

Let's analyze the principles of MySQL transaction workflow together

This article brings you relevant knowledge about mysql, which mainly introduces issues related to the principles of transaction workflow, including the atomicity of transactions is achieved through undo log, transactions The persistence is achieved through redo log and so on. Let’s take a look at it. I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
- The atomicity of transactions is achieved through undo log
- The durability of transactions is achieved through redo log
- The isolation of transactions is achieved through (read-write lock MVCC)
- And the ultimate boss consistency of transactions is Achieved through atomicity, persistence, and isolation! ! !
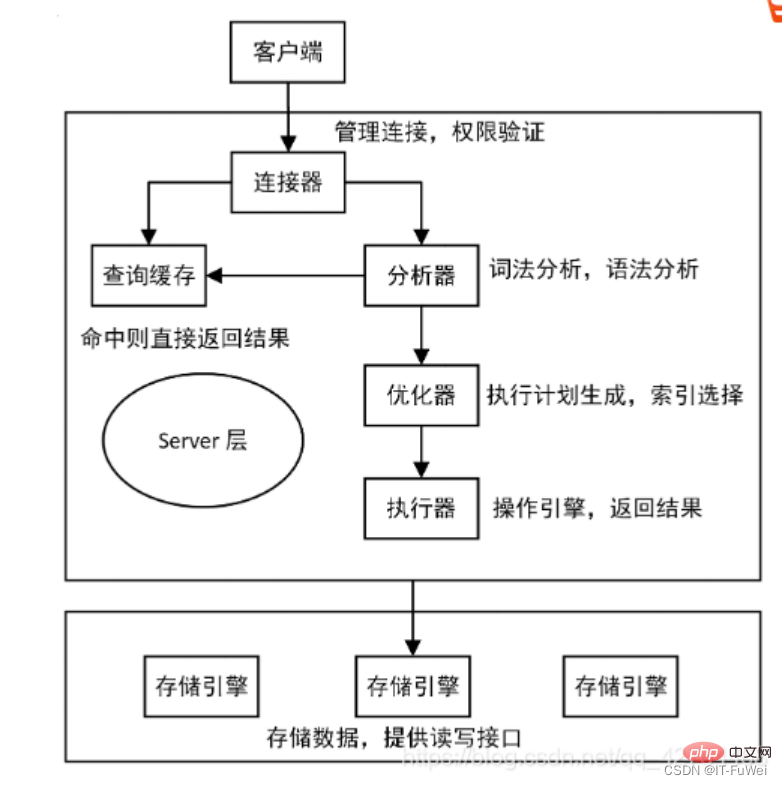
1. redo log to achieve persistence
problem 1: Why do you need redo log?
InnoDB is the storage engine of MySQL. Data is stored on the disk. However, if disk IO is required every time to read and write data, the efficiency will be reduced. Very low. To this end, InnoDB provides a cache (Buffer Pool) as a buffer for accessing the database: when reading data from the database, it will first be read from the Buffer Pool. If there is no buffer pool, it will be read from the disk and put into the Buffer. Pool; when writing data to the database, it will be written to the Buffer Pool first, and the modified data in the Buffer Pool will be regularly refreshed to the disk.
The use of Buffer Pool greatly improves the efficiency of reading and writing data, but it also brings new problems: if MySQL goes down and the modified data in the Buffer Pool has not been flushed to the disk, it will cause Data loss and transaction durability cannot be guaranteed.
Question 2: How does redo log ensure the durability of transactions?
Redo log can be simply divided into the following two parts:
The first is the in-memory redo log buffer (redo log buffer ), is volatile, and is stored in memory.
The second is the redo log file, which is persistent and stored on the disk.
