally solved it. Question, I still feel very good about it. Let’s not talk too much nonsense and let’s get to the point.
The configuration environment of this machine is as follows:
Hadoop(2.7.1)
Ubuntu Linux (64-bit system)
The following are divided into several steps Let’s explain the configuration process in detail.
2. Install ssh service
Enter the shell command and enter the following command to check whether the ssh service has been installed. If not, use the following command to install it:
sudo apt-get install ssh openssh-server
The installation process is relatively easy and enjoyable.
3. Use ssh for passwordless authentication login
1. Create ssh-key. Here we use rsa method and use the following command:
ssh-keygen -t rsa -P ""
2. A graphic will appear. The graphic that appears is the password. Don’t worry about it
cat ~/. ssh/id_rsa.pub >> authorized_keys (it seems to be omitted)
3. Then you can log in without password verification, as follows:
ssh localhost
The successful screenshot is as follows:

4. Download the Hadoop installation package
There are also downloads for Hadoop installation Two ways
1. Go directly to the official website to download, http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2. Use shell to download, the command is as follows:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar. gz
It seems that the second method is faster. After a long wait, the download is finally completed.
5. Decompress the Hadoop installation package
Use the following command to decompress the Hadoop installation package
tar -zxvf hadoop-2.7.1.tar. gz
After decompression is completed, the folder of hadoop2.7.1 appears
6. Configure the corresponding files in Hadoop
The files that need to be configured are as follows, hadoop-env.sh, core-site.xml, mapred-site.xml.template, hdfs-site.xml, all files are located under hadoop2.7.1/etc/hadoop. The specific required configuration is as follows:
1.core-site.xml is configured as follows:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/leesf/program/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
The path of hadoop.tmp.dir can be set according to your own habits.
2.mapred-site.xml.template is configured as follows:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
3.hdfs-site.xml is configured as follows:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/leesf/program/hadoop/tmp/dfs/data</value> </property> </configuration>
Among them, dfs.namenode.name.dir The paths to dfs.datanode.data.dir can be set freely, preferably under the directory of hadoop.tmp.dir.
In addition, if you find that jdk cannot be found when running Hadoop, you can directly place the path of jdk in hadoop.env.sh, as follows:
export JAVA_HOME="/home/ leesf/program/java/jdk1.8.0_60"
7. Run Hadoop
After the configuration is completed, run hadoop.
1. Initialize the HDFS system
Use the following command in the hadop2.7.1 directory:
bin/hdfs namenode -format
The screenshot is as follows:

The process requires ssh authentication. You have already logged in before, so just type y between the initialization process.
The successful screenshot is as follows:

Indicates that the initialization has been completed.
2. Start the NameNode and DataNode daemons
Use the following command to start:
sbin/start- dfs.sh, the successful screenshot is as follows:
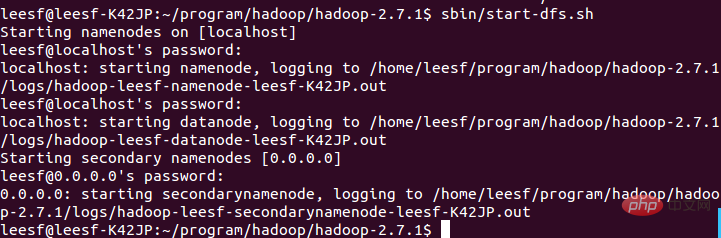
3. View process information
Use the following command to view process information
jps, the screenshot is as follows:
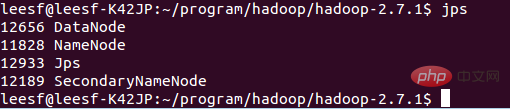
Indicates that both DataNode and NameNode have been turned on
4. View Web UI
Enter http://localhost:50070 in the browser to view relevant information. The screenshot is as follows:
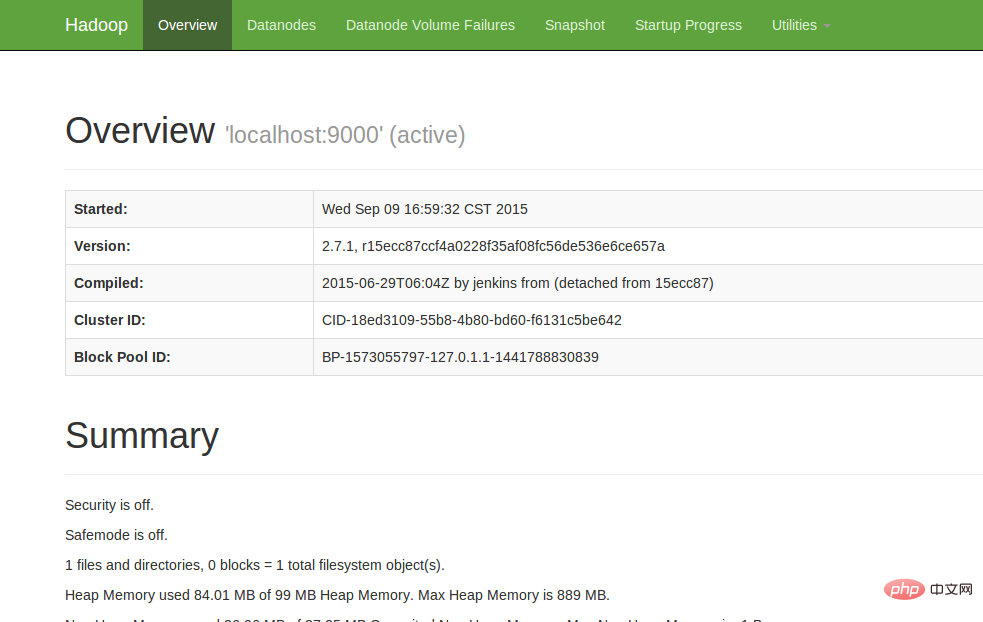
At this point, the hadoop environment has been set up. Let's start using hadoop to run a WordCount example.
8. Run WordCount Demo
1. Create a new file locally. The author created a new word document in the home/leesf directory. You can fill in the content as you like. .
2. Create a new folder in HDFS for uploading local word documents. Enter the following command in the hadoop2.7.1 directory:
bin/hdfs dfs -mkdir /test, which means A test directory was created under the root directory of hdfs
Use the following command to view the directory structure under the root directory of HDFS
bin/hdfs dfs -ls /
Specific screenshots As follows:

… Over welcome] in a test directory has been created under the root directory of HDFS
Use the following command to upload:
bin/hdfs dfs -put /home/leesf/words /test/
Use the following command to view
bin/ hdfs dfs -ls /test/
The screenshot of the result is as follows:
 It means that the local word document has been uploaded to the test directory.
It means that the local word document has been uploaded to the test directory.
4. Run wordcount
Use the following command to run wordcount:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/words /test/out
#
After the operation is completed, generate a file named out in the /test directory, use the following Command to view the files in the /test directory 
It means that it is in the test directory There is already a file directory named Out
It means it has been successfully run and the result is saved in part-r-00000. 
At this point, the running process has been completed. 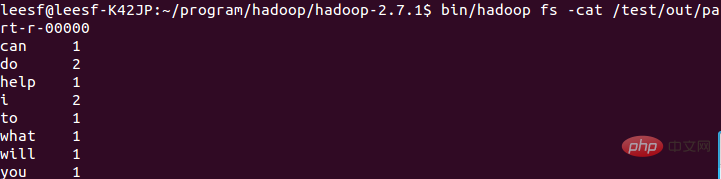
9. Summary
I encountered many problems during this hadoop configuration process. The commands of hadoop1.x and 2.x are still very different. The configuration process I still solved the problems one by one, the configuration was successful, and I gained a lot. I would like to share the experience of this configuration for the convenience of all gardeners who want to configure the Hadoop environment. If you have any questions during the configuration process, please feel free to discuss them. , thank you all for watching~
Recommended study: "linux video tutorial
"The above is the detailed content of How to install hadoop in linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
DeepSeek is a powerful intelligent search and analysis tool that provides two access methods: web version and official website. The web version is convenient and efficient, and can be used without installation; the official website provides comprehensive product information, download resources and support services. Whether individuals or corporate users, they can easily obtain and analyze massive data through DeepSeek to improve work efficiency, assist decision-making and promote innovation.
 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi OKX, the world's leading digital asset exchange, has now launched an official installation package to provide a safe and convenient trading experience. The OKX installation package of Ouyi does not need to be accessed through a browser. It can directly install independent applications on the device, creating a stable and efficient trading platform for users. The installation process is simple and easy to understand. Users only need to download the latest version of the installation package and follow the prompts to complete the installation step by step.
 BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet is a cryptocurrency exchange that provides a variety of trading services including spot trading, contract trading and derivatives. Founded in 2018, the exchange is headquartered in Singapore and is committed to providing users with a safe and reliable trading platform. BITGet offers a variety of trading pairs, including BTC/USDT, ETH/USDT and XRP/USDT. Additionally, the exchange has a reputation for security and liquidity and offers a variety of features such as premium order types, leveraged trading and 24/7 customer support.
 Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Gate.io is a popular cryptocurrency exchange that users can use by downloading its installation package and installing it on their devices. The steps to obtain the installation package are as follows: Visit the official website of Gate.io, click "Download", select the corresponding operating system (Windows, Mac or Linux), and download the installation package to your computer. It is recommended to temporarily disable antivirus software or firewall during installation to ensure smooth installation. After completion, the user needs to create a Gate.io account to start using it.
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, also known as OKX, is a world-leading cryptocurrency trading platform. The article provides a download portal for Ouyi's official installation package, which facilitates users to install Ouyi client on different devices. This installation package supports Windows, Mac, Android and iOS systems. Users can choose the corresponding version to download according to their device type. After the installation is completed, users can register or log in to the Ouyi account, start trading cryptocurrencies and enjoy other services provided by the platform.
 How to automatically set permissions of unixsocket after system restart?
Mar 31, 2025 pm 11:54 PM
How to automatically set permissions of unixsocket after system restart?
Mar 31, 2025 pm 11:54 PM
How to automatically set the permissions of unixsocket after the system restarts. Every time the system restarts, we need to execute the following command to modify the permissions of unixsocket: sudo...
 Why does an error occur when installing an extension using PECL in a Docker environment? How to solve it?
Apr 01, 2025 pm 03:06 PM
Why does an error occur when installing an extension using PECL in a Docker environment? How to solve it?
Apr 01, 2025 pm 03:06 PM
Causes and solutions for errors when using PECL to install extensions in Docker environment When using Docker environment, we often encounter some headaches...
