

Detailed analysis of the atomicity of commands in Redis

This article brings you relevant knowledge about Redis, which mainly introduces issues related to the atomicity of commands in atomic operations, including concurrency processing solutions, programming models, and multi-IO Let’s take a look at the related content of threads and single commands. I hope it will be helpful to everyone.

Recommended learning: Redis video tutorial
How Redis copes with concurrent access
Schemes for handling concurrency in Redis
In business, sometimes we use Redis to handle some high-concurrency business scenarios, such as flash sale business and inventory operations. . .
Let’s first analyze what problems will occur in concurrency scenarios
Concurrency problems mainly occur in data modification. For the client to modify data, it is generally divided into the following two steps:
1. The client first reads the data locally and modifies it locally;
2. After the client modifies the data, it writes it back to Redis.
We call this process Read-Modify-Writeback operation (Read-Modify-Write, referred to as RMW operation). If the client performs RMW operations concurrently, it needs to ensure that read-modify-writeback is an atomic operation. When performing command operations, other clients cannot operate on the current data.
Wrong chestnut:
Counts the number of visits to a page. The number of visits is 1 each time the page is refreshed. Here, Redis is used to record the number of visits.
If each read-modify-writeback operation is not an atomic operation, then there may be a problem as shown in the figure below. Client 2 is also in the middle of the operation of client 1. Get the value of Redis and also perform 1, operation on the value, which will lead to errors in the final data.
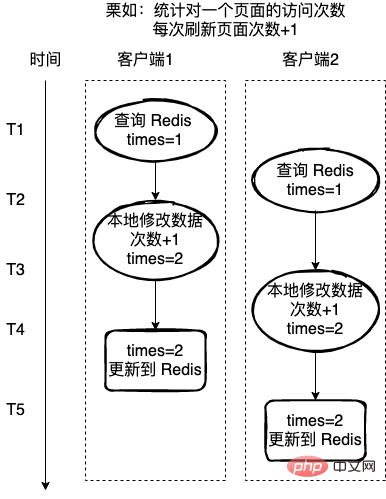
For the above situation, there are generally two ways to solve it:
1. Use Redis to implement a distributed lock, and use the lock to Protect that only one thread operates critical resources at a time;
2. Realize the atomicity of operation commands.
- Li Ru, for the above error example, if
Read-Modify-Writebackis an atomic command, then this command will have no difference during the operation. The threads read the operation data at the same time, so that the problems in the chestnut above can be avoided.
The following is a detailed analysis of the handling of concurrent access issues from the two aspects of atomicity and locks
Atomicity
For To implement mutually exclusive execution of critical section codes required for concurrency control, if you use the atomicity of commands in Redis, you can have the following two processing methods:
1. Use a single command with the help of atomicity in Redis;
2. Write multiple operations into a Lua script and execute a single Lua script atomically.
When discussing the atomicity of Redis, let’s first discuss the programming model used in Redis
The programming model of Redis
Used in Redis Coming to the Reactor model, Reactor is a non-blocking I/O model. Let’s take a look at the I/O model in Unix.
I/O model in Unix
I/O on the operating system is the data interaction between user space and kernel space, so I/O operations usually include the following Two steps:
1. Wait for network data to arrive at the network card (ready)/wait for the network card to be writable (ready for writing) –> read/write to the kernel buffer;
2 , Copy data from kernel buffer –> User space (read)/Copy data from user space –> Kernel buffer (write);
There are five basic I/O models in Unix
- Blocking I/O;
- Non-blocking I/O;
- I/O multiplexing;
- Signal driven I/ O;
- Asynchronous I/O;
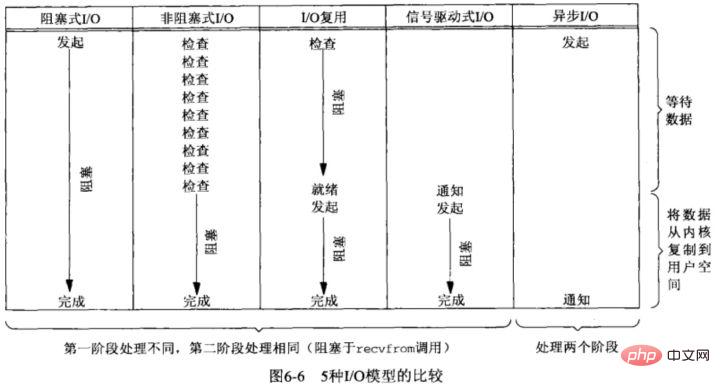
To determine whether an I/O model is synchronous or asynchronous, mainly depends on the second step: data Will copying between user and kernel space block the current process? If so, it is synchronous I/O, otherwise, it is asynchronous I/O.