Let’s talk about writing Redo in detail here. Timing:
After the data page modification is completed and before the dirty pages are flushed out of the disk, the redo log is written. Note that the data is modified first and the log is written later
The redo log is written back to the disk before the data page
Modifications of the clustered index, secondary index, and undo page all need to be recorded in the Redo log
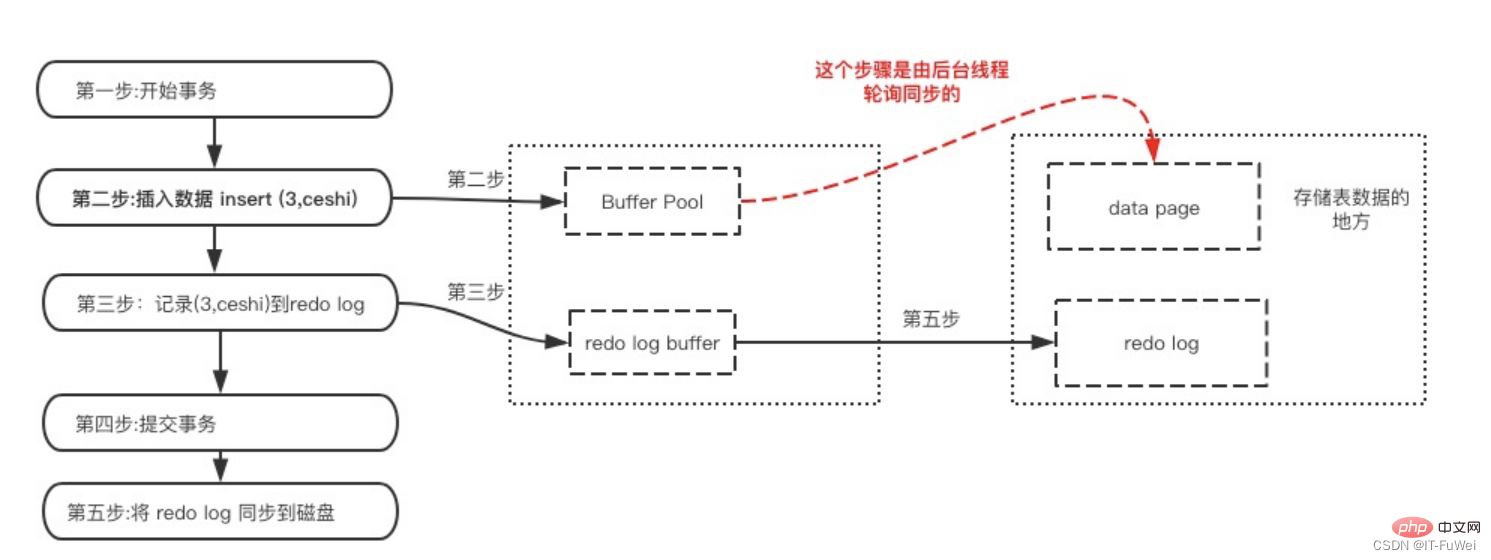
In MySQL, if every update operation needs to be written to the disk, then the disk must also find the corresponding record and then update it. The IO cost and search cost of the entire process are very high. In order to solve this problem, MySQL designers used redo log to improve update efficiency.
When a transaction is committed, the redo log buffer is first written to the redo log file for persistence, and it is not completed until the commit operation of the transaction is completed. This approach is also called Write-Ahead Log (pre-log persistence). Before persisting a data page, the corresponding log page in memory is persisted.
Specifically, when a record needs to be updated, the InnoDB engine will first write the record to the redo log (redo log buffer) and update the memory (buffer pool). At this time, the update is completed. . At the same time, the InnoDB engine will update this operation record to the disk (flush dirty pages) at an appropriate time (such as when the system is idle).
Multiple pages can be modified in one transaction. Write-Ahead Log can ensure the consistency of a single data page, but cannot guarantee the durability of the transaction. Force-log-at-commit requires that when a transaction is committed , all mini-transaction logs generated by it must be flushed to disk. If after the log flush is completed, the database crashes before the pages in the buffer pool are flushed to the persistent storage device, then when the database is restarted, the log can be used to ensure Data integrity.
Question 3: What is the process of rewriting logs?
