
This article brings you relevant knowledge about Redis Tutorial, which mainly introduces issues related to the implementation of Redis's LRU cache elimination algorithm. LRU will use a linked list to maintain each data in the cache. access status, and adjust the position of the data in the linked list based on the real-time access to the data. I hope it will be helpful to everyone.

Recommended learning: Redis learning tutorial
LRU, Least Recently Used (Least Recently Used, LRU), classic caching algorithm.
LRU will use a linked list to maintain the access status of each data in the cache, and adjust the position of the data in the linked list based on the real-time access of the data, and then use the position of the data in the linked list to indicate that the data was recently Visited, or haven’t visited for a while.
LRU will set the head and tail of the chain to the MRU end and LRU end respectively:
LRU can be divided into the following situations:
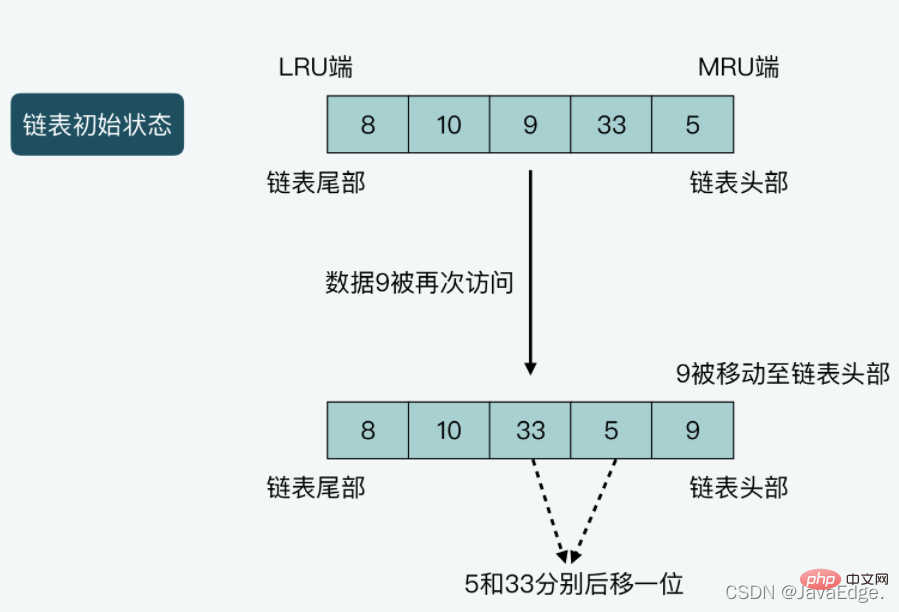
Illustration of case 2: The length of the linked list is 5, and the data saved from the head to the tail of the linked list are 5, 33, and 9 respectively. ,10,8. Assume that data 9 is accessed once, then 9 will be moved to the head of the linked list, and at the same time, data 5 and 33 will both be moved one position to the end of the linked list.
So if it is implemented strictly according to LRU, assuming that Redis saves a lot of data, it needs to be implemented in the code:
is When Redis uses the maximum memory, it maintains a linked list for all the data that can be accommodated
Additional memory space is required to save the linked list
Whenever new data is inserted or existing data is deleted To access again, you need to perform multiple linked list operations
In the process of accessing data, Redis is affected by the overhead of data movement and linked list operations
Ultimately leading to reduced Redis access performance.
So, whether it is to save memory or maintain Redis high performance, Redis is not implemented strictly according to the basic principles of LRU, but provides an approximate LRU algorithm implementation.
How does Redis's memory elimination mechanism enable the approximate LRU algorithm? The following configuration parameters in redis.conf:
maxmemory, set the maximum memory capacity that the Redis server can use. Once the actual memory used by the server exceeds the threshold, The server will perform the memory elimination operation
maxmemory-policy according to the maxmemory-policy configuration policy, and set the Redis server memory elimination policy, including approximate LRU, LFU, and TTL value elimination and random elimination, etc.

So, once the maxmemory option is set, and maxmemory-policy is configured as allkeys-lru or volatile-lru , approximate LRU is enabled. Both allkeys-lru and volatile-lru will use approximate LRU to eliminate data. The difference is:
How does Redis implement the approximate LRU algorithm?
Calculation of the global LRU clock value
How to calculate the global LRU clock value to determine the timeliness of data access
Initialization and update of LRU clock value of key-value pair
Which functions initialize and update the LRU clock value corresponding to each key-value pair?
The actual execution of the approximate LRU algorithm
How to execute the approximate LRU algorithm, that is, when data elimination is triggered, and the implementation of the actual elimination mechanism
The approximate LRU algorithm still needs to distinguish the access timeliness of different data, that is, Redis needs to know the latest access time of the data. Hence, the LRU clock: recording the timestamp of each access to data.
