
 Database
Redis
What should we pay attention to when implementing distributed locks in Redis? [Summary of precautions]
Database
Redis
What should we pay attention to when implementing distributed locks in Redis? [Summary of precautions]
What should we pay attention to when implementing distributed locks in Redis? [Summary of precautions]

What should we pay attention to when implementing distributed locks in Redis? The following article will summarize and share with you some points to note when using Redis as a distributed lock. I hope it will be helpful to you!
![What should we pay attention to when implementing distributed locks in Redis? [Summary of precautions]](https://img.php.cn/upload/article/000/000/024/6221cc063d305288.jpg)
Redis implements distributed locks
I recently saw an article while reading distributed locks Good article, specially processed for my own understanding:
Three core elements of Redis distributed lock implementation:
1. Locking
The easiest way is to use the setnx command. The key is the unique identifier of the lock, which is named according to the business. The value is the thread ID of the current thread. [Related recommendations: Redis Video Tutorial]
For example, if you want to lock the flash sale activity of a product, you can name the key "lock_sale_ID". And what is the value set to? We can temporarily set it to 1. The pseudo code for locking is as follows:
setnx(key, 1)When a thread executes setnx and returns 1, it means that the key does not originally exist and the thread successfully obtained it. Lock, when other threads execute setnx and return 0, it means that the key already exists and the thread failed to grab the lock.
2. Unlock
If you want to lock, you must unlock. When the thread that obtained the lock completes its task, it needs to release the lock so that other threads can enter. The simplest way to release the lock is to execute the del instruction. The pseudo code is as follows:
del(key)After releasing the lock, other threads You can continue to execute the setnx command to obtain the lock.
3. Lock timeout
What does lock timeout mean? If a thread that obtains the lock dies while executing the task and has no time to explicitly release the lock, the resource will be locked forever, and other threads will never be able to come in again.
Therefore, the key of setnx must set a timeout period to ensure that even if it is not explicitly released, the lock will be automatically released after a certain period of time. setnx does not support timeout parameters, so additional instructions are needed. The pseudo code is as follows:
expire(key, 30)Taken together, the third step of our distributed lock implementation The first version of the pseudo code is as follows:
if(setnx(key,1) == 1){
expire(key,30)
try {
do something ......
}catch() { } finally {
del(key)
}
}Because there are three fatal problems in the above pseudo code:
1. The non-atomicity of setnx and expire
Imagine an extreme scenario. When a thread executes setnx, it successfully obtains the lock:
setnx has just been successfully executed, and before it has time to execute the expire command, node 1 Duang hangs up. Lost.
if(setnx(key,1) == 1){ //此处挂掉了.....
expire(key,30)
try {
do something ......
}catch()
{
}
finally {
del(key)
}
}In this way, the lock does not have an expiration time set and becomes "immortal", and other threads can no longer obtain the lock.
How to solve it? The setnx instruction itself does not support the incoming timeout period. Redis 2.6.12 or above adds optional parameters to the set instruction. The pseudo code is as follows: set (key, 1, 30, NX), so that Can replace setnx instruction .
2. Using del after the timeout results in accidentally deleting the locks of other threads
Another extreme scenario, if a thread successfully obtains the lock, and the timeout is set to 30 seconds.
If for some reason thread A executes very slowly and has not finished executing after 30 seconds, the lock will be automatically released upon expiration and thread B will obtain the lock.
Subsequently, thread A completes the task, and thread A then executes the del instruction to release the lock. But at this time, thread B has not finished executing. Thread A actually deletes the lock added by thread B.
How to avoid this situation? You can make a judgment before del releases the lock to verify whether the current lock is a lock added by yourself.
As for the specific implementation, you can use the current thread ID as the value when locking, and verify whether the value corresponding to the key is the ID of your own thread before deleting it.
加锁:
String threadId = Thread.currentThread().getId()
set(key,threadId ,30,NX)
doSomething.....
解锁:
if(threadId .equals(redisClient.get(key))){
del(key)
}However, doing so implies a new problem, if judgment and lock release are two independent operations, not atomic.
We are all programmers who pursue the ultimate, so this part must be implemented using Lua script:
String luaScript = 'if redis .call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end' ;
##redisClient.eval(luaScript , Collections.singletonList(key) , Collections.singletonList(threadId));
In this way, the verification and deletion process is an atomic operation.3. Possibility of concurrency
还是刚才第二点所描述的场景,虽然我们避免了线程A误删掉key的情况,但是同一时间有A,B两个线程在访问代码块,仍然是不完美的。
怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。
当过去了29秒,线程A还没执行完,这时候守护线程会执行expire指令,为这把锁“续命”20秒。守护线程从第29秒开始执行,每20秒执行一次。
当线程A执行完任务,会显式关掉守护线程。
另一种情况,如果节点1 忽然断电,由于线程A和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。
memcache实现分布式锁
首页top 10, 由数据库加载到memcache缓存n分钟
微博中名人的content cache, 一旦不存在会大量请求不能命中并加载数据库
需要执行多个IO操作生成的数据存在cache中, 比如查询db多次
问题
在大并发的场合,当cache失效时,大量并发同时取不到cache,会同一瞬间去访问db并回设cache,可能会给系统带来潜在的超负荷风险。我们曾经在线上系统出现过类似故障。
解决方法
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}在load db之前先add一个mutex key, mutex key add成功之后再去做加载db, 如果add失败则sleep之后重试读取原cache数据。为了防止死锁,mutex key也需要设置过期时间。伪代码如下
Zookeeper实现分布式缓存
Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
Znode分为四种类型:
- 1.
持久节点(PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
- 2.
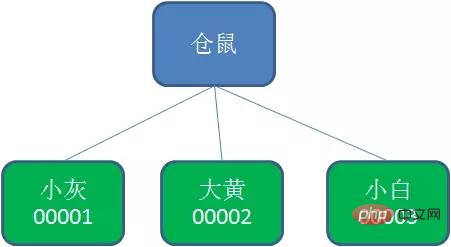
持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
- 3.
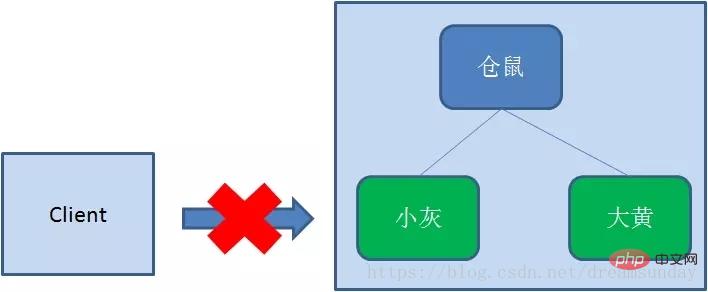
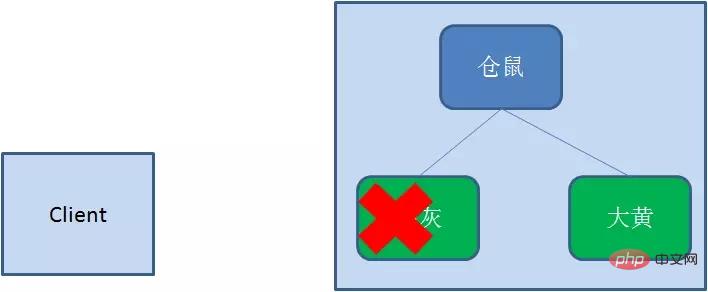
临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除:

