
 Database
Mysql Tutorial
After reading, understand MySQL persistence and rollback (detailed explanation with pictures and text)
Database
Mysql Tutorial
After reading, understand MySQL persistence and rollback (detailed explanation with pictures and text)
After reading, understand MySQL persistence and rollback (detailed explanation with pictures and text)

This article brings you relevant knowledge about persistence and rollback in mysql. I hope it will be helpful to you.

redo log
Transaction support is one of the important features of the database that distinguishes file systems. The four major characteristics of transactions:
- Atomicity: All operations are either done or none, indivisible.
- Consistency: The result of the database changing from one state to another is ultimately consistent. For example, A transfers 500 to B. A ends up losing 500, and B ends up having 500 more, but A B’s The value never changes.
- Isolation: Transactions and transactions are isolated from each other and do not interfere with each other.
- Persistence: Once a transaction is committed, its changes to the data are permanent.
This article mainly talks about persistence-related knowledge.
When we update a record in a transaction, for example:
update user set age=11 where user_id=1;
The process is probably like this:
- First determine where the user_id data is Is the page in the memory? If not, first read it from the database and then load it into the memory.
- Modify the age in the memory to 11
- Write the redo log, and redo log In prepare state
- Write binlog
- Commit transaction, redo log becomes commit state
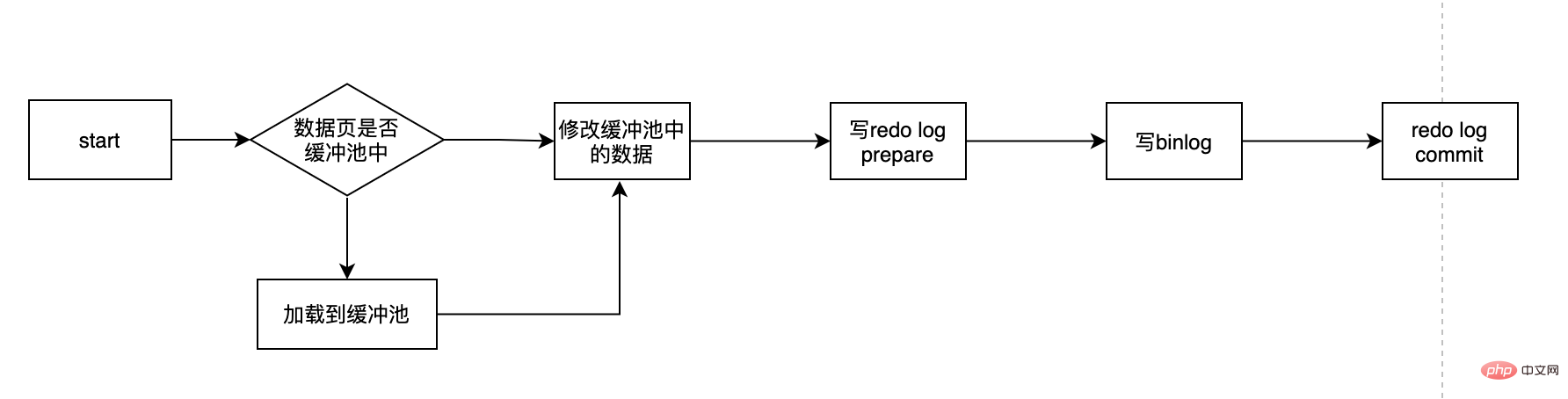
There are several here Key point: What is redo log? Why do we need redo log? What is the redo log in prepare state? Can I choose only one of redo log and binlog...? With this series of questions, let's unveil redo log.
Why do we need to update the memory data first instead of directly updating the disk data?
Why don’t we directly update the corresponding disk data every time we update data? First of all, we know that disk IO is slow and memory is fast. The speeds of the two are not of the same order of magnitude. So for slow disk IO, indexes appear. Through indexes, even if there are millions of data, we can still store data on the disk. Find our data very quickly, this is the role of indexes. But the index also needs to be maintained and is not static. When we insert a new piece of data A, since this data is to be inserted after the existing data B, the B data must be moved to make room for A. This There is a certain overhead.