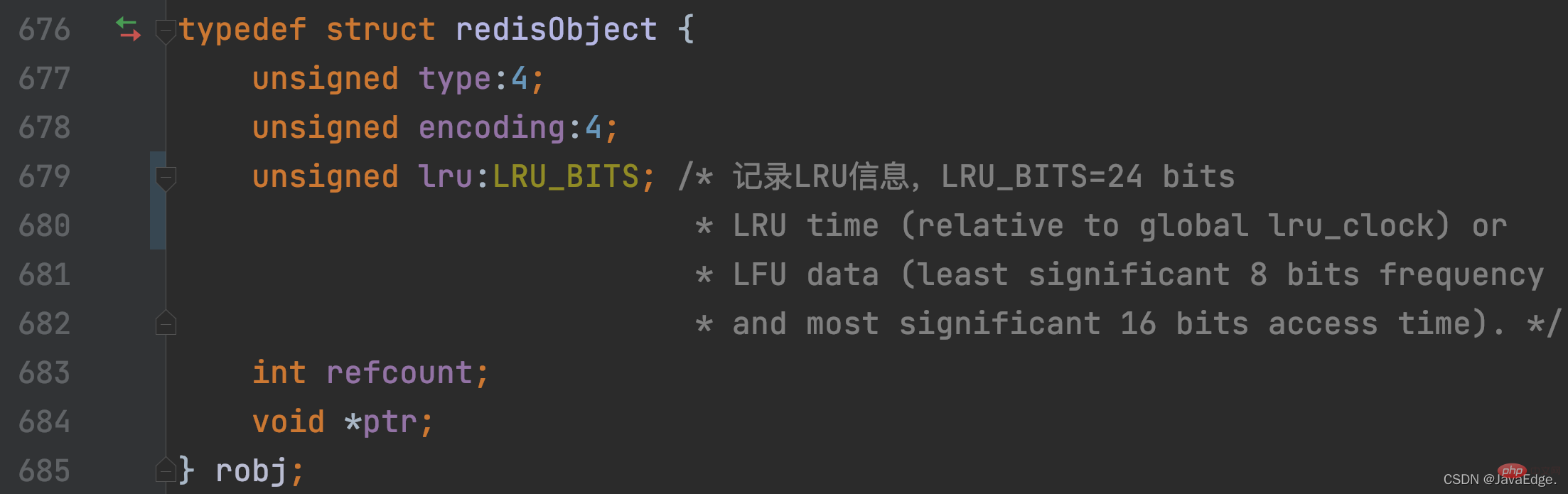
Redis will use a redisObject structure to save the pointer to V for each V in the KV pair. In addition to the pointer that records the value, redisObject also uses 24 bits to save the LRU clock information, which corresponds to the lru member variable. In this way, each KV pair will record its last accessed timestamp in the lru variable.
The redisObject definition contains the definition of lru member variables:
How is the LRU clock value of each KV pair calculated? Redis Server uses an instance-level global LRU clock, and the LRU time of each KV pair is set according to the global LRU clock.
This global LRU clock is stored in the member variable of the Redis global variable serverlruclock

When the Redis Server starts, call initServerConfig to initialize When setting various parameters, getLRUClock will be called to set the value of lruclock:

So, you have to pay attention, **If the time interval between two accesses to a data is
The getLRUClock function divides the UNIX timestamp obtained by LRU_CLOCK_RESOLUTION to obtain the UNIX timestamp calculated with LRU clock precision, which is the current LRU clock value.
getLRUClock will do an AND operation between the LRU clock value and the macro definition LRU_CLOCK_MAX (the maximum value that the LRU clock can represent).

So by default, the global LRU clock value is a UNIX timestamp calculated with a precision of 1s, and is initialized in initServerConfig.
How is the global LRU clock value updated when Redis Server is running? It is related to the serverCron corresponding to the regularly running time event of Redis Server in the event-driven framework.
serverCron, as a callback function for time events, will be executed periodically. Its frequency value is determined by the hz configuration item of redis.conf. The default value is 10, that is, the serverCron function will execute every 100ms ( 1s/10 = 100ms) run once. In serverCron, the global LRU clock value will be updated regularly according to the execution frequency of this function by calling getLRUClock:

In this way, each KV pair can obtain the latest from the global LRU clock Access timestamp.
For each KV pair, in which functions is its corresponding redisObject.lru initialized and updated?