- 4.
临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
- 获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
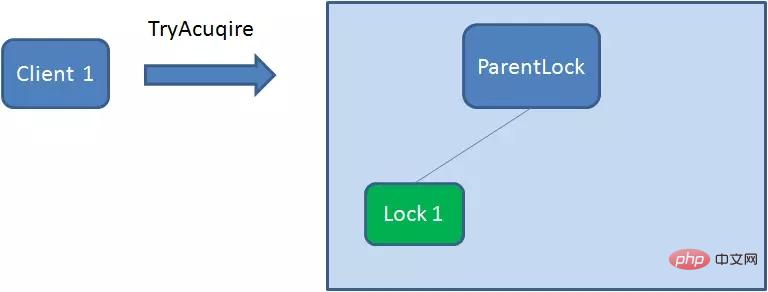
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
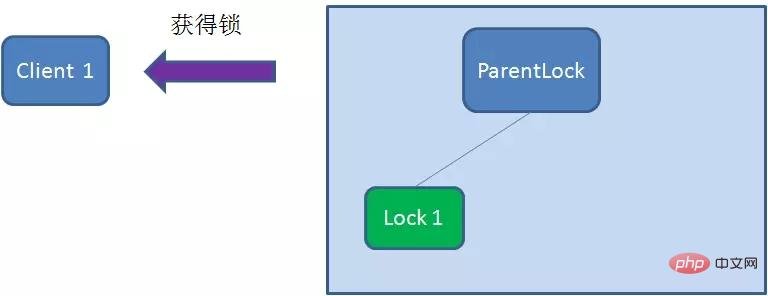
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
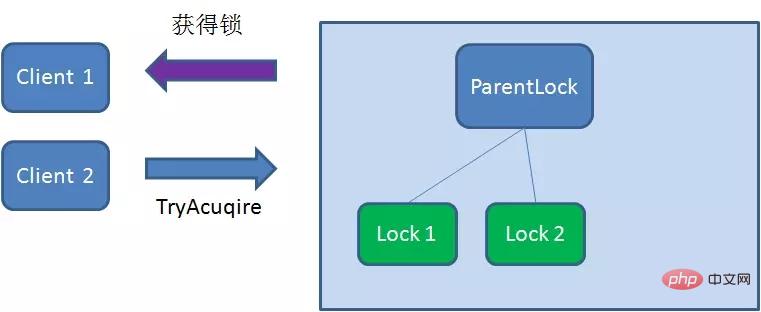
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
So, Client2 registers Watcher with the node ranked only higher than it Lock1 for monitoring Lock1 Whether the node exists. This means that Client2 failed to grab the lock and entered the waiting state.