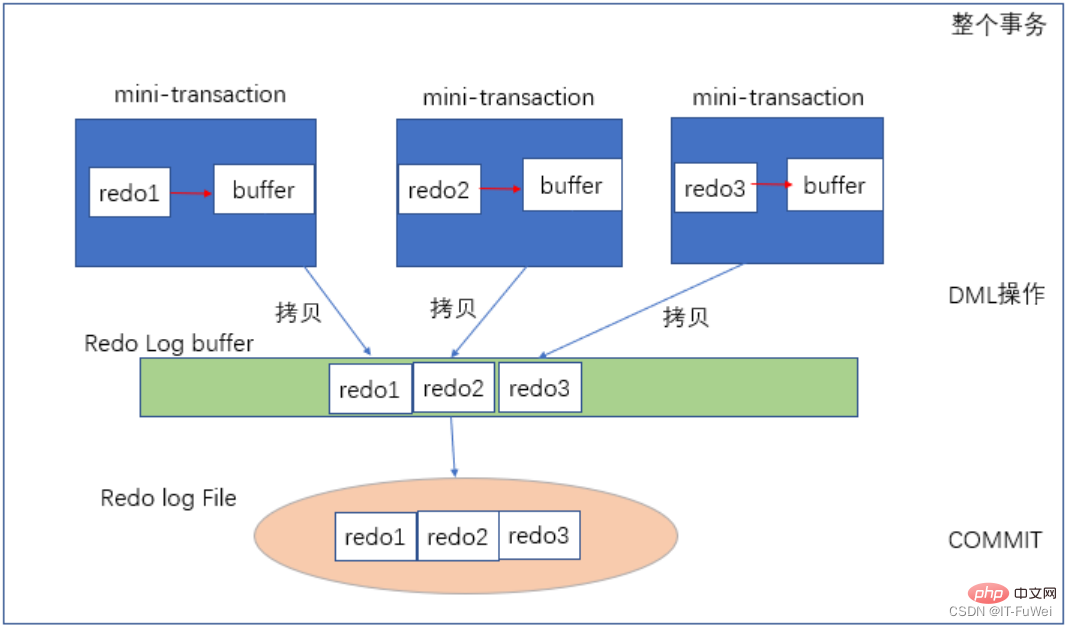
The above figure shows the redo log writing process. Each mini-transaction corresponds to each DML operation, such as an update statement, which is guaranteed by a mini-transaction. After the data is modified, redo1 is generated , first write it into the mini-transaction private Buffer. After the update statement ends, copy redo1 from the private Buffer to the public Log Buffer. When the entire external transaction is committed, the redo log buffer is flushed into the redo log file. (The redo log is written sequentially, and the sequential reading and writing of the disk is much faster than random reading and writing)
Question 4: Data writing Is the final placement updated from the redo log or the buffer pool?
In fact, redo log does not record the complete data of the data page, so it does not have the ability to update the disk data page by itself, so it cannot There are situations where the past data updated by the redo log is finally placed on the disk.
① After the data page is modified, it is inconsistent with the data page on the disk and is called a dirty page. The final data flushing is to write the data pages in the memory to the disk. This process has nothing to do with redo log.
② In a crash recovery scenario, if InnoDB determines that a data page may have lost updates during crash recovery, it will read it into memory and then let redo log update the memory content. After the update is completed, the memory page becomes a dirty page and returns to the state of the first situation
Question 5: What is redo log buffer? Should I modify the memory first or write the redo log file first?
During the update process of a transaction, the log must be written multiple times. For example, the following transaction:
Copybegin;
INSERT INTO T1 VALUES ('1', '1');
INSERT INTO T2 VALUES ('1', '1 ');
commit;
This transaction will insert records into two tables. During the process of inserting data, the generated logs must be saved first, but they cannot be committed before they are committed. When the time comes, write it directly to the redo log file.
So the redo log buffer is needed. It is a piece of memory used to store redo logs first. In other words, when the first insert is executed, the data memory is modified and the redo log buffer is also written to the log.
However, the actual writing of the log to the redo log file is done when the commit statement is executed.
redo log buffer is essentially just a byte array, but in order to maintain this buffer, a lot of other meta data needs to be set, all of which are encapsulated in the log_t structure.
Question 6: Are redo logs written to disk sequentially?