What's worse is that if the page to be inserted is already full, then you have to apply for a new page and then move some data there. This is called page splitting, which is more expensive. If our sql change is to directly modify the data on the disk, and the above problem happens to occur, then the efficiency at this time will be very low, and in severe cases, it will cause a timeout. This is why the above update process needs to load the corresponding data page first. in memory, and then update the data in memory first. For mysql, all changes must first update the data in the buffer pool, and then the dirty pages in the buffer pool will be flushed to the disk at a certain frequency (checkPoint mechanism), and optimized through the buffer pool The gap between the CPU and the disk ensures that the overall performance does not drop too quickly.
Why do we need redo log?
The buffer pool can help us eliminate the gap between the CPU and the disk. The checkpoint mechanism can ensure the final placement of the data. However, the checkpoint is not triggered every time there is a change, but the master Threads are processed at intervals. So the worst case scenario is that the buffer pool has just been written and the database crashes, then this data is lost and cannot be recovered. In this case, D in ACID is not satisfied. In order to solve the persistence problem in this case, the InnoDB engine transaction uses WAL technology (Write-Ahead Logging). The idea of this technology is to write the log first and then write to the disk. Only when the log is successfully written can the transaction be considered successful. The log here is the redo log. When a downtime occurs and the data is not flushed to the disk, it can be restored through redo log to ensure D in ACID. This is the role of redo log.
