

Graphical analysis of Redis thread model

This article brings you relevant knowledge about Redis, which mainly introduces related issues about the thread model. Redis is a single thread. Let’s take a look at it together. I hope Helpful to everyone.

Recommended learning: Redis video tutorial
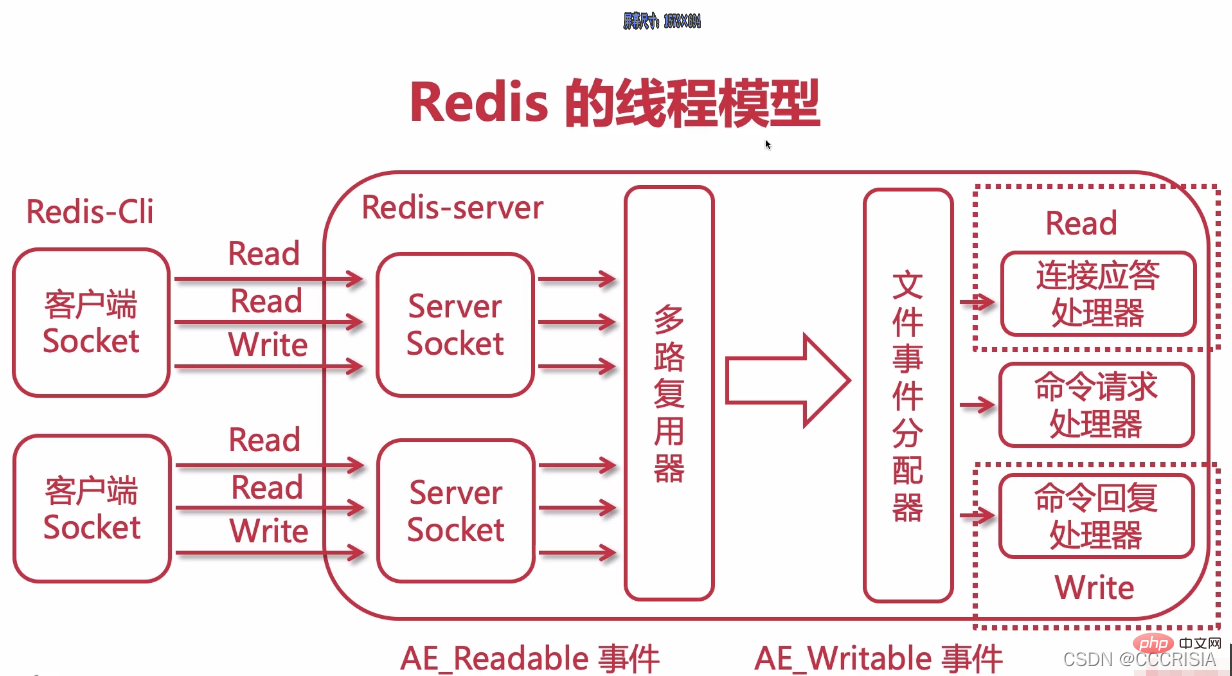
Redis is a single thread, which requires To pay attention to.
First of all, we will have a client. This client actually used a tool like redis client to connect to the redis server before us.
If we integrate it into java later, the corresponding client will actually be provided in java.
Then we will have a redis server, which is actually one of our redis. After the entire service is started, it will have a process.
In our release, it actually has two things internally.
First of all, it will have a multiplexer, which we have already introduced in the previous lesson. It is a non-blocking model.
Then it actually has a file event allocator, which is specially used to allocate some events.
Under this, it will be divided into three different processors, let’s take a look at each.
First there is a connection response processor, and finally there is a command request processor, and there is a command reply processor.
How to understand it? First let's look at a connection response handler.
When connecting to the response processor, one of its main functions is to maintain a link with our client.
Once one of our redis servers is started, we will actually have a read event bundled with our connection responder.
Its full name is actually called AE_readable. You can think of it as a sign, it will have such an event, and this event will be bundled with our connection response processor.
Finally, when one of our clients and our server are going to establish a connection, this actually means that we typed a redis client in the command line tool at the beginning, which is definitely needed at the beginning. Let's establish a connection with our server. When establishing a connection, it will actually send a read flag, which is actually a read time. At this time, in our redis server, it will actually have a server socket.
