
 Backend Development
Python Tutorial
Python data outlier detection and processing (detailed examples)
Backend Development
Python Tutorial
Python data outlier detection and processing (detailed examples)
Python data outlier detection and processing (detailed examples)

This article brings you relevant knowledge about python, which mainly introduces the issues related to outliers in data analysis. Generally, the detection methods for outliers include statistical methods and cluster-based methods. Class methods, as well as some methods that specialize in detecting outliers, etc. These methods are introduced below. I hope they will be helpful to everyone.

Recommended learning: python learning tutorial
1 What is an outlier?
In machine learning, Anomaly detection and processing is a relatively small branch, or a by-product of machine learning, because in general prediction problems, The model is usually an expression of the data structure of the overall sample. This expression usually captures the general properties of the overall sample, and those points that are completely inconsistent with the overall sample in terms of these properties are called Abnormal points, usually abnormal points are not welcomed by developers in prediction problems, because prediction problems usually focus on the properties of the overall sample, and the generation mechanism of abnormal points is completely inconsistent with the overall sample. If the algorithm detects abnormalities If the model is point sensitive, the generated model cannot express the overall sample well, and the prediction will be inaccurate. On the other hand, abnormal points are of great interest to analysts in certain scenarios, such as disease prediction. Usually the physical indicators of healthy people are similar in some dimensions. If a person If there are abnormalities in his physical indicators, then his physical condition must have changed in some aspects. Of course, this change is not necessarily caused by the disease (often called noise points), but the occurrence and detection of abnormalities are disease predictions. An important starting point. Similar scenarios can also be applied to credit fraud, cyber attacks, etc.
2 Detection methods for outliers
Generally, the detection methods for outliers include statistical methods, clustering-based methods, and some methods that specialize in detecting outliers. These are discussed below. Methods are introduced accordingly.
1. Simple Statistics
If you use pandas, we can directly use describe() to observe the statistical description of the data (only a rough Observe some statistics), but the statistical data are continuous, as follows:
df.describe()

Or simply use a scatter plot to clearly observe the existence of outliers. As shown below:

2. 3∂ principle
This principle has a condition: The data needs to obey the normal distribution. Under the 3∂ principle, if an outlier exceeds 3 times the standard deviation, it can be regarded as an outlier. The probability of positive or negative 3∂ is 99.7%, so the probability of a value other than 3∂ from the average value appearing is P(|x-u| > 3∂) <= 0.003, which is a very rare and small probability event. If the data does not follow a normal distribution, it can also be described by how many times the standard deviation is away from the mean.

The red arrow points to the outlier.
3. Box plot
This method uses the interquartile range (IQR) of the box plot to detect outliers, also called Tukey's test. The definition of a box plot is as follows:

The interquartile range (IQR) is the difference between the upper quartile and the lower quartile. We use 1.5 times the IQR as the standard and stipulate that points exceeding the upper quartile 1.5 times the IQR distance, or the lower quartile -1.5 times the IQR distance are outliers. The following is the code implementation in Python, mainly using the percentile method of numpy.
Percentile = np.percentile(df['length'],[0,25,50,75,100]) IQR = Percentile[3] - Percentile[1] UpLimit = Percentile[3]+ageIQR*1.5 DownLimit = Percentile[1]-ageIQR*1.5
You can also use the visualization method boxplot of seaborn to achieve:
f,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y='length',data=df,ax=ax) plt.show()
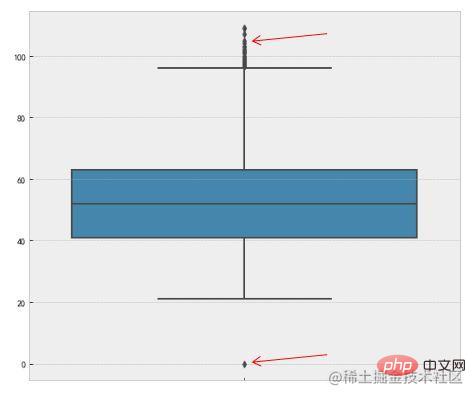
The red arrow points to It's an outlier.
The above is a simple method commonly used to determine outliers. Let's introduce some more complex outlier detection algorithms. Since it involves a lot of content, only the core ideas will be introduced. Interested friends can study in depth on their own.
4. Based on model detection
This method generally builds a probability distribution model, and calculates the probability that the object conforms to the model, and treats objects with low probability as as an outlier. If the model is a collection of clusters, anomalies are objects that do not significantly belong to any cluster; if the model is regression, anomalies are objects that are relatively far from the predicted value.
Probability definition of outliers: An outlier is an object, with respect to the probability distribution model of the data, which has a low probability. The prerequisite for this situation is to know what distribution the data set obeys. If the estimation is wrong, it will cause a heavy-tailed distribution.
For example, the RobustScaler method in feature engineering, when scaling data feature values, it will use the quantile distribution of data features to divide the data into multiple segments according to the quantile, and only take the middle Segment is used for scaling, for example, only data from the 25% quantile to the 75% quantile is used for scaling. This reduces the impact of abnormal data.
Advantages and Disadvantages: (1) With a solid theoretical foundation in statistics, these tests can be very effective when there is sufficient data and knowledge of the type of test used; (2) For For multivariate data, fewer options are available, and for high-dimensional data, these detection possibilities are poor.
5. Outlier detection based on proximity
Statistical methods use the distribution of data to observe outliers. Some methods even require some distribution conditions, but in practice the distribution of data is very It is difficult to meet some assumptions and has certain limitations in use.
It is easier to determine a meaningful measure of proximity for a data set than to determine its statistical distribution. This method is more general and easier to use than statistical methods because an object's outlier score is given by the distance to its k-nearest neighbors (KNN).
It should be noted that the outlier score is highly sensitive to the value of k. If k is too small, a small number of nearby outliers may result in a low outlier score; if K is too large, all objects in clusters with less than k points may become outliers. In order to make this scheme more robust to the selection of k, the average distance of the k nearest neighbors can be used.
Advantages and disadvantages: (1) Simple; (2) Disadvantages: The proximity-based method requires O(m2) time and is not suitable for large data sets; (3) The The method is also sensitive to the choice of parameters; (4) it cannot handle data sets with regions of different densities, because it uses a global threshold and cannot account for such changes in density.
5. Density-based outlier detection
From a density-based perspective, outliers are objects in low-density areas. Density-based outlier detection is closely related to proximity-based outlier detection, since density is often defined in terms of proximity. A common way to define density is to define density as the reciprocal of the average distance to the k nearest neighbors. If this distance is small, the density is high and vice versa. Another density definition is The density definition used by the DBSCAN clustering algorithm, that is, the density around an object is equal to the number of objects within a specified distance d from the object.
Advantages and Disadvantages: (1) It gives a quantitative measure that the object is an outlier, and it can be processed well even if the data has different areas; (2) Like distance-based methods, these methods necessarily have a time complexity of O(m2). For low-dimensional data, using specific data structures can achieve O(mlogm); (3) Parameter selection is difficult. Although the LOF algorithm handles this problem by observing different k values and then obtaining the maximum outlier score, it is still necessary to choose upper and lower bounds for these values.
6. Clustering-based method for outlier detection
Clustering-based outliers:An object is an outlier based on clustering. If the object does not Strongly belongs to any cluster, then the object belongs to an outlier.
The impact of outliers on initial clustering: If outliers are detected through clustering, there is a question since the outliers affect clustering: whether the structure is valid. This is also the shortcoming of the k-means algorithm, which is sensitive to outliers. In order to deal with this problem, you can use the following methods: cluster objects, delete outliers, and cluster objects again (this does not guarantee optimal results).
Advantages and Disadvantages: (1) Clustering techniques based on linear and near-linear complexity (k-means) may be highly effective in discovering outliers; (2) Definition of clusters It is usually the complement of outliers, so clusters and outliers may be discovered at the same time; (3) the resulting outlier sets and their scores may be very dependent on the number of clusters used and the existence of outliers in the data; (4) The quality of the clusters generated by the clustering algorithm has a great impact on the quality of the outliers generated by the algorithm.
7. Specialized outlier detection
In fact, the original intention of the clustering method mentioned above is unsupervised classification, not to find outliers, but it just happens that its function can The detection of outliers is a derived function.
In addition to the methods mentioned above, there are two more commonly used methods specifically used to detect abnormal points: One Class SVM and Isolation Forest, the details are not available Do in-depth research.
3 How to handle outliers
We have detected outliers and we need to handle them to a certain extent. The general methods of handling outliers can be roughly divided into the following categories:
- Delete records containing abnormal values: Delete records containing abnormal values directly;
- Treat as missing values: Treat abnormal values as Missing values are processed using the missing value processing method;
- Mean value correction: The outlier can be corrected with the average of the two observed values before and after;
- No processing: Conduct data mining directly on the data set with outliers;
Whether outliers should be deleted can be considered based on the actual situation. Because some models are not very sensitive to outliers, even if there are outliers, the model effect will not be affected. However, some models such as logistic regression LR are very sensitive to outliers. If not processed, very poor effects such as overfitting may occur.
4 Summary of outliers
The above is a summary of outlier detection and processing methods.
We can find outliers through some detection methods, but the results obtained are not absolutely correct. The specific situation needs to be judged based on the understanding of the business. Similarly, how to deal with outliers, whether they should be deleted, corrected, or not processed, also needs to be considered based on the actual situation and is not fixed.
Recommended learning: python tutorial
The above is the detailed content of Python data outlier detection and processing (detailed examples). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang is more suitable for high concurrency tasks, while Python has more advantages in flexibility. 1.Golang efficiently handles concurrency through goroutine and channel. 2. Python relies on threading and asyncio, which is affected by GIL, but provides multiple concurrency methods. The choice should be based on specific needs.