The redo log writes files in a sequential manner. When all files are full, it returns to the corresponding starting position of the first file. To perform overwriting, after each transaction is submitted, the relevant operation logs are first written into the redo log file and appended to the end of the file. This is a sequential I/O
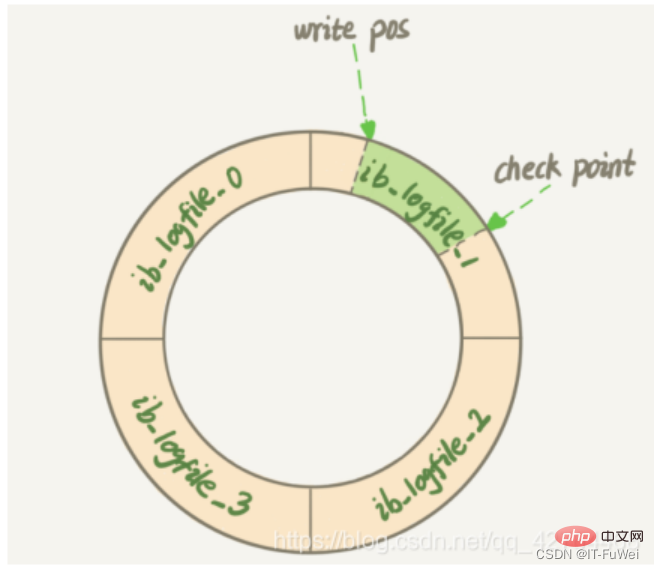
The picture shows a set of redo log logs of 4 files. The checkpoint is the current location to be erased. Before erasing the record, the corresponding data needs to be written to disk (update the memory page, wait Flush dirty pages). The part between write pos and checkpoint can be used to record new operations. If write pos and checkpoint meet, it means that the redo log is full. At this time, the database stops executing the database update statement and instead synchronizes the redo log to the disk. The part between checkpoint and write pos is waiting for the disk to be written (first update the memory page, and then wait for the dirty page to be flushed).
With the redo log, when the database restarts abnormally, it can be restored based on the redo log, which is crash-safe.
redo log is used to ensure crash-safe capabilities. When the innodb_flush_log_at_trx_commit parameter is set to 1, it means that the redo log of each transaction is directly persisted to the disk. It is recommended to set this parameter to 1 to ensure that data will not be lost after MySQL restarts abnormally
2. Bin log
MySQL Overall, there are actually two parts: One is the server layer, which mainly does things at the MySQL functional level; the other is the engine layer, which is responsible for specific storage-related matters. The redo log we talked about above is a log unique to the InnoDB engine, and the Server layer also has its own log, called binlog (archived log)
Why are there two logs?
Because there was no InnoDB engine in MySQL at the beginning. MySQL's own engine is MyISAM, but MyISAM does not have crash-safe capabilities, and binlog logs can only be used for archiving. InnoDB was introduced to MySQL in the form of a plug-in by another company. Since relying only on binlog does not have crash-safe capabilities, InnoDB uses another log system, that is, redo log, to achieve crash-safe capabilities.
The two logs have the following three differences.
① redo log is unique to the InnoDB engine; binlog is implemented by the Server layer of MySQL and can be used by all engines.
② redo log is a physical log, which records "what modifications were made on a certain data page"; binlog is a logical log, which records the original logic of this statement, such as "give ID=2 this The c field of a row is incremented by 1".
③ The redo log is written in a loop, and the space will always be used up; the binlog can be written additionally. "Append writing" means that after the binlog file reaches a certain size, it will switch to the next one and will not overwrite the previous log.
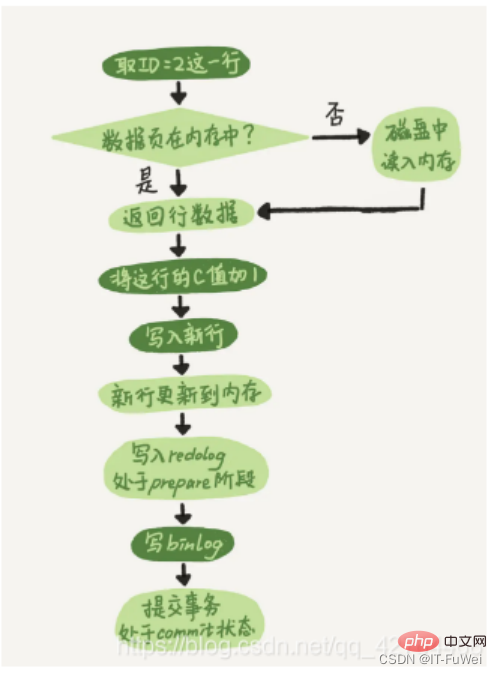
After having a conceptual understanding of these two logs, let’s look at the internal process of the executor and the InnoDB engine when executing this update statement. .
① The executor first looks for the engine to get the line ID=2. ID is the primary key, and the engine directly uses tree search to find this row. If the data page where the ID=2 row is located is already in the memory, it will be returned directly to the executor; otherwise, it needs to be read into the memory from the disk and then returned.
② The executor gets the row data given by the engine, adds 1 to this value, for example, it used to be N, but now it is N 1, gets a new row of data, and then calls the engine interface to write this new row of data. .
