

Let's analyze the solutions to Redis hot data problems together

This article brings you relevant knowledge about Redis, which mainly introduces the related issues about the Redis hot key large Value solution. Let’s take a look at it together. I hope it will be helpful to everyone. .

Recommended learning: Redis video tutorial
About Redis hot data & big key big value questions are also easy to ask high-level questions It is better to learn the problem at once and leave the interviewer speechless. In my personal work experience, hot data problems are more likely to be encountered at work than avalanches. However, most of the time, the hot spots are not hot enough and will be alerted and solved in advance. But once this problem cannot be controlled, the online problems caused will be enough to put your performance at the bottom this year. Let’s not talk nonsense and get to the point.
Under normal circumstances, data in the Redis cluster is evenly distributed to each node, and requests are evenly distributed to each shard. However, in some special scenarios, such as external crawlers, attacks, and hot products Wait, the most typical example is when a celebrity announces their divorce on Weibo, and people flood in to leave messages, causing the Weibo comment function to crash. In this short period of time, the number of visits to certain keys is too large, and requests will be made for the same keys. to the same data shard, resulting in a high load on the shard and becoming a bottleneck, leading to a series of problems such as avalanches.
1. Interviewer: Have you ever encountered Redis hot data problems in your project? What are the common causes?
Problem analysis: I was asked this question last time when I heard a big boss in the group interview Ali p7. The difficulty index is five stars. Wait for me. Being a noob is really a plus.
Answer: I have something to say about hot data. I have been aware of this problem since I first learned to use Redis, so when using it We will deliberately avoid and resolutely not dig holes for ourselves. The biggest problem with hotspot data will cause failures caused by unbalanced load in the Redis cluster (that is, data skew). These problems are fatal blows to the Redis cluster.
Let’s first talk about the main reasons for the Reids cluster load imbalance failure:
- Highly visited Key, that is, hot key, according to past maintenance If the QPS accessed by a key exceeds 1,000, you should pay close attention to it, such as popular products, hot topics, etc.
- Big Value, although the access QPS of some keys is not high, due to the large value, the network card load is large, the network card traffic is full, and a single machine may experience Gigabit/second , IO failure.
- Hot Key Big Value exists at the same time, server killer.
So what faults will be caused by hot keys or large Values:
- Data skew problem: Large Values will cause uneven data distribution on different nodes in the cluster, causing data skew problems , a large number of requests with a very high read-write ratio will fall on the same redis server, and the load of the redis will be seriously increased, making it easy to crash.
- QPS Skew: QPS is uneven across shards.