Here are mainly divided into the following three I/O models
- Blocking I/O;
When the user program executes read, the thread will be Block, wait until the kernel data is ready, and copy the data from the kernel buffer to the application buffer. When the copy process is completed, read will return.
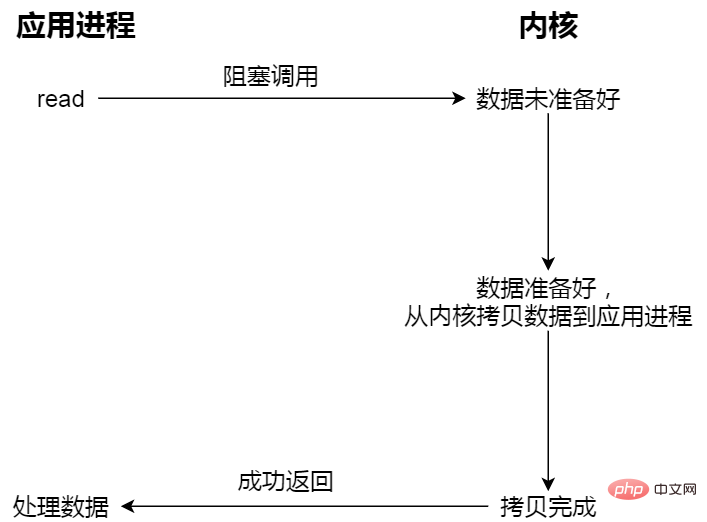
What is blocked and waited for are the two processes of "kernel data is ready" and "data is copied from kernel mode to user mode".
- Non-blocking synchronous I/O;
The non-blocking read request returns immediately when the data is not ready, and the execution can continue. At this time, the application does not continue to cycle. Query the kernel until the data is ready, the kernel copies the data to the application buffer, and the read call can obtain the result.
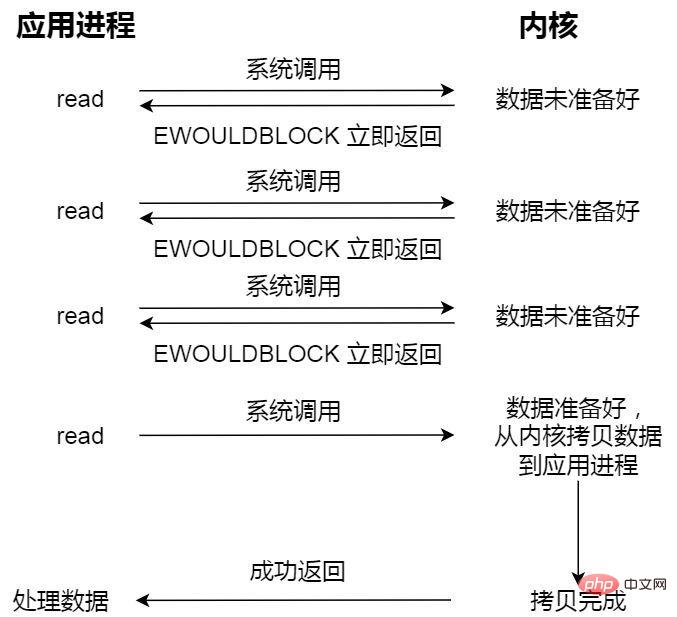
The last read call here, the process of obtaining data, is a synchronous process and requires waiting. Synchronization here refers to the process of copying kernel state data to the cache area of the user program.