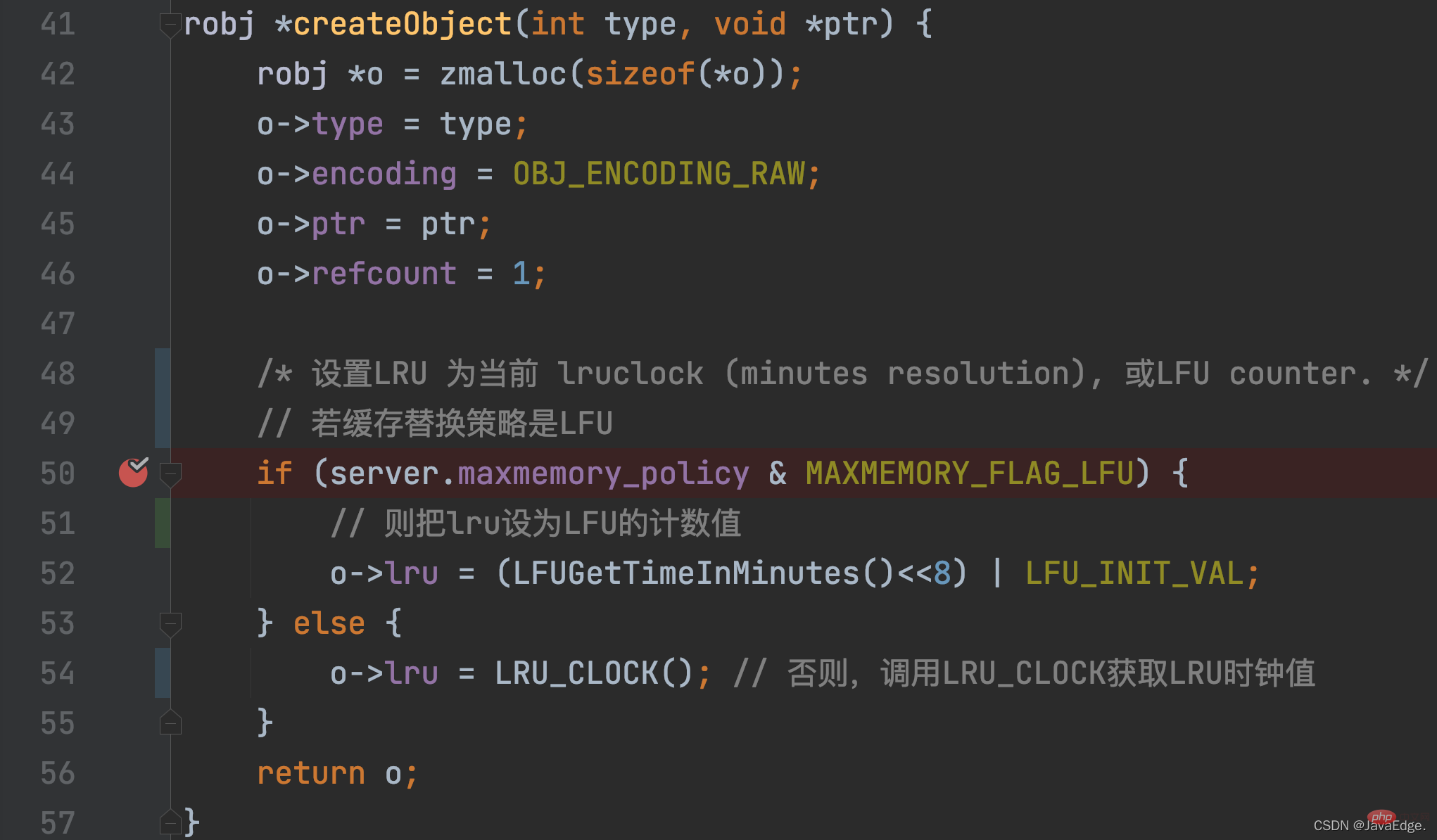
For a KV pair, the LRU clock value is initially set when the KV pair is created. This initialization operation Called in createObject function, this function will be called when Redis wants to create a KV pair.
In addition to allocating memory space to redisObject, createObject will also initialize redisObject.lru according to the maxmemory_policy configuration.
LRU_CLOCK returns the current global LRU clock value. Because once a KV pair is created, it is equivalent to an access, and its corresponding LRU clock value represents its access timestamp:
Which KV pair? When will the LRU clock value be updated again?