- A large Value will cause the Redis server buffer to be insufficient, resulting in get timeout.
- Because the Value is too large, the computer room network card has insufficient traffic.
- Redis cache failure leads to a chain reaction of database layer breakdown.
2. Interviewer: In real projects, how do you accurately locate hot data issues?
Answer: The solution to this problem is relatively broad. It depends on different business scenarios. For example, if a company organizes promotional activities, then there must be a way to count the products participating in the promotion in advance. , this scenario can pass the estimation method. For emergencies and uncertainties, Redis will monitor hotspot data by itself. To sum up:
-
How to know in advance:
Depending on the business, human flesh statistics or system statistics may become hot data, such as promotional products, hot topics, Holiday topics, anniversary activities, etc. -
Redis client collection method:
The caller counts the number of key requests by counting, but the number of keys cannot be predicted, and the code is highly intrusive.public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore }Copy after login -
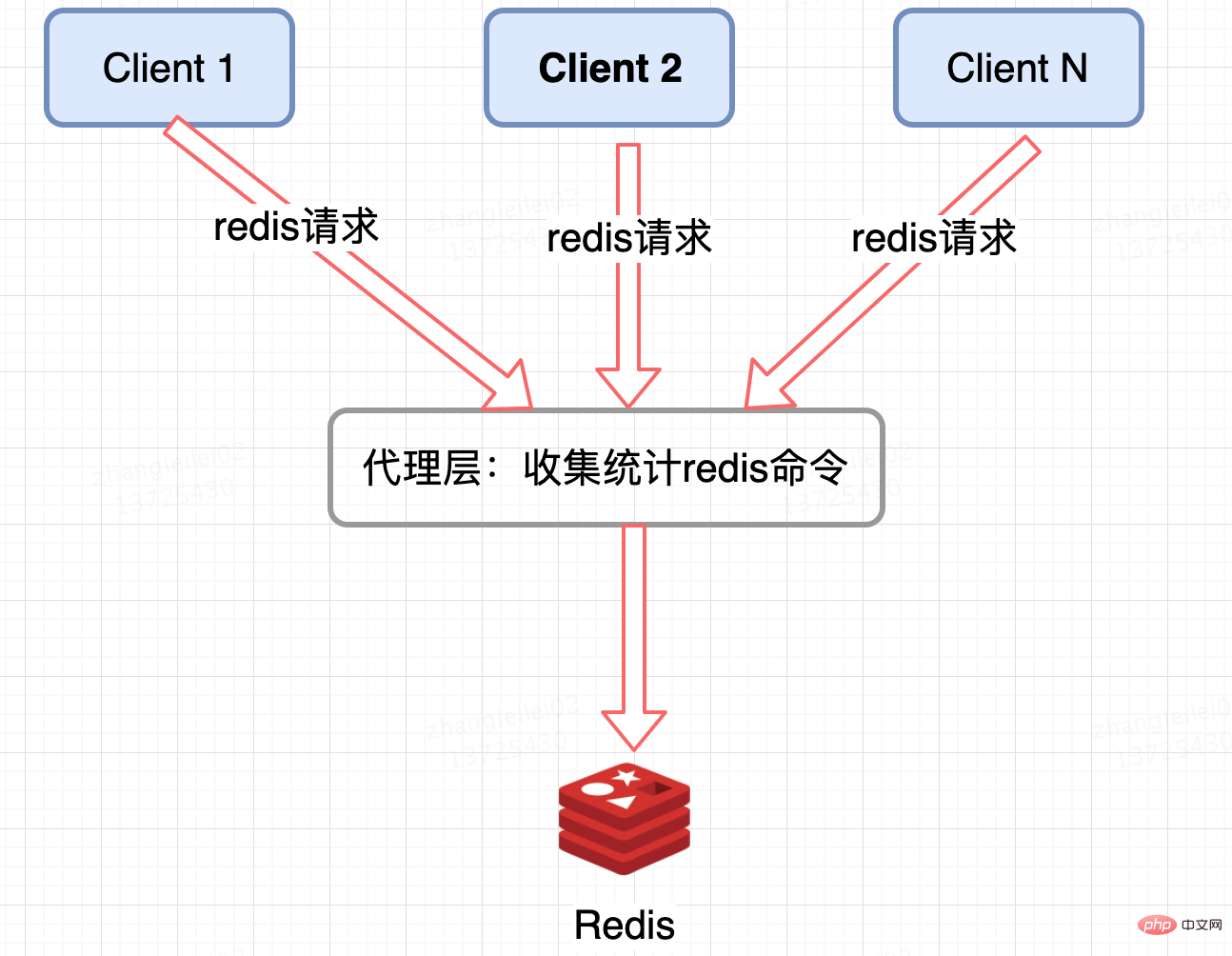
Redis cluster proxy layer statistics:
Agent-based Redis distributed architectures such as Twemproxy and codis have a unified entrance and can be collected and reported at the Proxy layer. But the disadvantage is obvious. Not all Redis cluster architectures have proxies.
-
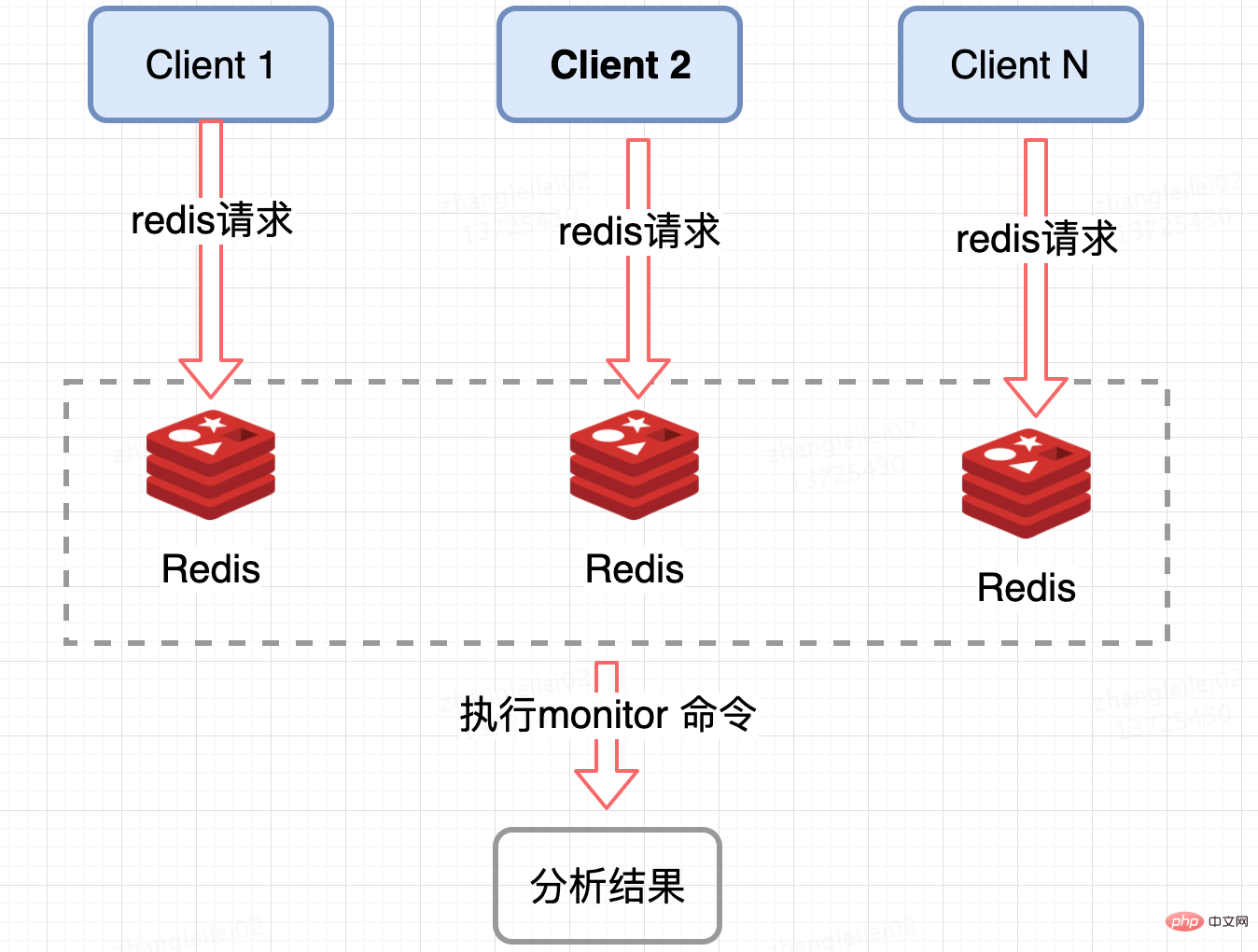
Redis server collection:
Monitor the QPS of a single Redis shard, and monitor the node where the QPS is tilted to a certain extent to obtain the hotspot key. Redis provides a monitor command, you can count all the commands on a certain Redis node within a period of time and analyze the hot key. Under high concurrency conditions, there will be hidden dangers of memory explosion and Redis performance, so this method is suitable for use in a short period of time; it is also only It can count the hotspot keys of a Redis node. For clusters, summary statistics are needed, which is a little troublesome from a business perspective.
The above four methods are commonly used in the industry. I have a new idea by studying the Redis source code. Type 5: Modify the Redis source code.
-
Modify the Redis source code: (Thinking of ideas from reading the source code)
I found that Redis4.0 has brought us many new things Features, including the LFU-based hotspot key discovery mechanism. With this new feature, we can implement hotspot key statistics on this basis. This is just my personal idea.
Interviewer's psychology: The young man is quite thoughtful and broad-minded, and he also pays attention to modifying the source code. I don't have this ambition. We need people like this in our team.
(Discover problems, analyze problems, solve problems, and directly tell how to solve hot data problems without waiting for the interviewer to ask questions. This is the core content)
3. How to solve hot data issues
Answer: Regarding how to manage hot data issues, we mainly consider two aspects to solve this problem. The first is data sharding, so that The pressure is evenly distributed to multiple shards of the cluster to prevent a single machine from hanging. The second is migration isolation.