- Non-blocking asynchronous I/O;
Initiate asynchronous I/O and return immediately. The kernel automatically copies data from kernel space to user space. This copy process It is also asynchronous and completed automatically by the kernel. Unlike the previous synchronous operation, the application does not need to actively initiate the copy action.
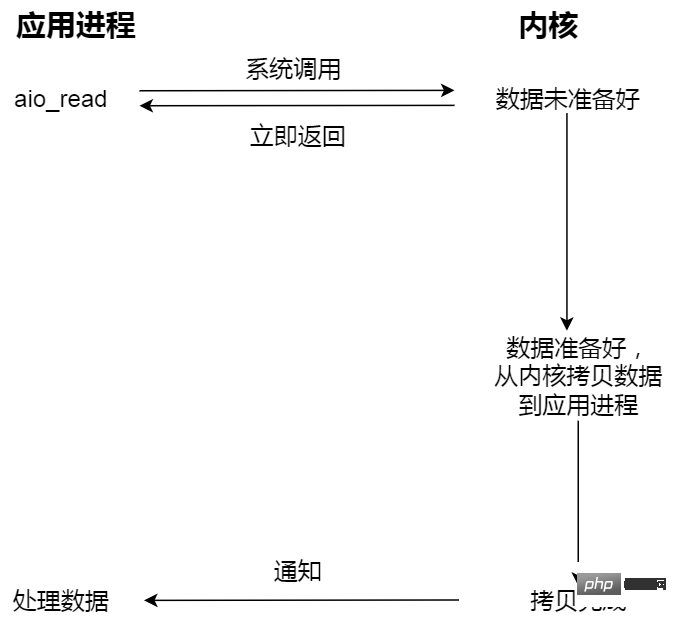
For example, if you go to the canteen to eat, you are like the application, and the canteen is like the operating system.
Blocking I/O For example, you go to the canteen to eat, but the food in the canteen is not ready yet, and then you keep waiting there and waiting. After waiting for a long time, you finally wait until the canteen aunt brings it to you. The food is brought out (data preparation process), but you still have to wait for the aunt to put the food (kernel space) into your lunch box (user space). After these two processes, you can leave.
Non-blocking I/O For example, you went to the canteen and asked your aunt if the food was ready. She told you if the food was ready, so you left. After a few dozen minutes, you came to the canteen again and asked your aunt. Auntie says it's ready, so Auntie helps you put the food into your lunch box. You have to wait for this process.
Asynchronous I/O For example, you ask the canteen aunt to prepare the dishes and put the dishes into the lunch box, and then deliver the lunch box to you. You don't need to wait for the whole process.
In web services, there are usually two architectures for processing web requests, namely: thread-based architecture (thread-based architecture), event-driven architecture(Event-driven model)
thread-based architecture
thread-based architecture: This is easier to understand , which is the multi-threaded concurrency mode. When the server processes a request, each request is assigned an independent thread for processing.
Because each request is assigned an independent thread, the blocking of a single thread will not affect other threads, which can improve the response speed of the program.
The disadvantage is that there is always a one-to-one relationship between connections and threads. If it is a long connection that is always in the Keep-Alive state, it will cause a large number of worker threads to wait in an idle state, for example, the file system access, network, etc. In addition, hundreds or thousands of connections can cause concurrent threads to waste large amounts of memory stack space.
event-driven architecture (event-driven model)
The event-driven architecture consists of event producers and event consumers, and is a loosely coupled, distributed Driven architecture, the producer collects events generated by an application and performs necessary processing on the event in real time before routing it to the downstream system without waiting for the system response. The downstream event consumer group receives the event message and processes it asynchronously.
The event-driven architecture has the following advantages:
- Reduce coupling;
Reduce the coupling of event producers and subscribers. The event producer only needs to pay attention to the occurrence of the event, and does not need to pay attention to how the event is processed and which subscribers it is distributed to. If any link fails, it will not affect the normal operation of other businesses.
- Asynchronous execution;
The event-driven architecture is suitable for asynchronous scenarios. Even during peak demand periods, events from various sources are collected and retained in the event bus, and then gradually Distribute delivery events without causing system congestion or excess resources.
- Scalability;
The routing and filtering capabilities in the event-driven architecture support partitioning of services to facilitate expansion and route distribution.
