

Take you through the MySQL index

This article brings you relevant knowledge about mysql, which mainly introduces some issues in the advanced mysql chapter, including what an index is, the underlying implementation of the index, etc. Let’s talk about it together Take a look, hope it helps everyone.

Recommended learning: mysql video tutorial
MySQL, a familiar and unfamiliar term, as early as When we were learning Javaweb, we used the MySQL database. At that stage, MySQL seemed to us to be just a good thing for storing data. When storing, we stuffed it all in, and when querying, we also blindly query the whole table (without a little bit of information). optimization).
We always deceive ourselves and others, thinking that we can just optimize through other aspects. We are reluctant to face MySQL Advanced, and instead learn something that seems more advanced. For "advanced" things, learn Redis to share the pressure of MySQL, learn MyCat and other middleware, and implement master-slave replication, read-write separation, sub-database and sub-tableetc. (I’m talking about melo, that’s right)
When I was preparing for the interview, I found that I didn’t know all about MySQL in the interview questions~
As for the cutting-edge middleware I learned, I asked Get almost very little! ! I only know how to use it. When writing my resume, I can only weakly write "understanding" xxx middleware...
Of course, learningMySQL Advanced Chapter is not just for the sake of Interviews, in actual projects, the optimization of this area is very important. After experiencing server downtime, I can only silently...
Let's start from now, it's still too late to go ashore at this time ! ! ! Taking advantage of the gold three and silver four, supplement the knowledge points of MySQL Advanced Chapter and start the journey of MySQL Advanced Chapter from the following aspects
It is recommended to go through the sidebar directory Retrieve the parts that are helpful to you, among which with emoji expression prefix is the key part. If you think it is helpful to you, the editor will continue to improve this article and the MySQL column.
Index definition
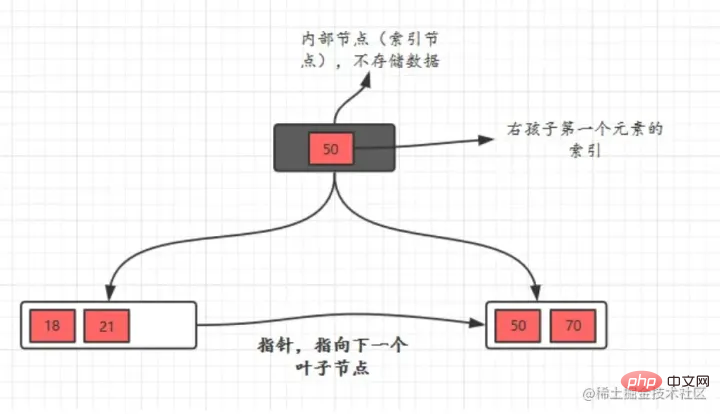
MySQL’s official definition of index is: Index (index) is a data structure (ordered) that helps MySQL obtain data efficiently. Indexes are added to fields in database tables as a mechanism to improve query efficiency. In addition to data, the database system also maintains data structures that satisfy specific search algorithms. These data structures reference (point to) the data in some way, so that advanced search algorithms can be implemented on these data structures. This data structure is an index. . As shown in the diagram below:
In fact, simply speaking, the index is a sorted data structure
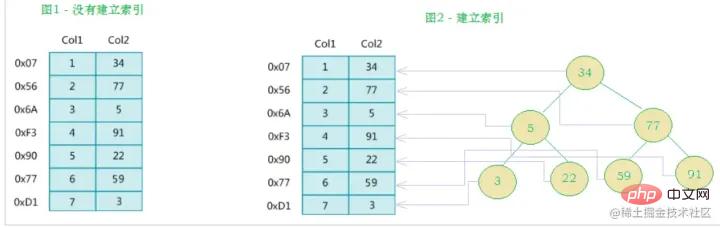
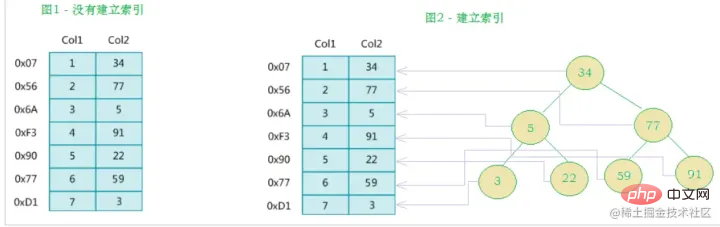