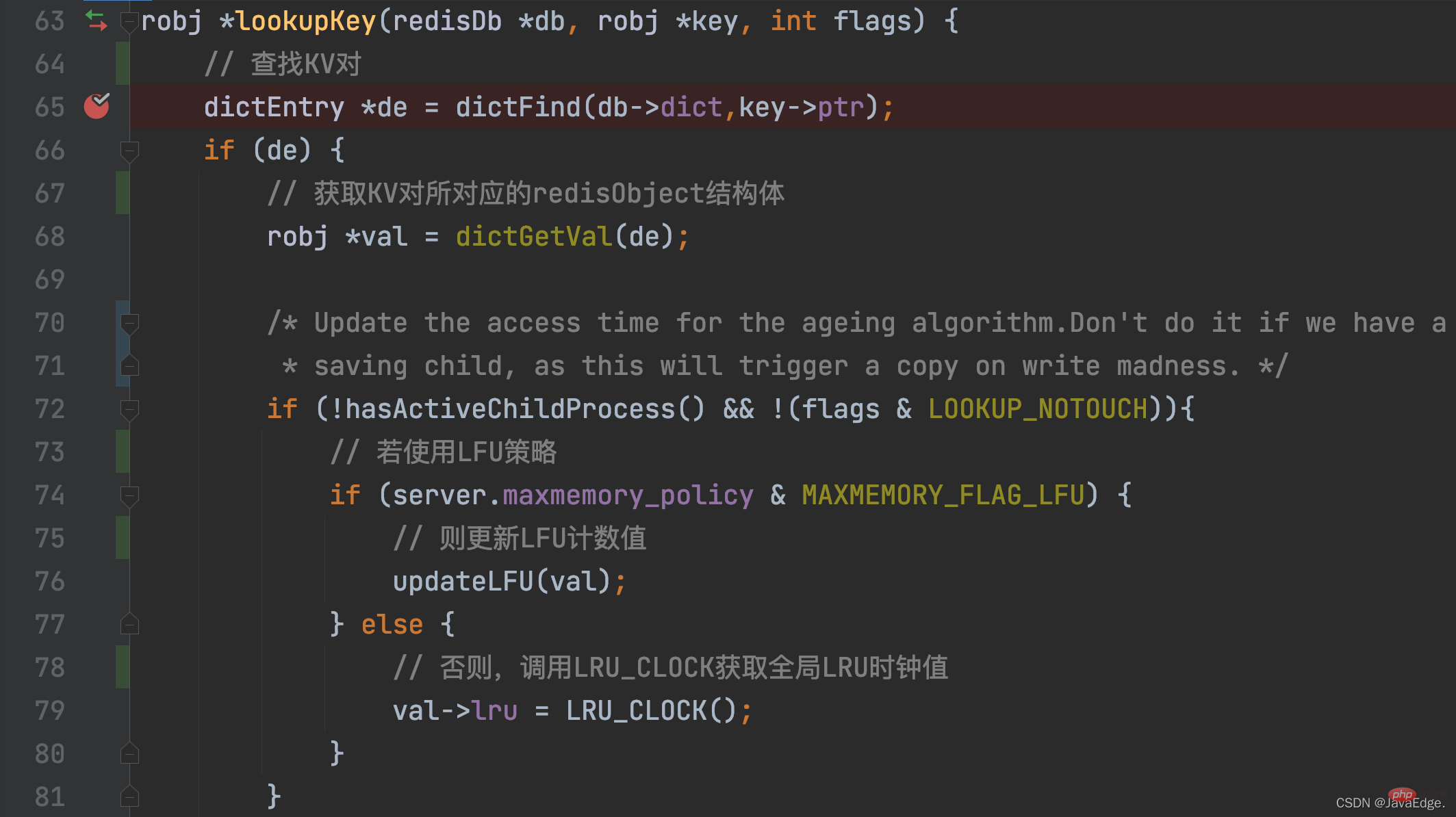
As long as a KV pair is accessed, its LRU clock value will be updated! When a KV pair is accessed, the access operation will eventually call lookupKey.
lookupKey will look up the KV pair to be accessed from the global hash table. If the KV pair exists, lookupKey will update the LRU clock value of the key-value pair, which is its access timestamp, based on the configuration value of maxmemory_policy.
When maxmemory_policy is not configured as an LFU policy, the lookupKey function will call the LRU_CLOCK function to obtain the current global LRU clock value and assign it to the lru variable in the redisObject structure of the key-value pair
In this way, once each KV pair is accessed, it can obtain the latest access timestamp. But you may be curious: How are these access timestamps ultimately used to approximate the LRU algorithm for data elimination?
The reason why Redis implements approximate LRU is to reduce the overhead of memory resources and operation time.