Server socket actually corresponds to one of our client sockets. They are a piece of content in network programming, and the communication between them is a socket. After we come into contact with an event like read, we will then hand it over to our multiplexer for processing.
If you leave it to him for processing, he is actually non-blocking. Once he receives it, he will put it into an arrow like ours.
As for this arrow here, we can actually call it a pipeline, or we can also call it a queue. It will be thrown in here. After being thrown in, this world will actually reach our file event dispatcher. When this allocator recognizes that it is a read event, it will match our connection response processor, that is, hand it over to it for processing.
It is a read that matches each other.
At this time, it can actually show that our client and server have established a connection. After the connection is established, if the read flag is set, this event will actually be handed over to our command request processor. If this command requests the processor, you can think of it as specifically processing requests, that is, a request. Then the command reply processor, you can understand it as a response, that is, a response.
Then we may have to go to the client, for example, we have to set a value, right? If you set a value, for example, set name ***, it is actually a command.
For this command, one of its world types is actually a read. Then it is thrown to the multiplexer through the server socket. After getting it, it is put into our queue and then handed over to the file event dispatcher.
After the file event dispatcher gets it, it will make a judgment. It will judge that the matching event is a read event. When it is a read event at this time, our command request processor will be asked to process our command. He will recognize it. He will recognize that the current one is a set name ***, so he will do a process. He wants to store a content set by our user and store this key value in our memory. This is actually the processing of a command request, which is a request.
When it is processed, it will then assign a white, which is a written identifier. If this logo is written here, we can actually use it as a response. Because after one of our requests is actually processed, after we finish entering a command, we may see an ok, right? If this is ok, it is actually equivalent to a piece of content written back to us by one of our command reply processors. So he will use a mark written by a write. In this way, one of our written tags will actually be bundled with our command reply processor. As for write, its full name is actually an event type called AE_writable.
Okay, then on our client, we actually need to do a write-back. It's ok, or when we are querying the list and we want to display all the contents in the list, it is actually a case of write-back. We want to display the content at the bottom of the console, which is an event type such as write. It is then handed over to our multiplexer and then thrown to one of our queues, which is assigned to one of our file event dispatchers. This time our web events will be matched. The web event is matched.
Subsequently, our command reply processor will do a write-back. It will put our OK, or the number of a list we obtained, the contents of the list, etc. As long as there is some content that needs to be displayed, it will be used as a response, that is, the content of the response will be written back to one of our clients and displayed on the client. In our current entire model, there are actually two different events, one called readable and the other called writable.
Of course, what we are setting up now is just one client. If we have multiple clients, their principles will be exactly the same. This is actually a threading model of release. It may be difficult to understand when you first come into contact with it, but it doesn't matter. This picture can actually help everyone deepen this intention.
Then his entire processing process can also be understood by following what I said. In order to facilitate everyone's understanding, we draw a picture here to give an example.
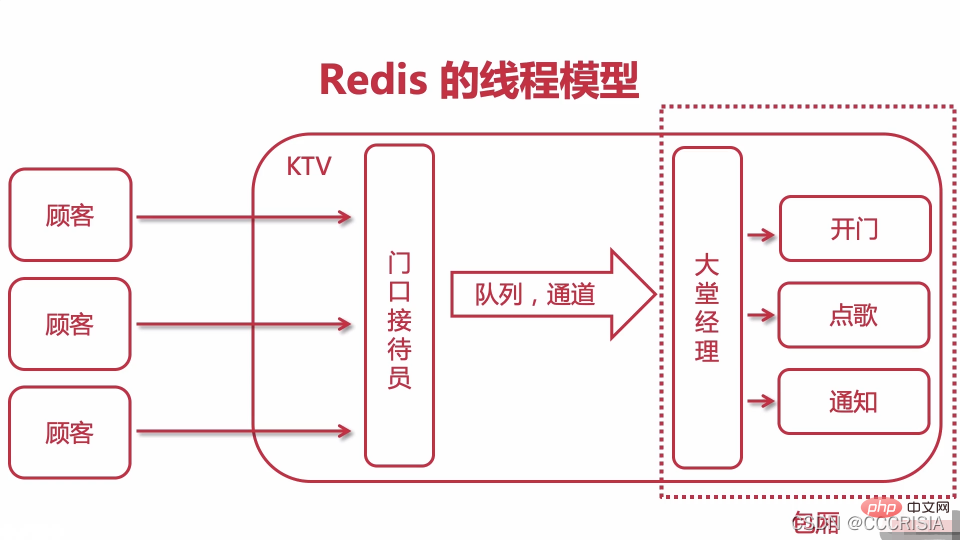
Suppose we have a KTV now, and this KTV is redis.