③ The engine updates this new row of data into the memory (InnoDB Buffer Pool) and records the update operation into the redo log. At this time, the redo log is in the prepare state. Then inform the executor that the execution is completed and the transaction can be submitted at any time.
④ The executor generates the binlog of this operation and writes the binlog to disk.
⑤ The executor calls the engine's commit transaction interface, and the engine changes the redo log just written to the commit state, and the update is completed
Split the writing of redo log into two steps: prepare and commit. This is the two-phase commit (2PC)
problem 1: What is the principle of two-stage submission?
MySQL uses two-phase commit to mainly solve the data consistency problem of binlog and redo log.
Two-stage commit principle description:
① redo log is written to the disk, and the InnoDB transaction enters the prepare state.
② If the previous prepare is successful and the binlog is written to the disk, then continue to persist the transaction log to the binlog. If the persistence is successful, the InnoDB transaction will enter the commit state.
redo log and binlog have a common data field called XID. During crash recovery, redo logs will be scanned in order:
① If a redo log with both prepare and commit is encountered, it will be submitted directly;
② If it is encountered with only parepare and commit If there is no commit redo log, use the XID to find the corresponding transaction in the binlog.
No record in binlog, rollback transaction
There is record in binlog, commit transaction
Question 2: Why Must there be "two-phase commit"?
If two-phase submission is not used, assume that the value of field c is 0 for the current row with ID=2, and then assume that during the execution of the update statement After writing the first log, a crash occurs before the second log is written. What will happen?
**Write redo log first and then binlog. **Suppose that the MySQL process restarts abnormally when the redo log is written but before the binlog is written. As we said before, after the redo log is written, even if the system crashes, the data can still be recovered, so the value of c in this line after recovery is 1.
But because the binlog crashed before it was finished, this statement was not recorded in the binlog at this time. Therefore, when the log is backed up later, this statement will not be included in the saved binlog.
Then you will find that if you need to use this binlog to restore the temporary library, because the binlog of this statement is lost, the temporary library will lose this update, and the value of c in the restored row will be 0 , different from the value of the original library.
**Write binlog first and then redo log. **If there is a crash after the binlog is written, since the redo log has not been written yet, the transaction will be invalid after the crash recovery, so the value of c in this line is 0. But the log "Change c from 0 to 1" has been recorded in the binlog. Therefore, when binlog is used to restore later, one more transaction will come out. The value of c in the restored row is 1, which is different from the value in the original database.
It can be seen that if "two-phase commit" is not used, the state of the database may be inconsistent with the state of the library restored using its log.
Simply put, both redo log and binlog can be used to represent the commit status of a transaction, and two-phase commit is to keep the two states logically consistent.
3. Undo log achieves atomicity
undo log has two functions: providing rollback and multi-version control (MVCC )
When the data is modified, not only redo is recorded, but also the corresponding undo is recorded. The undo log mainly records the logic of the data. Changes, in order to roll back the previous operations when an error occurs, it is necessary to record all the previous operations, and then roll back when an error occurs.
undo log only logically restores the database to its original state. During rollback, it actually does the opposite work. For example, an INSERT corresponds to a DELETE, and for each UPDATE, it corresponds to A reverse UPDATE puts back the line before modification. The undo log is used for transaction rollback operations to ensure the atomicity of the transaction.
The key to achieving atomicity is to be able to undo all successfully executed SQL statements when the transaction is rolled back. InnoDB implements rollback by relying on the undo log: when a transaction modifies the database, InnoDB will generate the corresponding undo log. If the transaction execution fails or rollback is called, causing the transaction to be rolled back, the information in the undo log can be used to The data is rolled back to the way it was before modification.
In the InnoDB storage engine, undo log is divided into:
insert undo log
update undo log
insert undo log refers to the insert operation The generated undo log is because the record of the insert operation is only visible to the transaction itself and not to other transactions. Therefore, the undo log can be deleted directly after the transaction is submitted, and no purge operation is required.
The update undo log records the undo log generated by delete and update operations. The undo log may need to provide an MVCC mechanism, so it cannot be deleted when the transaction is committed. When submitting, put it into the undo log list and wait for the purge thread to perform the final deletion.