How is redo log implemented?
The writing of redo log is not written directly to the disk. The redo log also has a buffer, which is called redo log buffer (redo log buffer). The InnoDB engine will first write the redo log Write the redo log buffer, and then flush it into the real redo log at a certain frequency. The redo log buffer generally does not need to be particularly large. It is just a temporary container. The master thread will flush the redo log buffer to the redo log file every second. , so we only need to ensure that the redo log buffer can store the amount of data changed by transactions within 1 second. Taking mysql5.7.23 as an example, the default is 16M.
mysql> show variables like '%innodb_log_buffer_size%'; +------------------------+----------+ | Variable_name | Value | +------------------------+----------+ | innodb_log_buffer_size | 16777216 | +------------------------+----------+
A 16M buffer is enough to handle most applications. The strategies for synchronizing the buffer to the redo log mainly include the following:
- master线程每秒将buffer刷到到redo log中
- 每个事务提交的时候会将buffer刷到redo log中
- 当buffer剩余空间小于1/2时,会被刷到redo log中
需要注意的是redo log buffer刷到redo log的过程并不是真正的刷到磁盘中去了,只是刷入到os cache中去,这是现代操作系统为了提高文件写入的效率做的一个优化,真正的写入会交给系统自己来决定(比如os cache足够大了)。那么对于InnoDB来说就存在一个问题,如果交给系统来fsync,同样如果系统宕机,那么数据也丢失了(虽然整个系统宕机的概率还是比较小的)。针对这种情况,InnoDB给出innodb_flush_log_at_trx_commit策略,让用户自己决定使用哪个。
mysql> show variables like 'innodb_flush_log_at_trx_commit'; +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | innodb_flush_log_at_trx_commit | 1 | +--------------------------------+-------+
- 0:表示事务提交后,不进行fsync,而是由master每隔1s进行一次重做日志的fysnc
- 1:默认值,每次事务提交的时候同步进行fsync
- 2:写入os cache后,交给操作系统自己决定什么时候fsync