The left side is The data table has a total of two columns and seven records. The leftmost one is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, you can maintain a binary search tree as shown on the right. Each node contains index key value and a pointer to the physical address of the corresponding data record, so You can use binary search to quickly obtain the corresponding data.
Index advantages
- Speed up the speed of search and sort, reduce the IO cost of the database and CPU consumption
- By creating a unique index, the uniqueness of each row of data in the database table can be guaranteed.
Disadvantages of index
- The index is actually a table, which saves the primary key and index field and points to the record of the entity class. It needs Occupying space
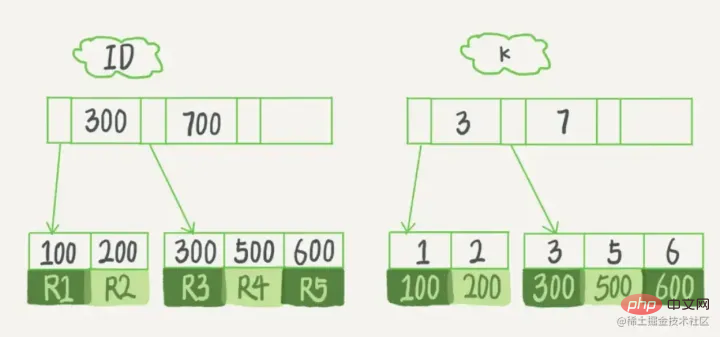
- Although query efficiency is increased, for additions, deletions and modifications, every time the table is changed, the index needs to be updated. New: Naturally, new nodes need to be added in the index tree. Delete: The records pointed to in the index tree may will fail, which means that many nodes in this index tree are invalid changes: the pointer to of the node in the index tree may need to be changed to
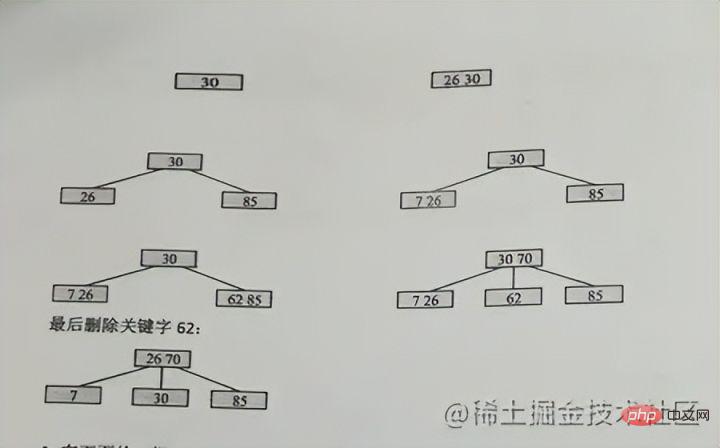
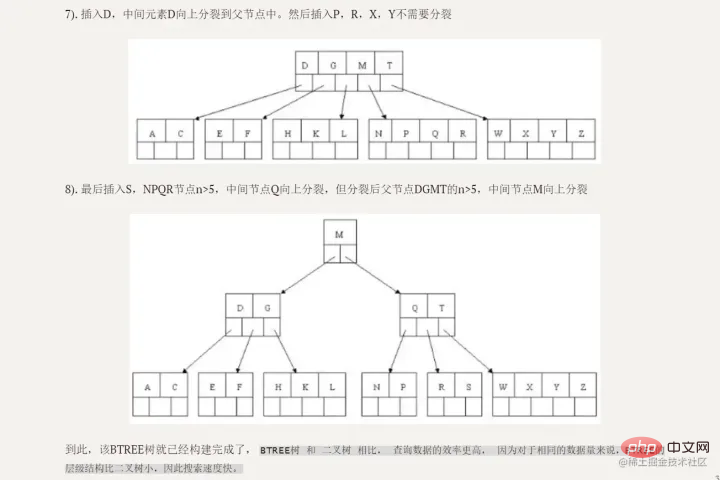
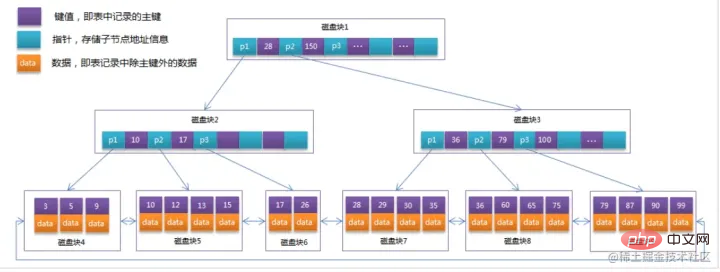
, but in fact, We do not use binary search tree to store in MySQL, why?
You must know that in a binary search tree, a node here can only store one piece of data, and a node corresponds to a disk block in MySQL, so we read one disk block each time , only one piece of data can be obtained, and the efficiency is very low, so we will think of using a B-tree structure to store it.
Index structure
The index is implemented in the storage engine layer of MySQL, not in the server layer. Therefore, the indexes of each storage engine are not necessarily exactly the same, and not all engines support all index types.
- BTREE index: The most common index type, most indexes support B-tree indexes.
- HASH Index: Only supported by Memory engine, the usage scenario is simple.
- R-tree index (spatial index): Spatial index is a special index type of the MyISAM engine. It is mainly used for geospatial data types. It is usually less used and will not be specially introduced.
- Full-text (full-text index): Full-text index is also a special index type of MyISAM, mainly used for full-text index. InnoDB supports full-text index starting from Mysql5.6 version.
MyISAM, InnoDB, and Memory storage engines support various index types
Index |
INNODB ENGINE |
MYISAM ENGINE |
MEMORY ENGINE |
||||||||||||
BTREE Index |
Support |
Support |
## Support | ||||||||||||
| HASH index | Not supported | Not supported | Supported | ||||||||||||
| R-tree index | Not supported | Supported | Not supported | ||||||||||||
| Supported after version 5.6 | Supported | ##Not supported |