Supplement: The two main functions of the purge thread are: cleaning up the undo page and clearing the data rows with the Delete_Bit identifier in the page. In InnoDB, the Delete operation in a transaction does not actually delete the data row, but a Delete Mark operation that marks the Delete_Bit on the record without deleting the record. It is a kind of "fake deletion", which is just marked. The real deletion work needs to be completed by the background purge thread.
Innodb uses B-tree as the index data structure, and the index where the primary key is located is ClusterIndex (clustered index), and the corresponding data content is stored in the leaf nodes in ClusterIndex. A table can only have one primary key, so there can only be one clustered index. If the table does not define a primary key, the first non-NULL unique index is selected as the clustered index. If there is not one, a hidden id column is generated as the clustered index. .
The index other than Cluster Index is Secondary Index (auxiliary index). The leaf nodes in the auxiliary index store the values of the leaf nodes of the clustered index.
In addition to the rowid just mentioned, InnoDB row records also include trx_id and db_roll_ptr. trx_id represents the id of the recently modified transaction, and db_roll_ptr points to the undo log in the undo segment.
The transaction id will increase when a new transaction is added, and trx_id can indicate the order in which the transaction starts.
Undo log is divided into two types: Insert and Update. Delete can be regarded as a special update, that is, modifying the deletion mark on the record.
update undo log records the previous data information, through which the state of the previous version can be restored.
When performing an insert operation, the generated Insert undo log can be deleted after the transaction is committed, because other transactions do not need this undo log.
When deleting and modifying operations, the corresponding undo log will be generated, and the db_roll_ptr in the current data record will point to the new undo log
4. MVCC implements isolation
MVCC (MultiVersion Concurrency Control) is called multi-version concurrency control.
InnoDB's MVCC is implemented by saving two hidden columns behind each row of records. Of these two columns, one saves the creation time of the row, and the other saves the expiration time of the row. Of course, what is stored is not the actual time value, but the system version number.
The main implementation idea is to separate reading and writing through multiple versions of data. This allows for lock-free reading and parallel reading and writing.
The implementation of MVCC in mysql relies on undo log and read view
- undo log: Undo log records multiple versions of a certain row of data.
- read view: used to determine the visibility of the current version of data
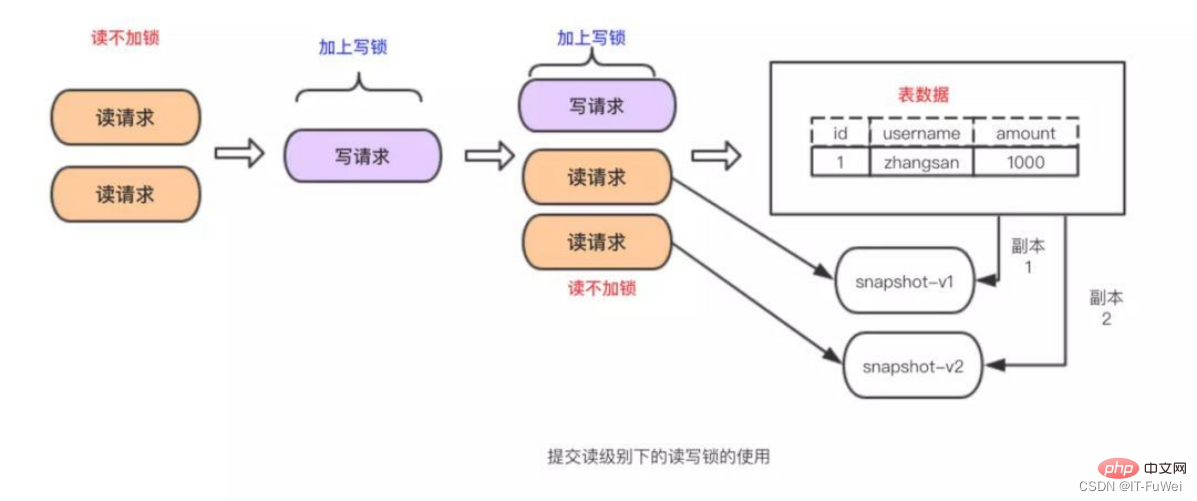
The consistent read view used by InnoDB when implementing MVCC, that is, consistent read view, is used to support RC (Read Committed , read commit) and RR (Repeatable Read, repeatable read) isolation level implementation.
Under the repeatable read isolation level, a transaction "takes a snapshot" when it starts.