从3种刷入策略来说:
2肯定是效率最高的,但是只要操作系统发生宕机,那么就会丢失os cache中的数据,这种情况下无法满足ACID中的D
0的话,是一种折中的做法,它的IO效率理论是高于1的,低于2的,它的数据安全性理论是要低于1的,高于2的,这种策略也有丢失数据的风险,也无法保证D。
1是默认值,可以保证D,数据绝对不会丢失,但是效率最差的。个人建议使用默认值,虽然操作系统宕机的概率理论小于数据库宕机的概率,但是一般既然使用了事务,那么数据的安全应该是相对来说更重要些。
redo log是对页的物理修改,第x页的第x位置修改成xx,比如:
page(2,4),offset 64,value 2
在InnoDB引擎中,redo log都是以512字节为单位进行存储的,每个存储的单位我们称之为redo log block(重做日志块),若一个页中存储的日志量大于512字节,那么就需要逻辑上切割成多个block进行存储。
一个redo log block是由日志头、日志体、日志尾组成。日志头占用12字节,日志尾占用8字节,所以一个block真正能存储的数据就是512-12-8=492字节。
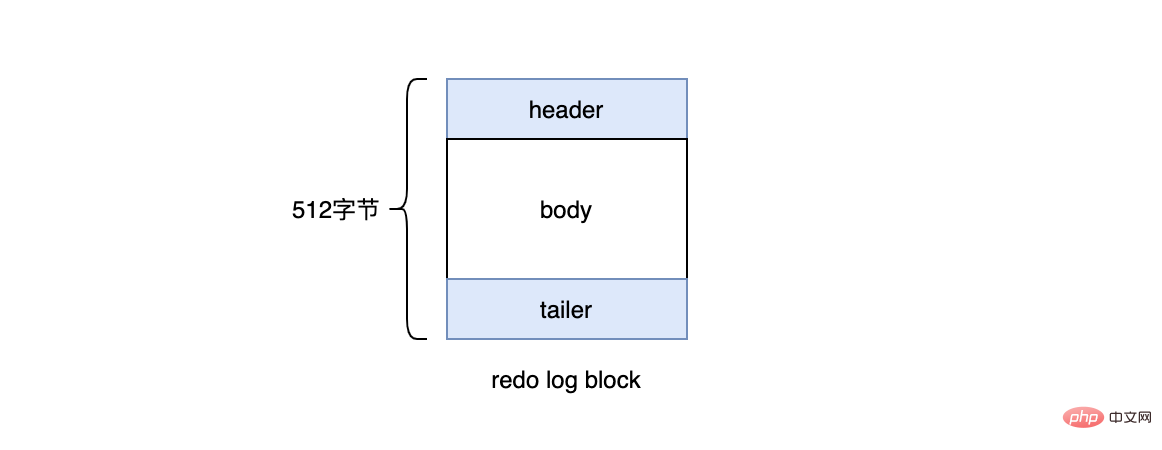
多个redo log block组成了我们的redo log。
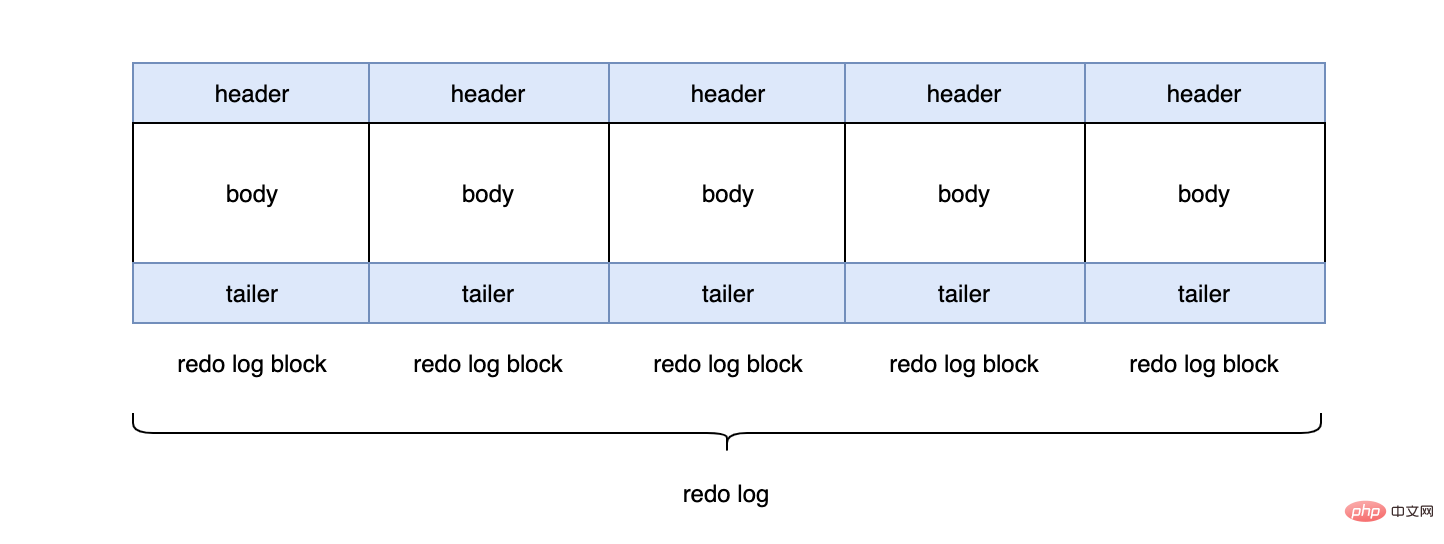
每个redo log默认大小为48M:
mysql> show variables like 'innodb_log_file_size'; +----------------------+----------+ | Variable_name | Value | +----------------------+----------+ | innodb_log_file_size | 50331648 | +----------------------+----------+
InnoDB默认2个redo log组成一个log组,真正工作的就是这个log组。
mysql> show variables like 'innodb_log_files_in_group'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_log_files_in_group | 2 | +---------------------------+-------+ #ib_logfile0 #ib_logfile1
当ib_logfile0写完之后,会写ib_logfile1,当ib_logfile1写完之后,会重新写ib_logfile0...,就这样一直不停的循环写。
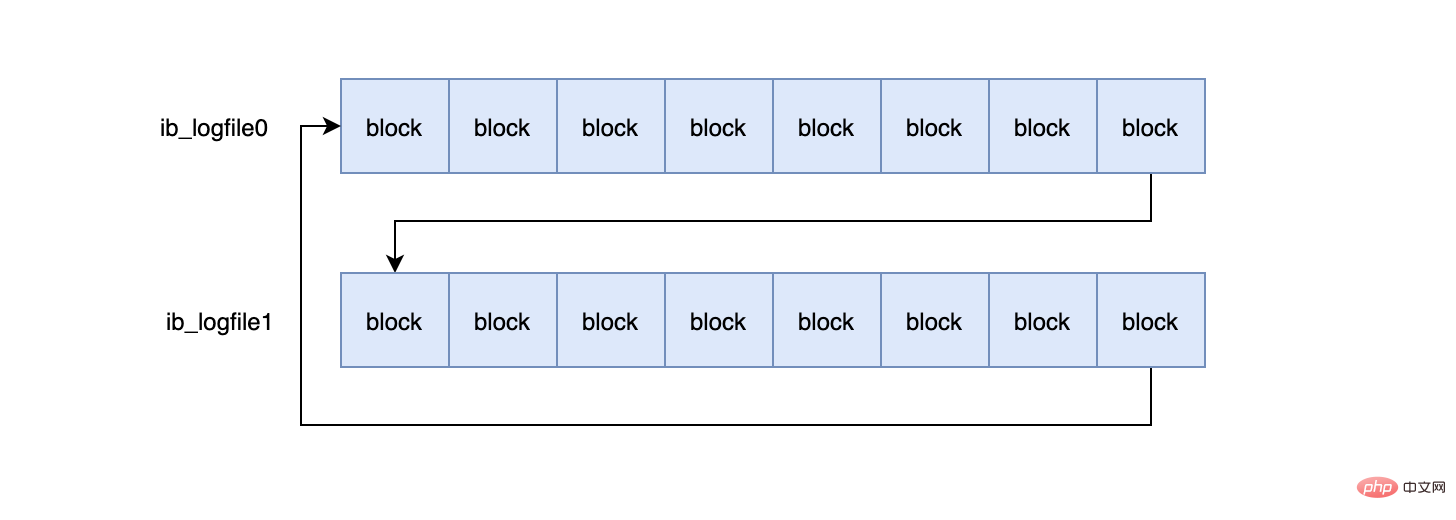
为什么一个block设计成512字节?
这个和磁盘的扇区有关,机械磁盘默认的扇区就是512字节,如果你要写入的数据大于512字节,那么要写入的扇区肯定不止一个,这时就要涉及到盘片的转动,找到下一个扇区,假设现在需要写入两个扇区A和B,如果扇区A写入成功,而扇区B写入失败,那么就会出现非原子性的写入,而如果每次只写入和扇区的大小一样的512字节,那么每次的写入都是原子性的。
为什么要两段式提交?
从上文我们知道,事务的提交要先写redo log(prepare),再写binlog,最后再提交(commit)。这里为什么要有个prepare的动作?redo log直接commit状态不行吗?假设redo log直接提交,在写binlog的时候,发生了crash,这时binlog就没有对应的数据,那么所有依靠binlog来恢复数据的slave,就没有对应的数据,导致主从不一致。
所以需要通过两段式(2pc)提交来保证redo log和binlog的一致性是非常有必要的。具体的步骤是:处于prepare状态的redo log,会记录2PC的XID,binlog写入后也会记录2PC的XID,同时会在redo log上打上commit标识。
redo log和bin log是否可以只需要其中一个?
