
 Database
Mysql Tutorial
Summary of solutions to MySQL master-slave delay and read-write separation
Database
Mysql Tutorial
Summary of solutions to MySQL master-slave delay and read-write separation
Summary of solutions to MySQL master-slave delay and read-write separation

This article brings you relevant knowledge about mysql, which mainly introduces the solutions to master-slave delay and read-write separation. Let’s take a look and summarize several methods. I hope everyone has to help.

Recommended learning: mysql video tutorial
We all know that Internet data has characteristics, and most scenarios are Read more and write less, such as: Weibo, WeChat, Taobao e-commerce, according to the 28 principle, the read traffic ratio can even reach 90%
Combined with this feature, we The underlying database architecture will also be adjusted accordingly. Using read-write separation
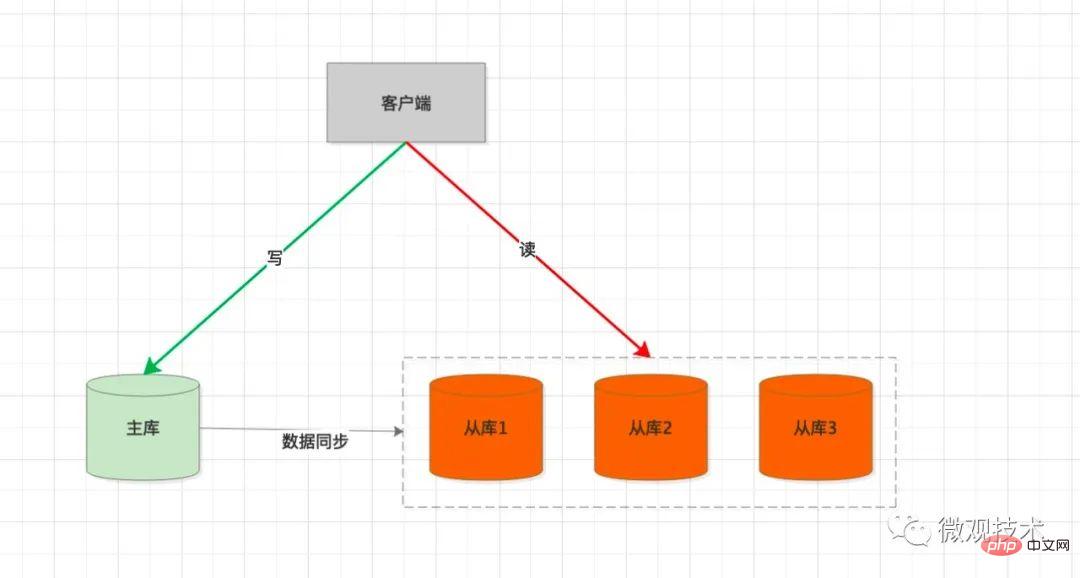
Processing process:
The client will be integrated SDK, every time SQL is executed, it will be judged whether it is
writeorreadoperationIf it is
writeSQL, The request will be sent to themain databaseThe main database executes SQL. After the transaction is submitted,
binlogwill be generated and synchronized to theslave LibrarySlave libraryPlaybackbinlogthrough SQL thread, and generate corresponding data in the slave library tableIf it is
readingSQL, the request will pass theLoad balancingstrategy and select aslave libraryto handle the user request
It seems very reasonable, but it is not the case if you think about it.
Main library and Slave library use asynchronous replication of data. If these two What should I do if the data between users is not synchronized?
The main library has just finished writing the data, and before the slave library has time to pull the latest data, the read request comes, giving the user the feeling that the data is lost? ? ?
In response to this problem, today, we will discuss what solutions are there?
1. Forced use of the main database
Treat differently for unused business requirements
Scenario 1:
If it is The requirements for real-time of data are not very high. For example, if a big V has tens of millions of fans and posts a Weibo message, it will not have a particularly big impact if the fans receive the message a few seconds later. At this time, you can go to from the library.