Reactor mode and Proactor mode are both implementation methods of event-driven architecture (event-driven model). Here is a detailed analysis of
Reactor mode
Reactor mode refers to the event-driven processing mode of service requests that are simultaneously passed to the service processor through one or more inputs.
Handling network IO connection events, read events, and write events. Three types of roles are introduced in Reactor
- reactor: monitor and allocate events, connection events are handed over to acceptor, and read and write events are handed over to handler;
- acceptor: receive connection requests, After receiving the connection, a handler will be created to handle subsequent read and write events on the network connection;
- handler: handle read and write events.
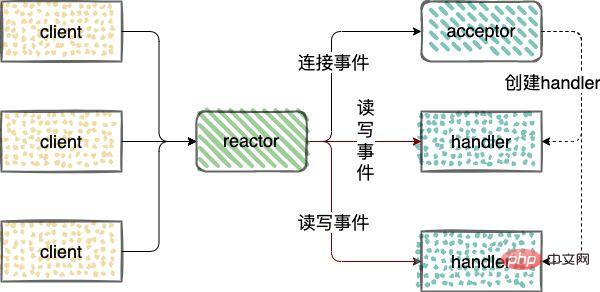
Reactor models are divided into 3 categories:
- Single-threaded Reactor mode;
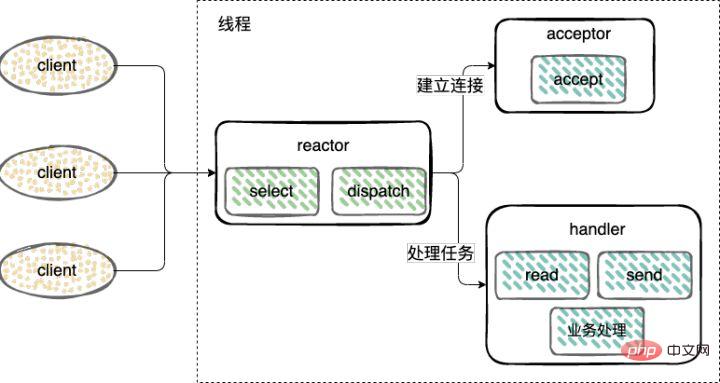
Establish a connection (Acceptor), monitor accept, read, and write events (Reactor), and process events (Handler) ) only use a single thread;
- Multi-threaded Reactor mode;
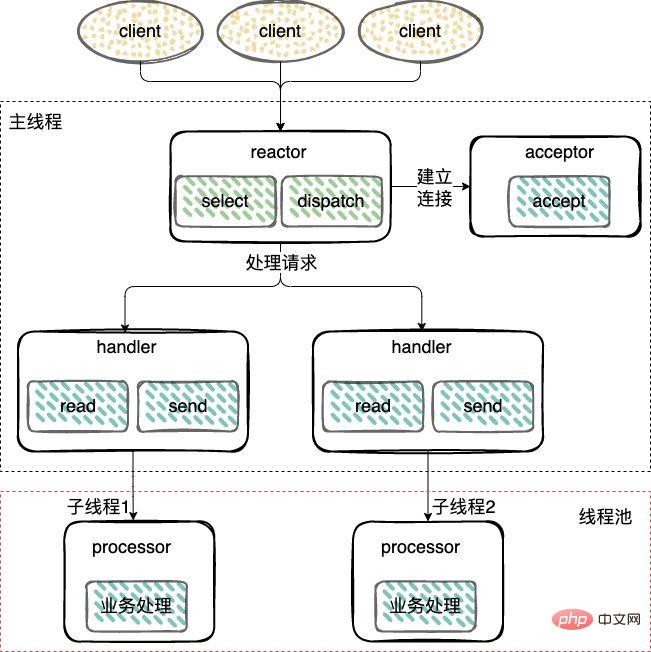
Different from the single-threaded mode, added A worker thread pool and transfers non-I/O operations from the Reactor thread to the worker thread pool (Thread Pool) for execution.
Establish a connection (Acceptor) and listen to accept, read, write events (Reactor), and reuse a thread.