不可以。redo log本身大小是固定的,在写满之后,会重头开始写,会覆盖老数据,因为redo log无法保存所有数据,所以在主从模式下,想要通过redo log来同步数据给从库是行不通的。那么binlog是一定需要的,binlog是mysql的server层产生的,和存储引擎无关,binglog又叫归档日志,当一个binlog file写满之后,会写入到一个新的binlog file中。
所以我们是不是只需要binlog就行了?redo log可以不需要?当然也不行,redo log的作用是提供crash-safe的能力,首先对于一个数据的修改,是先修改缓冲池中的数据页的,这时修改的数据并没有真正的落盘,这主要是因为磁盘的离散读写能力效率低,真正落盘的工作交给master线程定期来处理,好处就是master可以一次性把多个修改一起写入磁盘。
那么此时就有一个问题,当事务commit之后,数据在缓冲区的脏页中,还没来的及刷入磁盘,此时数据库发生了崩溃,那么这条commit的数据即使在数据库恢复后,也无法还原,并不能满足ACID中的D,然后就有了redo log,从流程来看,一个事务的提交必须保证redo log的写入成功,只有redo log写入成功才算事务提交成功,redo log大部分情况是顺序写的磁盘,所以它的效率要高很多。当commit后发生crash的情况下,我们可以通过redo log来恢复数据,这也是为什么需要redo log的原因。
但是事务的提交也需要binlog的写入成功,那为什么不可以通过binlog来恢复未落盘的数据?这是因为binlog不知道哪些数据落盘了,所以不知道哪些数据需要恢复。对于redo log而言,在数据落盘后对应的redo log中的数据会被删除,那么在数据库重启后,只要把redo log中剩下的数据都恢复就行了。
crash后是如何恢复的?
通过两段式提交我们知道redo log和binlog在各个阶段会被打上prepare或者commit的标识,同时还会记录事务的XID,有了这些数据,在数据库重启的时候,会先去redo log里检查所有的事务,如果redo log的事务处于commit状态,那么说明在commit后发生了crash,此时直接把redo log的数据恢复就行了,如果redo log是prepare状态,那么说明commit之前发生了crash,此时binlog的状态决定了当前事务的状态,如果binlog中有对应的XID,说明binlog已经写入成功,只是没来的及提交,此时再次执行commit就行了,如果binlog中找不到对应的XID,说明binlog没写入成功就crash了,那么此时应该执行回滚。
undo log
redo log是事务持久性的保证,undo log是事务原子性的保证。在事务中更新数据的前置操作其实是要先写入一个undo log中的,所以它的流程大致如下:

什么情况下会生成undo log?
undo log的作用就是mvcc(多版本控制)和回滚,我们这里主要说回滚,当我们在事务里insert、update、delete某些数据的时候,就会产生对应的undo log,当我们执行回滚时,通过undo log就可以回到事务开始的样子。需要注意的是回滚并不是修改的物理页,而是逻辑的恢复到最初的样子,比如一个数据A,在事务里被你修改成B,但是此时有另一个事务已经把它修改成了C,如果回滚直接修改数据页把数据改成A,那么C就被覆盖了。
对于InnoDB引擎来说,每个行记录除了记录本身的数据之外,还有几个隐藏的列:
- DB_ROW_ID:如果没有为表显式的定义主键,并且表中也没有定义唯一索引,那么InnoDB会自动为表添加一个row_id的隐藏列作为主键。
- DB_TRX_ID:每个事务都会分配一个事务ID,当对某条记录发生变更时,就会将这个事务的事务ID写入trx_id中。
- DB_ROLL_PTR:回滚指针,本质上就是指向 undo log 的指针。

当我们执行INSERT时:
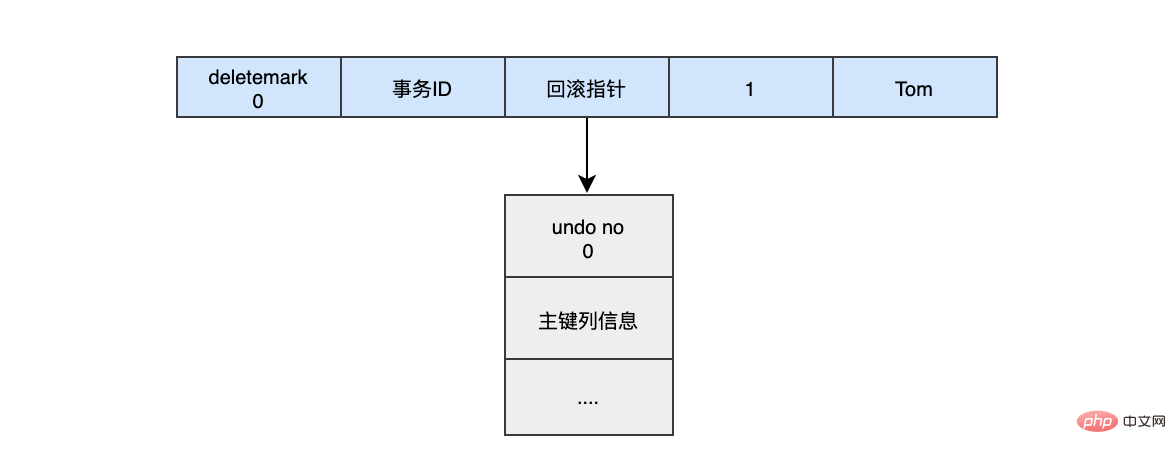
begin;
INSERT INTO user (name) VALUES ("tom")插入的数据都会生一条insert undo log,并且数据的回滚指针会指向它。undo log会记录undo log的序号、插入主键的列和值...,那么在进行rollback的时候,通过主键直接把对应的数据删除即可。
对于更新的操作会产生update undo log,并且会分更新主键的和不更新的主键的,假设现在执行:
UPDATE user SET name="Sun" WHERE id=1;
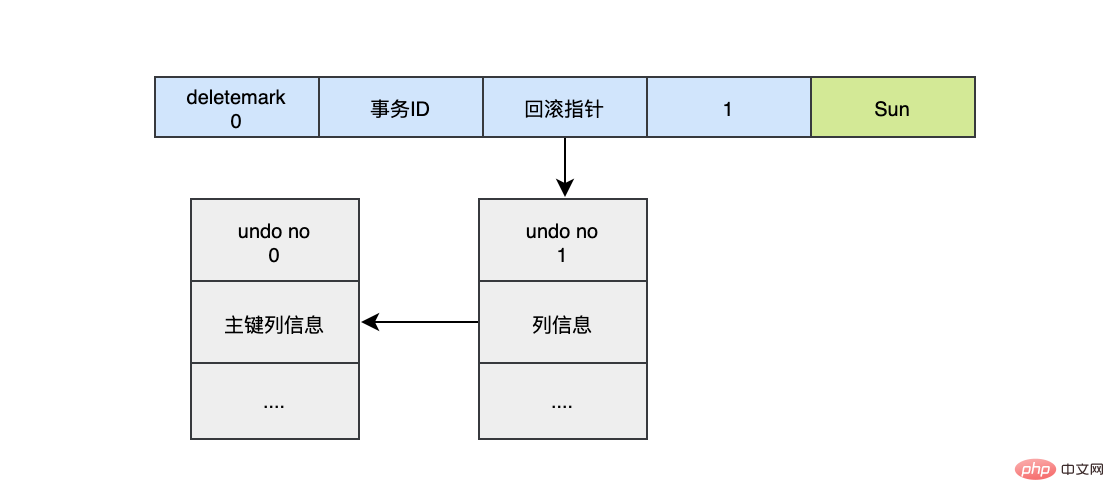
这时会把老的记录写入新的undo log,让回滚指针指向新的undo log,它的undo no是1,并且新的undo log会指向老的undo log(undo no=0)。
假设现在执行:
UPDATE user SET id=2 WHERE id=1;

对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undo log,并且undo log的序号会递增。
可以发现每次对数据的变更都会产生一个undo log,当一条记录被变更多次时,那么就会产生多条undo log,undo log记录的是变更前的日志,并且每个undo log的序号是递增的,那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了。
undo log是如何回滚的?