Summary summary:
-
key split:
If the current key type is a secondary data structure, such as Hash type. If the number of hash elements is large, you can consider splitting the current hash so that the hot key can be split into several new keys and distributed to different Redis nodes, thereby reducing the pressure -
Migrate hotspot key:
Taking Redis Cluster as an example, you can migrate the slot where the hotspot key is located to a new Redis node separately. In this way, even if the QPS of this hotspot key is very high, it will not affect the entire cluster. Other businesses can also be customized and developed, and hotspot keys are automatically migrated to independent nodes. This solution is also more multi-copy. -
Hotspot key current limit:
For read commands, we can solve the problem by migrating the hotspot key and then adding slave nodes. For write commands, we can limit the current by targeting this hotspot key separately. . -
Increase local cache:
For businesses whose data consistency is not that high, you can cache the hotspot key in the local cache of the business machine, because it is in the local memory of the business end. A remote IO call is eliminated. However, when the data is updated, it may cause inconsistency between the business and Redis data.
Interviewer: You answered very well and considered it very comprehensively.
4. Interviewer: Regarding the last question about Redis, Redis supports rich data types, so how to solve the problem of large Value stored in these data types? Have you encountered this situation online?
Problem analysis: Compared with the big concept of hot key, the concept of big Value is better to understand. Since Redis runs in a single thread, if the value of an operation is very large, it will affect the entire operation. The response time of redis has a negative impact because Redis is a Key-Value structure database. A large value means that a single value takes up a large amount of memory. The most direct impact on the Redis cluster is data skew.
Answer: (You want to stump me? I am prepared.)
Let me first talk about how big the Value is, which is given based on the company's infrastructure. The experience value can be divided as follows:
Note: (The experience value is not a standard, it is summarized based on long-term observation of online cases by cluster operation and maintenance personnel)
- Big: string type value > 10K, number of elements in set, list, hash, zset and other collection data types > 1000.
- Extra large: string type value > 100K, the number of elements in set, list, hash, zset and other collection data types > 10000.
Since Redis runs in a single thread, if the value of an operation is very large, it will have a negative impact on the response time of the entire redis. Therefore, it can be split if it can be split in terms of business. Here are a few typical splits: Demolition plan:
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
The above is the detailed content of Let's analyze the solutions to Redis hot data problems together. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