Scenario 2:
If the real-time requirements for data are very high, such as financial services. We can force the query to go to the main database under the client code tag.
2. Delayed query from the slave database
Since data synchronization between the master and slave database requires a certain time interval, there is a strategy to delay querying data from the slave database.
For example:
select sleep(1) select * from order where order_id=11111;
In formal business query, first execute a sleep statement to reserve a certain data synchronization buffer period for the slave database.
Because it is a one-size-fits-all solution, when faced with high-concurrency business scenarios, performance will drop dramatically. This solution is generally not recommended.
3. Determine whether the master and slave are delayed? Decide whether to choose the master library or the slave library
Option 1:
Execute the command in the slave library show slave status
View seconds_behind_master The value, the unit is seconds, if it is 0, it means there is no delay between the master and slave databases
Option 2:
Compare the master and slave databases The file point
is still executed show slave status, and the response result contains a key parameter
Master_Log_File The latest file read from the master library
Read_Master_Log_Pos The coordinate position of the latest file read from the main library
Relay_Master_Log_File The latest file executed from the library
Exec_Master_Log_Pos The coordinate position of the latest file executed from the library
Compare the two parameters to see if the above parameters are equal
Option 3:
Compare GTID sets
Auto_Position=1 Use GTID protocol between master and slave
Retrieved_Gtid_Set received from the library The GTID set of all binlog logs
Executed_Gtid_Set The GTID set that has been executed from the library
Compare Retrieved_Gtid_Set and # Whether the values of ##Executed_Gtid_Set are equal
Disadvantages:
No matter which of the above solutions is adopted, if the write operations of the main library are frequent, the value of the slave library will never keep up with the value of the main library. , then the read traffic will always hit the main database.针对这个问题,有什么解决方案?
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了
四、从库节点判断主库位点
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务
select master_pos_wait(file, pos[, timeout]);
file 和 pos 表示主库上的文件名和位置
timeout 可选, 表示这个函数最多等待 N 秒
缺点:
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
五、比较 GTID
执行下面查询命令
阻塞等待,直到从库执行的事务中包含 gtid_set,返回 0
超时,返回 1
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数
session_track_gtids设置为OWN_GTID,调用 API 接口mysql_session_track_get_first返回结果解析出 GTID
处理流程:
发起
写SQL 操作,在主库成功执行后,返回这个事务的 GTID发起
读SQL 操作时,先在从库执行select wait_for_executed_gtid_set (gtid_set, 1)如果返回 0,表示已经从库已经同步了数据,可以在从库执行
查询操作否则,在主库执行
查询操作
缺点:
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
六、引入缓存中间件
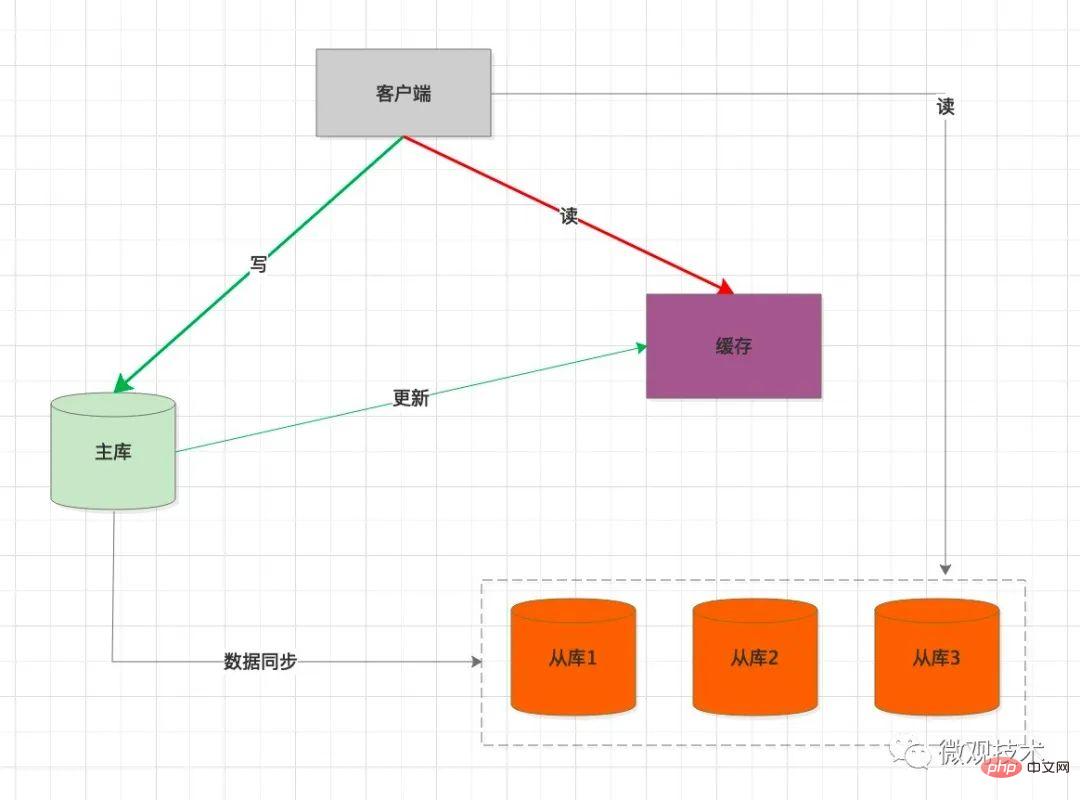
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质
处理过程:
客户端
写SQL ,操作主库同步将缓存中的数据删除
当客户端读数据时,优先从缓存加载
如果 缓存中没有,会强制查询主库预热数据
缺点:
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
七、数据分片
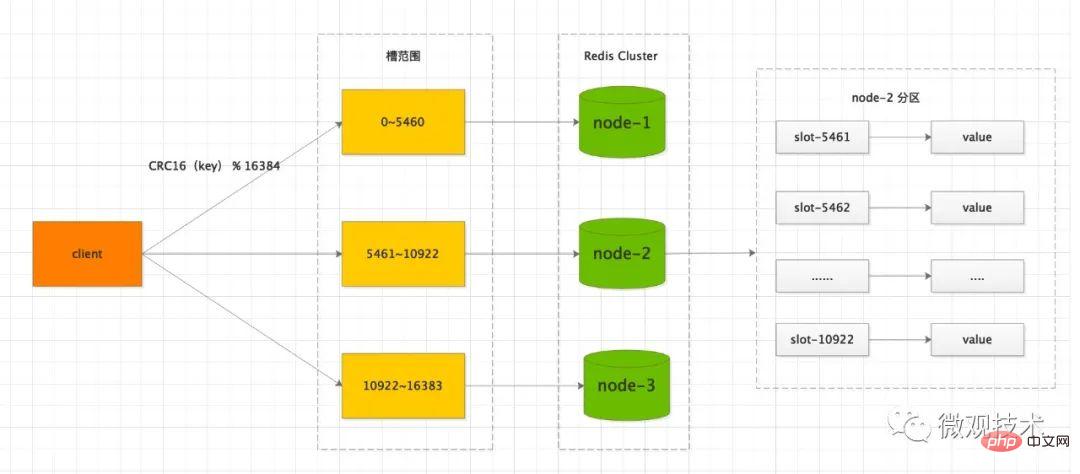
参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
推荐学习:mysql视频教程
The above is the detailed content of Summary of solutions to MySQL master-slave delay and read-write separation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 Can I retrieve the database password in Navicat?
Apr 08, 2025 pm 09:51 PM
Can I retrieve the database password in Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat itself does not store the database password, and can only retrieve the encrypted password. Solution: 1. Check the password manager; 2. Check Navicat's "Remember Password" function; 3. Reset the database password; 4. Contact the database administrator.
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
Steps to perform SQL in Navicat: Connect to the database. Create a SQL Editor window. Write SQL queries or scripts. Click the Run button to execute a query or script. View the results (if the query is executed).