以上面的例子来说,假设执行rollback,那么对应的流程应该是这样:
- 通过undo no=3的日志把id=2的数据删除
- 通过undo no=2的日志把id=1的数据的deletemark还原成0
- 通过undo no=1的日志把id=1的数据的name还原成Tom
- 通过undo no=0的日志把id=1的数据删除
undo log存在什么地方?
InnoDB对undo log的管理采用段的方式,也就是回滚段,每个回滚段记录了1024个undo log segment,InnoDB引擎默认支持128个回滚段
mysql> show variables like 'innodb_undo_logs'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_undo_logs | 128 | +------------------+-------+
那么能支持的最大并发事务就是128*1024。每个undo log segment就像维护一个有1024个元素的数组。
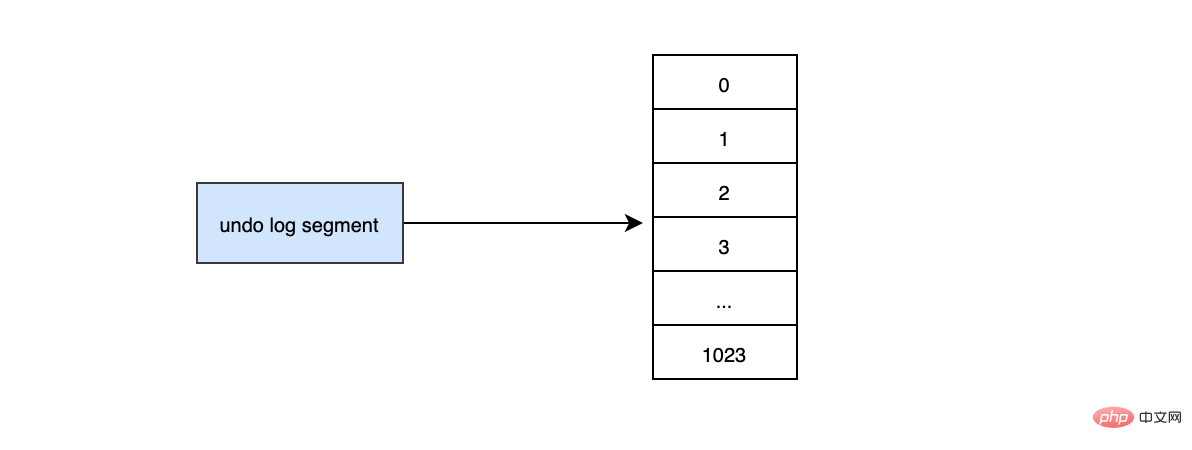
当我们开启个事务需要写undo log的时候,就得先去undo log segment中去找到一个空闲的位置,当有空位的时候,就会去申请undo页,最后会在这个申请到的undo页中进行undo log的写入。我们知道mysql默认一页的大小是16k。
mysql> show variables like '%innodb_page_size%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+
那么为一个事务就分配一个页,其实是非常浪费的(除非你的事物非常长),假设你的应用的TPS为1000,那么1s就需要1000个页,大概需要16M的存储,1分钟大概需要1G的存储...,如果照这样下去除非mysql清理的非常勤快,否则随着时间的推移,磁盘空间会增长的非常快,而且很多空间都是浪费的。
于是undo页就被设计的可以重用了,当事务提交时,并不会立刻删除undo页,因为重用,这个undo页它可能不干净了,所以这个undo页可能混杂着其他事务的undo log。undo log在commit后,会被放到一个链表中,然后判断undo页的使用空间是否小于3/4,如果小于3/4的话,则表示当前的undo页可以被重用,那么它就不会被回收,其他事务的undo log可以记录在当前undo页的后面。由于undo log是离散的,所以清理对应的磁盘空间时,效率不是那么高。
推荐学习:mysql视频教程
The above is the detailed content of After reading, understand MySQL persistence and rollback (detailed explanation with pictures and text). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 How to build a SQL database
Apr 09, 2025 pm 04:24 PM
How to build a SQL database
Apr 09, 2025 pm 04:24 PM
Building an SQL database involves 10 steps: selecting DBMS; installing DBMS; creating a database; creating a table; inserting data; retrieving data; updating data; deleting data; managing users; backing up the database.