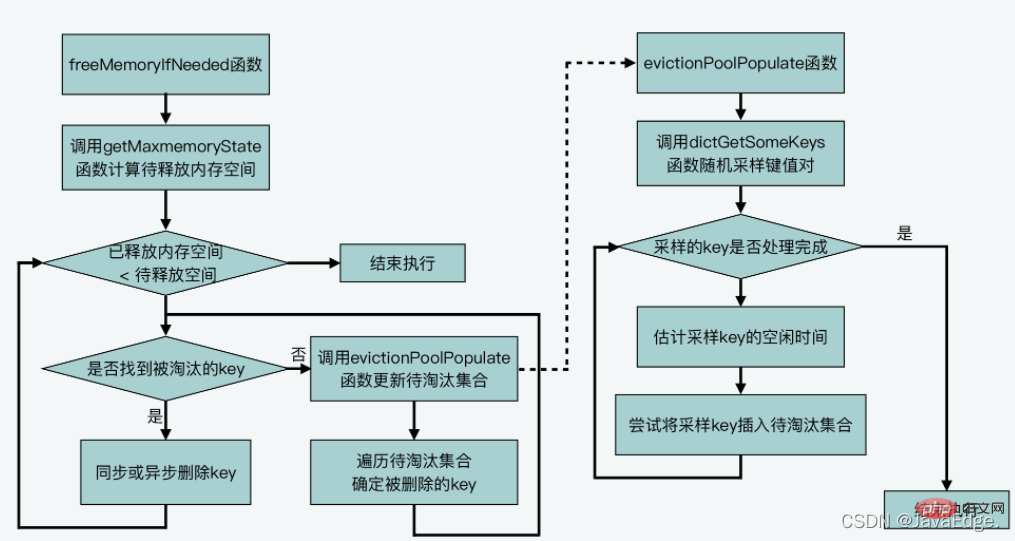
The main logic of approximate LRU is in performEvictions.
performEvictions is called by evictionTimeProc, and the evictionTimeProc function is called by processCommand.
processCommand, Redis will call when processing each command:
 Then, isSafeToPerformEvictions will again judge whether to continue executing performEvictions based on the following conditions:
Then, isSafeToPerformEvictions will again judge whether to continue executing performEvictions based on the following conditions:


Once performEvictions is called and maxmemory-policy is set to allkeys-lru or volatile-lru, approximate LRU execution is triggered.
The execution can be divided into the following steps:
Call getMaxmemoryState to evaluate the current Memory usage, determine whether the current memory capacity used by Redis Server exceeds the maxmemory configuration value.
If it does not exceed maxmemory, C_OK will be returned, and performEvictions will also be returned directly.

When getMaxmemoryState evaluates the current memory usage, if it is found that the used memory exceeds maxmemory, it will calculate the amount of memory that needs to be released. The size of this released memory = the amount of used memory - maxmemory.