Worker thread pool: handle events (Handler), a worker thread pool executes business logic, including user-mode data reading and writing after the data is ready.
- Master-slave Reactor mode;
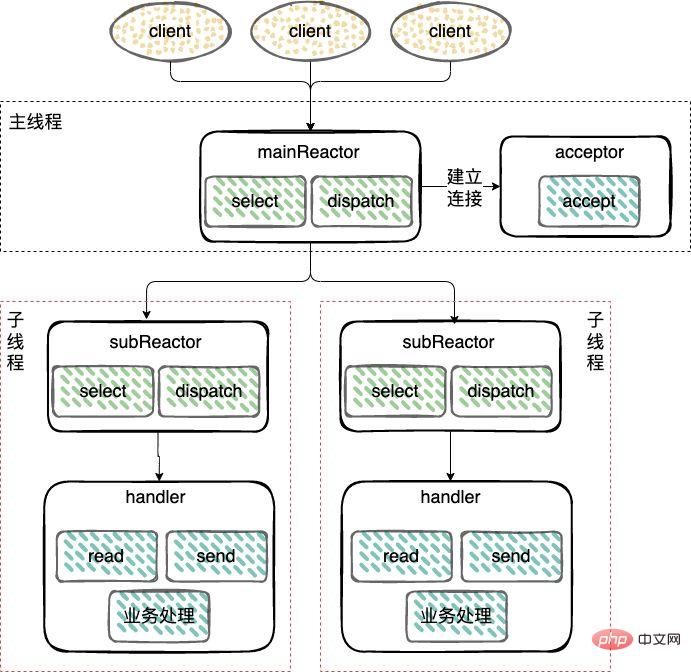
For machines with multiple CPUs, in order to make full use of system resources, the Reactor is split into Two parts: mainReactor and subReactor.
mainReactor: Responsible for monitoring server socket, used to handle the establishment of new network connections, and register the established socketChannel to the subReactor, usually one thread can handle it;
subReactor: monitor accept, read, write events (Reactor), including reading and writing data in kernel mode when waiting for data to be ready, usually using multi-threading.
Worker thread: The event processing (Handler) can use the same thread as the subReactor, or it can be made into a thread pool, similar to the processing method of the worker thread pool in the multi-threaded Reactor mode above.
Proactor mode
reactor process is similar to Reactor mode
The difference is that
- Reactor is a non-blocking synchronous network mode , what is perceived is the ready read and write event.
Every time an event is detected (such as a readable ready event), the application process needs to actively call the read method to complete the reading of data, that is, the application process must actively receive the socket. The data in the cache is read into the memory of the application process. This process is synchronous. The application process can process the data only after reading the data.
- Proactor is an asynchronous network mode and perceives completed read and write events.
When initiating an asynchronous read and write request, you need to pass in the address of the data buffer (used to store the result data) and other information, so that the system kernel can automatically help us complete the data reading and writing work. , the entire reading and writing work here is done by the operating system. It does not require the application process to actively initiate read/write like Reactor to read and write data. After the operating system completes the reading and writing work, it will notify Application processes process data directly.
Therefore, Reactor can be understood as "when an event comes, the operating system notifies the application process, and let the application process handle it", while Proactor can be understood as "when an event comes, the operating system processes it, and then notifies the application process after processing" .
To give an example in real life, the Reactor model means that the courier is downstairs and calls you to tell you that the courier has arrived in your community. You need to go downstairs to pick up the courier yourself. In Proactor mode, the courier delivers the package directly to your door and then notifies you.
Why Redis chooses single thread
Redis uses single thread, which may be due to the following considerations
1. Redis is pure memory The execution speed of the operation is very fast, so this part of the operation is usually not a performance bottleneck. The performance bottleneck lies in network I/O;
2. Avoid excessive context switching overhead. Single thread can avoid the process Frequent thread switching overhead;
3. Avoid the overhead of synchronization mechanism. Multi-threads will inevitably face access to shared resources. At this time, the usual approach is to lock. Although it is multi-threaded, it will Become a serial access. That is, the problem of concurrent access control of shared resources that multi-threaded programming mode will face;
4. Simple and maintainable. Multi-threading will also introduce synchronization primitives to protect concurrent access to shared resources and maintain the code's maintainability. and legibility will decrease.