At this time, if another client Client3 comes to acquire the lock, download and create a temporary one in ParentLock Sequence Node Lock3.
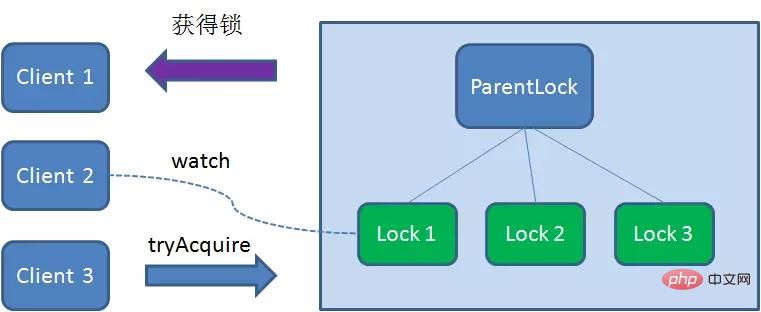
Client3Find all the temporary sequence nodes below ParentLock and sort them to determine the node you created Lock3# Is ## the first one in the order? It turns out that node Lock3 is not the smallest.
Client3 registers Watcher with the node Lock2 that is ranked only higher than it, for monitoring Lock2 Whether the node exists. This means that Client3 also failed to grab the lock and entered the waiting state.
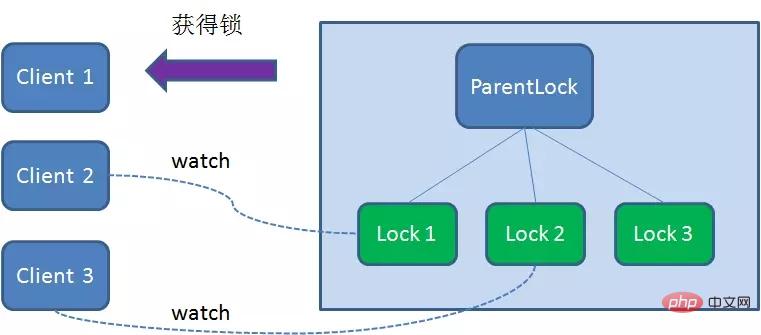
Client1 gets the lock, Client2 monitors Lock1, Client3 listened to Lock2. This just forms a waiting queue, much like the AQS (AbstractQueuedSynchronizer) that ReentrantLock relies on in Java.