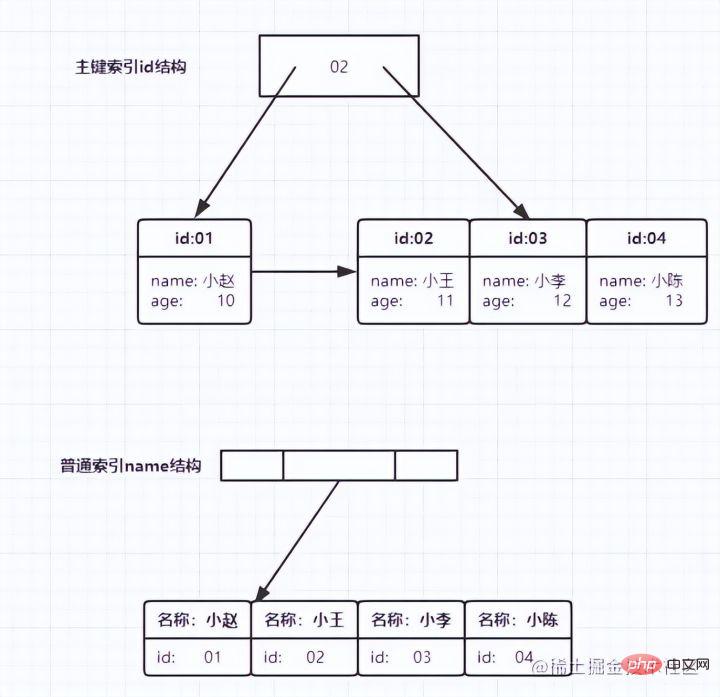
name |
##status | address | id(primary key) |
| Xiaomi 1 | 0 | 1 | 1 |
| 1 | 1 | 2 |

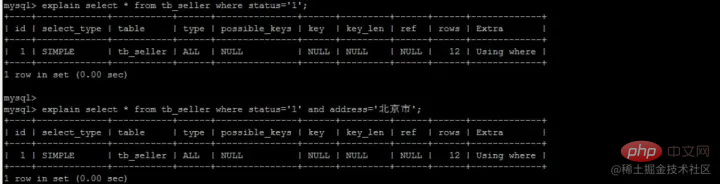

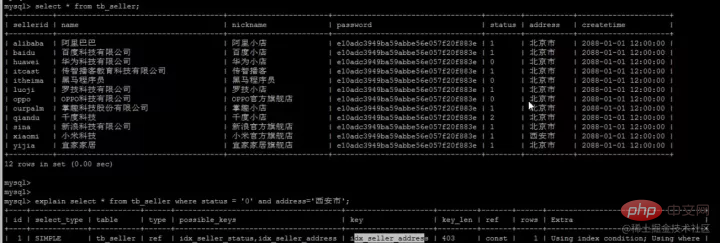
The above is the detailed content of Take you through the MySQL index. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 How to build a SQL database
Apr 09, 2025 pm 04:24 PM
How to build a SQL database
Apr 09, 2025 pm 04:24 PM
Building an SQL database involves 10 steps: selecting DBMS; installing DBMS; creating a database; creating a table; inserting data; retrieving data; updating data; deleting data; managing users; backing up the database.