But the amount of used memory does not include the copy buffer size used for master-slave replication, which is calculated by getMaxmemoryState by calling freeMemoryGetNotCountedMemory.
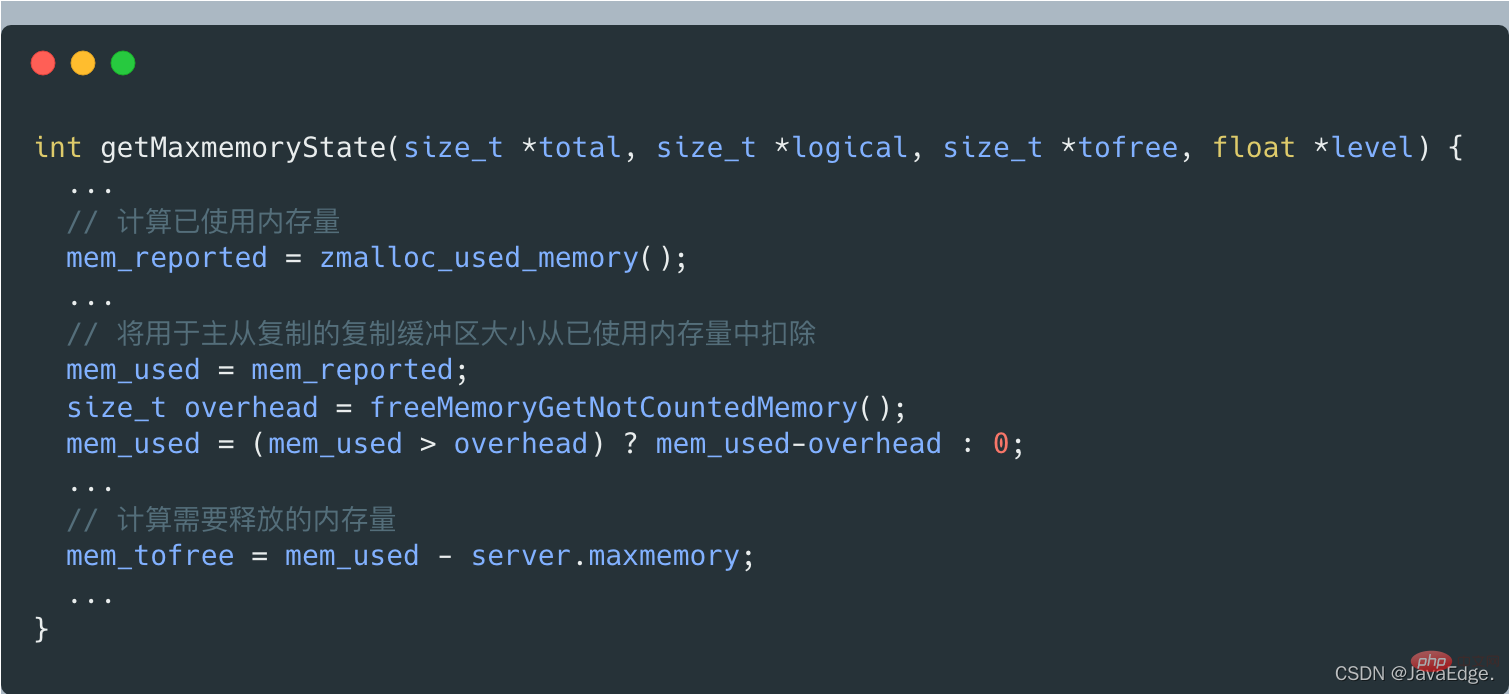
#If the amount of memory currently used by the Server exceeds the maxmemory upper limit, performEvictions will execute a while loop to eliminate data and release memory.
For elimination data, Redis defines the array EvictionPoolLRU to save the candidate KV pairs to be eliminated. The element type is the evictionPoolEntry structure, which saves the idle time idle, corresponding K and other information of the KV pairs to be eliminated:


In this way, when Redis Server executes initSever for initialization, it will call evictionPoolAlloc to allocate memory space for the EvictionPoolLRU array. The size of the array is determined by EVPOOL_SIZE. The default is Save 16 candidate KV pairs to be eliminated.
performEvictions In the cyclic process of eliminating data, the set of candidate KV pairs to be eliminated, that is, the EvictionPoolLRU array, will be updated.
performEvictions calls evictionPoolPopulate, which will first call dictGetSomeKeys to randomly obtain a certain number of K from the hash table to be sampled:
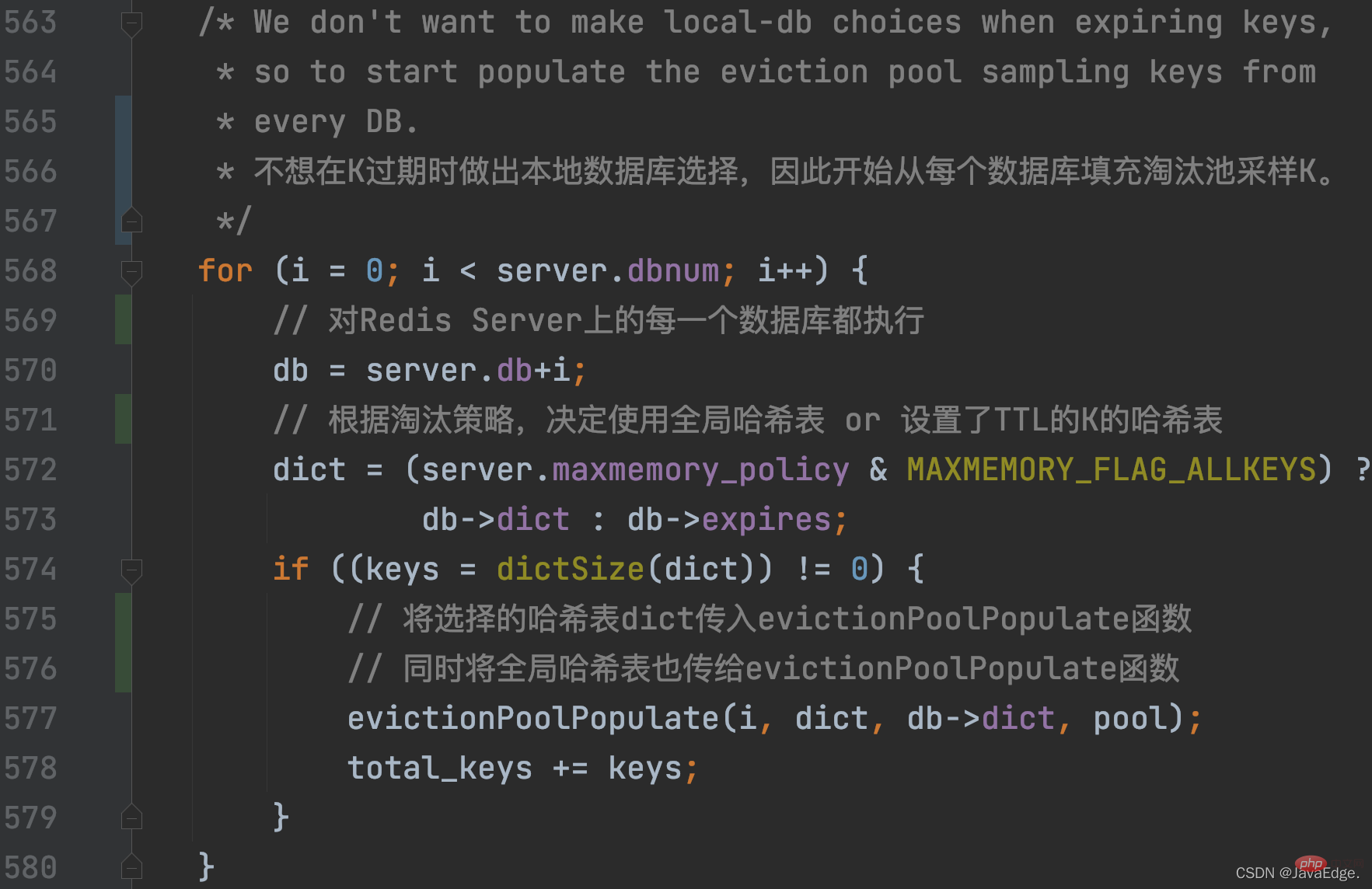

So, dictGetSomeKeys returns the sampled KV pair set. evictionPoolPopulate executes a loop based on the actual number of sampled KV pairs count: call estimateObjectIdleTime to calculate the idle time of each KV pair in the sampling set:
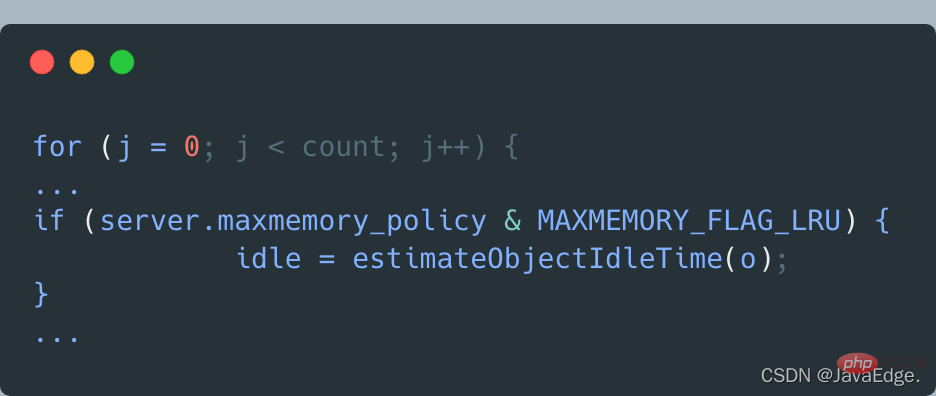
Then, evictionPoolPopulate traverses the waiting The set of eliminated candidate KV pairs, that is, the EvictionPoolLRU array, attempts to insert each sampled KV pair into the EvictionPoolLRU array, depending on one of the following conditions:
is established. After all sampled key-value pairs are processed, the evictionPoolPopulate function completes updating the set of candidate key-value pairs to be eliminated.
Next, performEvictions begins to select the KV pair that will eventually be eliminated.
Because evictionPoolPopulate has updated the EvictionPoolLRU array, and the Ks in the array are sorted from small to large in idle time. Therefore, performEvictions traverses the EvictionPoolLRU array once and starts selecting from the last K in the array. If the selected K is not empty, it will be used as the final K to be eliminated.