MySQL's MVCC snapshot does not copy a copy of the database information every time a transaction comes in, but is implemented based on the system version number saved behind each row of information in the data table. As shown in the figure below, multiple versions of a row of information coexist, and each transaction may read different versions

Each transaction in InnoDB has a unique transaction ID, called transaction id. It is applied to the InnoDB transaction system at the beginning of the transaction, and is strictly incremental in the order of application.
And each row of data also has multiple versions. Every time a transaction updates data, a new data version is generated, and the transaction id is assigned to the row trx_id of this data version. At the same time, the old data version should be retained, and in the new data version, there may be information that can be obtained directly.
A row of records in the data table may actually have multiple versions (row), and each version has its own row trx_id. It is the state after a record has been continuously updated by multiple transactions.
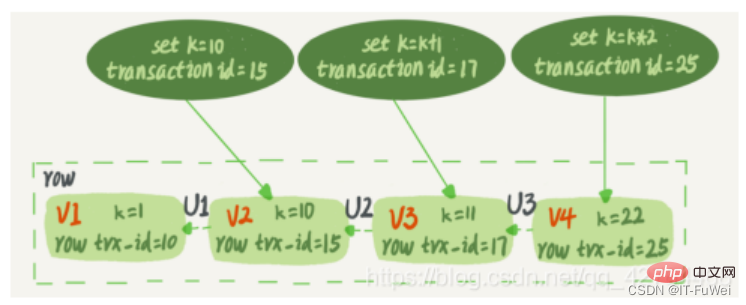
In the dotted box in the figure are 4 versions of the same row of data. The latest version is V4. The value of k is 22, which is The transaction with transaction id 25 is updated, so its row trx_id is also 25.
Will statement update generate undo log (rollback log)? So, where is the undo log?
Actually, the three dotted arrows in Figure 2 are undo log; V1, V2, and V3 do not physically exist, but are calculated based on the current version and undo log every time they are needed. from. For example, when V2 is needed, it is calculated by executing U3 and U2 sequentially through V4.
According to the definition of repeatable read, when a transaction is started, all submitted transaction results can be seen. But then, while this transaction is executing, updates from other transactions are not visible to it. Therefore, a transaction only needs to declare when it is started, "Based on the moment I start it, if a data version is generated before I start it, it will be recognized; if it is generated after I start it, I will not recognize it." , I have to find the previous version of it". Of course, if the "previous version" is not visible either, you have to keep looking forward. Also, if the data is updated by the transaction itself, it still has to recognize it.
5. MySQL lock technology
When there are multiple requests to read the data in the table, no action can be taken, but there are read requests among the multiple requests. , and there must be a measure to control concurrency when there is a modification request. Otherwise, inconsistencies are likely to occur. It is very simple for read-write locks to solve the above problems. You only need to use a combination of two locks to control read and write requests.
These two locks are called:
Shared lock (shared lock), also called "read lock", read lock can be shared, or multiple read requests can share a lock to read data without causing blocking.
Exclusive lock(exclusive lock), also called "write lock". The write lock will exclude all other requests to acquire the lock and will block until the writing is completed and the lock is released.
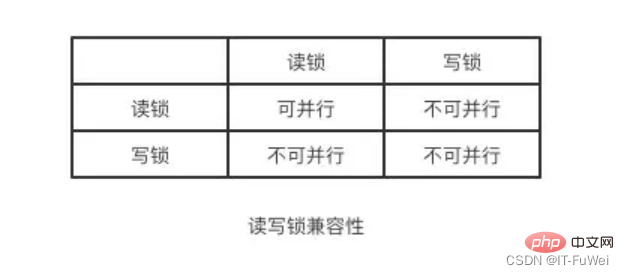
Summary: Through read-write locks, reading and reading can be done in parallel, but writing and reading, and writing and writing can not be done in parallel. The isolation is achieved through read-write locks! ! !
Recommended learning: mysql video tutorial
The above is the detailed content of Let's analyze the principles of MySQL transaction workflow together. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to view sql database error
Apr 10, 2025 pm 12:09 PM
How to view sql database error
Apr 10, 2025 pm 12:09 PM
The methods for viewing SQL database errors are: 1. View error messages directly; 2. Use SHOW ERRORS and SHOW WARNINGS commands; 3. Access the error log; 4. Use error codes to find the cause of the error; 5. Check the database connection and query syntax; 6. Use debugging tools.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