Redis Before the v6.0 version, the core network model of Redis has always been a typical single Reactor model: using epoll/select/kqueue and other multiplexing technologies, in a single thread Events (client requests) are continuously processed in the event loop, and finally the response data is written back to the client:
Here is a look at how Redis uses a single thread to process tasks
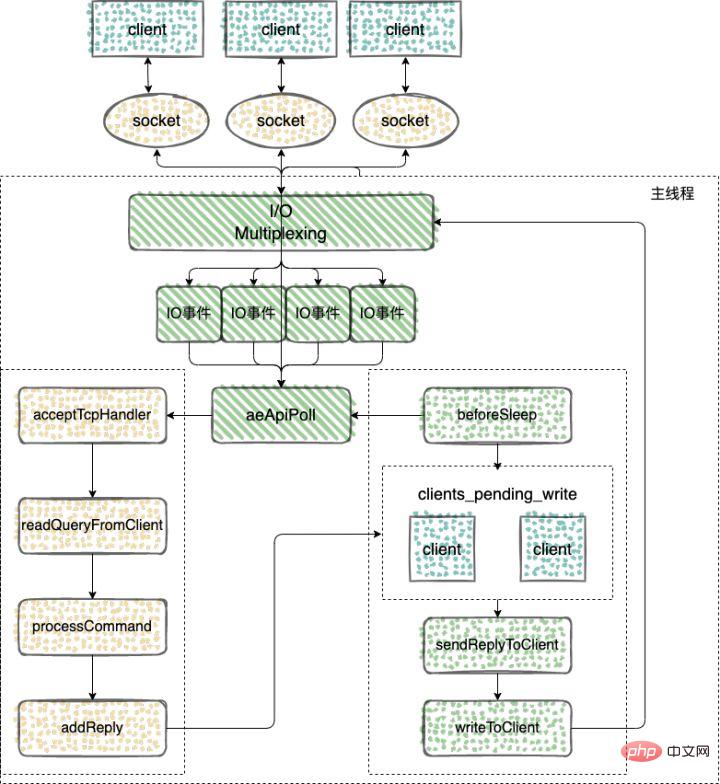
Event-driven framework captures and distributes events
The network framework of Redis implements the Reactor model, and an event-driven framework is developed and implemented by itself.
The logic of the event-driven framework is simply
- Event initialization;
- Event capture;
- Distribution and processing main loop.

Let’s take a look at several main functions implemented by the event-driven framework in Redis
// 执行事件捕获,分发和处理循环 void aeMain(aeEventLoop *eventLoop); // 用来注册监听的事件和事件对应的处理函数。只有对事件和处理函数进行了注册,才能在事件发生时调用相应的函数进行处理。 int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData); // aeProcessEvents 函数实现的主要功能,包括捕获事件、判断事件类型和调用具体的事件处理函数,从而实现事件的处理 int aeProcessEvents(aeEventLoop *eventLoop, int flags);
Use aeMain as the main loop to continuously monitor events and capture, in which the aeProcessEvents function will be called to realize event capture, determine the event type and call the specific event processing function to achieve event processing.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L496
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
// https://github.com/redis/redis/blob/5.0/src/ae.c#L358
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
//调用aeApiPoll函数捕获事件
numevents = aeApiPoll(eventLoop, tvp);
...
}
...
}You can see that the capture of IO events in aeProcessEvents is completed by calling aeApiPoll.
aeApiPoll is an I/O multiplexing API. It is an encapsulation based on system calls such as epoll_wait/select/kevent. It listens and waits for read and write events to be triggered, and then processes them. It is an event loop. The core function in (Event Loop) is the basis for event-driven operation.