- Release lock
Client1 will display the instruction to call the delete node Lock1.

Client1During the task execution, if Duang’s A crash will disconnect the Zookeeper server. According to the characteristics of the temporary node, the associated node Lock1 will be automatically deleted.

Client2 has been monitoring the existence status of Lock1, when the Lock1 node is deleted,Client2 will be notified immediately. At this time, Client2 will query all nodes under ParentLock again to confirm whether the node Lock2 created by itself is the current smallest node. If it is the smallest, then Client2 naturally obtains the lock.
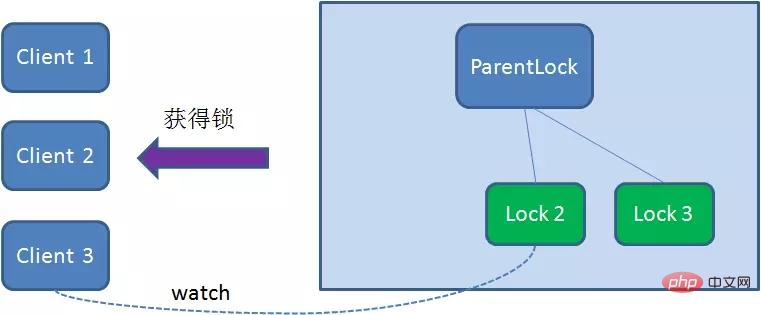
Client2 also deletes node Lock2 due to task completion or node crash, then Cient3 will be notified.

Client3 successfully obtained the lock.


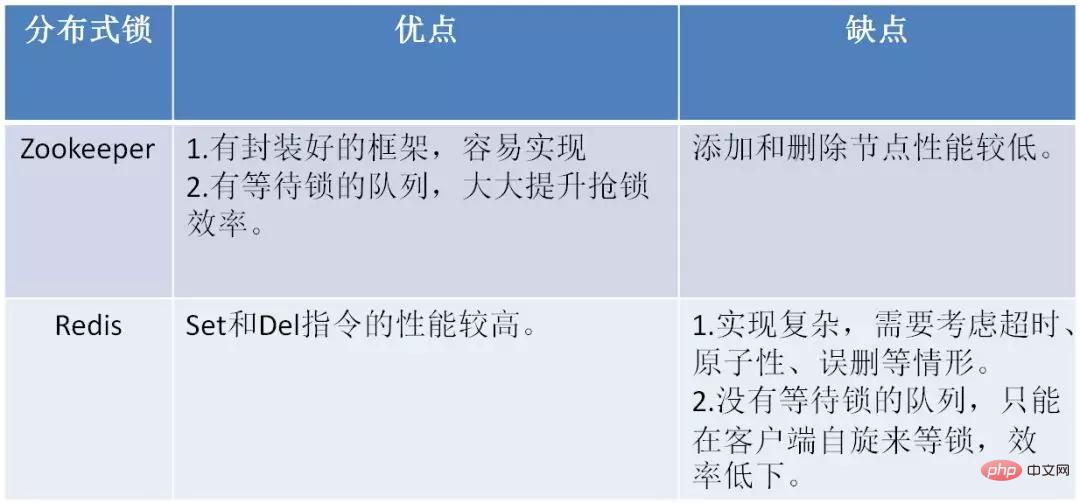
 ##For more programming-related knowledge, please visit:
##For more programming-related knowledge, please visit:
The above is the detailed content of What should we pay attention to when implementing distributed locks in Redis? [Summary of precautions]. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