The execution logic of this process:
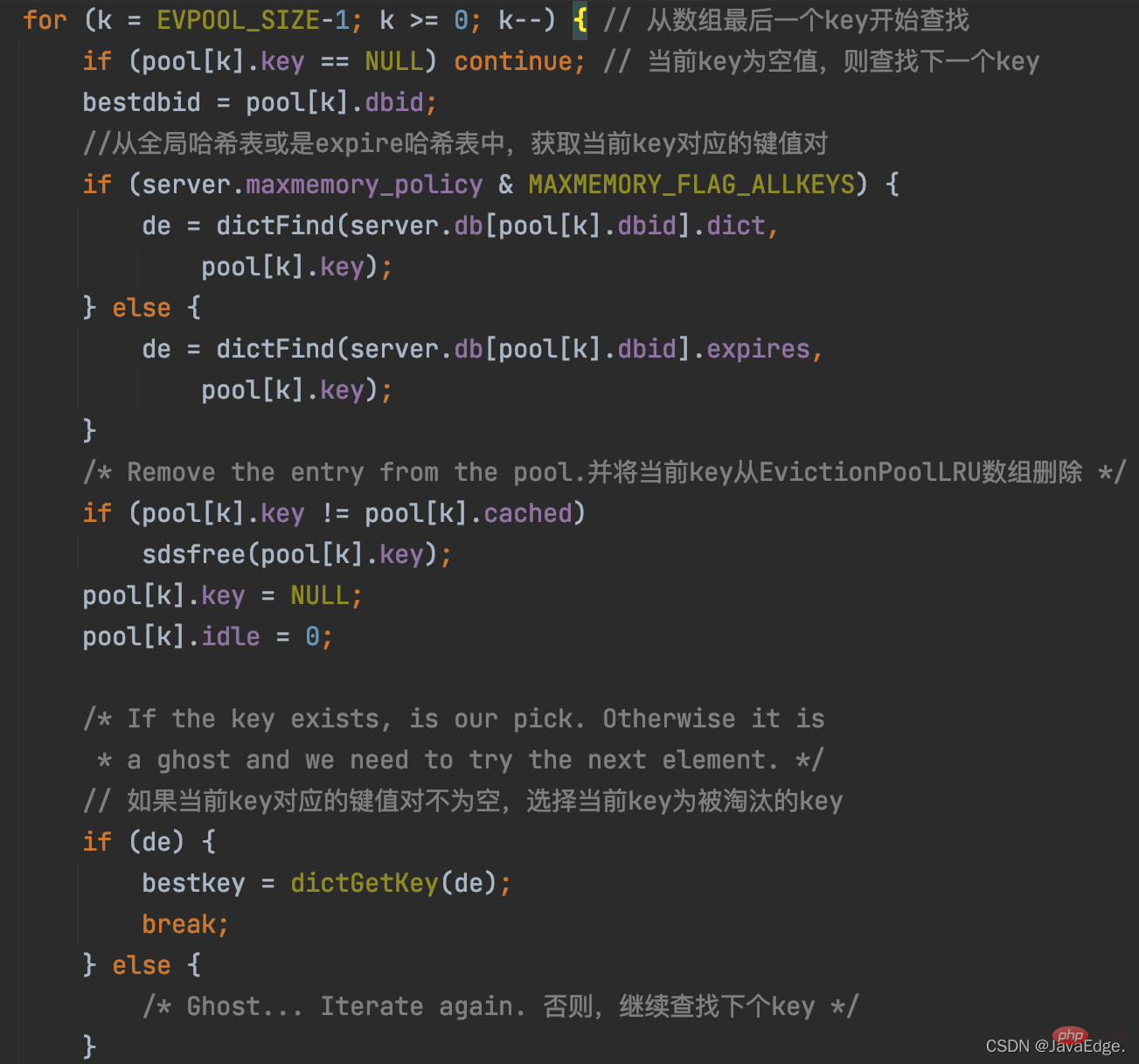
Once the eliminated K is selected, performEvictions will perform synchronous deletion or asynchronous deletion based on the lazy deletion configuration of the Redis server. Delete:
At this point, performEvictions has eliminated a K. If the memory space released at this time is not enough, that is, the space to be released is not reached, performEvictions will repeatedly executethe process of updating the set of candidate KV pairs to be eliminated and selecting the final KV pair until it is satisfied The size requirement of the space to be released.
performEvictions process:
The approximate LRU algorithm does not use a time-consuming and space-consuming linked list, but uses a fixed-size data set to be eliminated, and randomly selects some K to be added to the data set to be eliminated each time.
Finally, according to the length of idle time of K in the set to be eliminated, delete the K with the longest idle time.
According to the basic principles of the LRU algorithm, it is found that if the LRU algorithm is implemented strictly according to the basic principles, the developed system will need additional memory space to save the LRU linked list, and the system will also be affected by LRU when running. The overhead impact of linked list operations.
The memory resources and performance of Redis are very important, so Redis implements the approximate LRU algorithm:
Basic principles and algorithms of an algorithm There will be certain compromises in the actual implementation of the system development, and the resource and performance requirements of the developed system need to be comprehensively considered to avoid the resource and performance overhead caused by strictly following the algorithm implementation.
Recommended learning: Redis tutorial
The above is the detailed content of Briefly understand the implementation of Redis's LRU cache elimination algorithm. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis










![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