Then we have a lot of customers who want to sing. If they want to sing, there will definitely be employees in our KTV. We will divide the employees into two categories.
The first category is the receptionist at the door, and the second category is the lobby manager.
The receptionist at the door is actually a multiplexer, and the lobby manager is actually a file allocator.
Then, our customers must have some corresponding requests, or corresponding needs. At this time, we must ask the receptionist at the door and ask the receptionist at the door to do simple tasks. Some processing.
Maybe he wants to see what kind of activities the user wants to participate in, whether there are any coupons, etc.
Then the order taker at the door, if he is sure that the customer wants to sing, can say please go to the back, there is a passage behind. This passage is actually a queue. You line up to go to this passage. When you walk inside, it is a business hall for our entire KTV. There will be a lobby manager in the business hall. The lobby manager will handle a real request from one of our customers.
Then in one of our KTVs, we will definitely have a box. Each box will handle users and handle different requests from customers. Inside our box, there will be three young ladies or young brothers, who will handle different needs for users.
For example, the first one opens the door specifically for customers. The action of opening the door is equivalent to establishing a link between one of our clients and the release. Once the door opens, you can come in, right? After he comes in, this young lady will no longer be responsible for his corresponding work. He will hand him over to one of our subordinates. The following young lady or brother will handle some requests specifically for users.
For example, if a customer requests a song, the person requesting the song will be asked to do some corresponding processing. The way to do this is to turn on the computer and order and select songs. After selecting the song, you have to respond to the customer. You've got a point, right? You also need to hand some microphones to customers, so at this time there will be a notification that there is such a young lady, and this young lady will give this microphone to the customer. You can go sing now. We have already ordered this song for you. Go ahead and sing.
At this time, the whole action of a customer requesting a song and singing in the KTV is actually completed. This actually corresponds to an operation performed by a client that we mentioned in the release thread model before. First, the connection is established, then the request is processed, and then one of the requests is responded to. There are three steps in total.
In our area, the entire lobby manager and their song request notifications are actually handled internally. That is based on one of our boxes. As for the box, in our redis, can we use it as a memory, because operations such as storage and reading in redis are actually based on memory. So it is very fast if it is in memory.
If you are in our private room, you can sing in the private room, order some fruits, drink some beer, etc. In fact, if the operations are all based on one of our internal boxes, its series of actions, etc., will actually be completed very quickly.
This can actually be a simple understanding for one of our thread models. As for our redis, it is actually a single-threaded mode. Why is using a single-threaded model very fast?
In fact, there are two main points.
The first point is that one of our door receptionists is actually a multiplexer. As for this multiplexer, it is based on a non-blocking model, so it is processed very quickly. It will not wait for responses one by one because of the previous blocking mode. Now that a model like an IO multiplexer is used, its processing performance is actually very, very fast.
The other part is our lobby manager. This part actually operates based on memory. For pure memory operations, it will actually be very, very fast.
Of course, after using a single thread, one of its functions has also been mentioned. If a single thread is used, it can avoid multi-threading. Because if you have multiple threads, you may use one of its context switches. Once switched, it may cause some problems. In addition, some corresponding losses can also be avoided. So when we use the trunk model, its concurrency and efficiency are very, very high.
Recommended learning: Redis video tutorial
The above is the detailed content of Graphical analysis of Redis thread model. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
Redis, as a message middleware, supports production-consumption models, can persist messages and ensure reliable delivery. Using Redis as the message middleware enables low latency, reliable and scalable messaging.