Redis relies on the IO multiplexing mechanism provided by the underlying operating system to implement event capture and check whether new connections, read and write events occur. In order to adapt to different operating systems, Redis uniformly encapsulates the network IO multiplexing functions implemented by different operating systems.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L49 #ifdef HAVE_EVPORT #include "ae_evport.c" // Solaris #else #ifdef HAVE_EPOLL #include "ae_epoll.c" // Linux #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" // MacOS #else #include "ae_select.c" // Windows #endif #endif #endif
ae_epoll.c: Corresponds to the IO multiplexing function epoll on Linux;
ae_evport.c: Corresponds to the IO multiplexing function evport on Solaris;
ae_kqueue.c : Corresponds to the IO multiplexing function kqueue on macOS or FreeBSD;
ae_select.c: Corresponds to the IO multiplexing function select on Linux (or Windows).
Client connection response
Listen to the read event of the socket. When a client connection request comes, use the function acceptTcpHandler to establish a connection with the client
When Redis is started, the main function of the server program will call the initSever function for initialization. During the initialization process, aeCreateFileEvent will be called by the initServer function to register the events to be monitored and the corresponding event processing functions.
// https://github.com/redis/redis/blob/5.0/src/server.c#L2036
void initServer(void) {
...
// 创建一个事件处理程序以接受 TCP 和 Unix 中的新连接
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
...
}You can see that the initServer will call aeCreateFileEvent for network events on each IP port based on the number of enabled IP ports, create a listener for the AE_READABLE event, and register the handler for the AE_READABLE event. It is the acceptTcpHandler function.
Then take a look at the implementation of acceptTcpHandler
// https://github.com/redis/redis/blob/5.0/src/networking.c#L734
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
// 用于accept客户端的连接,其返回值是客户端对应的socket
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
// 会调用acceptCommonHandler对连接以及客户端进行初始化
acceptCommonHandler(cfd,0,cip);
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L664
static void acceptCommonHandler(int fd, int flags, char *ip) {
client *c;
// 分配并初始化新客户端
if ((c = createClient(fd)) == NULL) {
serverLog(LL_WARNING,
"Error registering fd event for the new client: %s (fd=%d)",
strerror(errno),fd);
close(fd); /* May be already closed, just ignore errors */
return;
}
// 判断当前连接的客户端是否超过最大值,如果超过的话,会拒绝这次连接。否则,更新客户端连接数的计数
if (listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
if (write(c->fd,err,strlen(err)) == -1) {
/* Nothing to do, Just to avoid the warning... */
}
server.stat_rejected_conn++;
freeClient(c);
return;
}
...
}
// 使用多路复用,需要记录每个客户端的状态,client 之前通过链表保存
typedef struct client {
int fd; // 字段是客户端套接字文件描述符
sds querybuf; // 保存客户端发来命令请求的输入缓冲区。以Redis通信协议的方式保存
int argc; // 当前命令的参数数量
robj **argv; // 当前命令的参数
redisDb *db; // 当前选择的数据库指针
int flags;
list *reply; // 保存命令回复的链表。因为静态缓冲区大小固定,主要保存固定长度的命令回复,当处理一些返回大量回复的命令,则会将命令回复以链表的形式连接起来。
// ... many other fields ...
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 如果fd为-1,表示创建的是一个无网络连接的伪客户端,用于执行lua脚本的时候。
// 如果fd不等于-1,表示创建一个有网络连接的客户端
if (fd != -1) {
// 设置fd为非阻塞模式
anetNonBlock(NULL,fd);
// 禁止使用 Nagle 算法,client向内核递交的每个数据包都会立即发送给server出去,TCP_NODELAY
anetEnableTcpNoDelay(NULL,fd);
// 如果开启了tcpkeepalive,则设置 SO_KEEPALIVE
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
// 创建一个文件事件状态el,且监听读事件,开始接受命令的输入
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
...
// 初始化client 中的参数
return c;
}1. AcceptTcpHandler is mainly used to handle the establishment of a connection with the client;
2. The function anetTcpAccept is called to accept the client The return value is the socket corresponding to the client;
3. Then call acceptCommonHandler to initialize the connection and the client;
4. When initializing the client, use aeCreateFileEvent at the same time. Register the monitored events and the processing functions corresponding to the events, and bind the readQueryFromClient command read processor to the file descriptor corresponding to the new connection;
5. The server will monitor the read event of the file descriptor. When The client sends a command and triggers the AE_READABLE event, then the callback function readQueryFromClient() is called to read the command from the file descriptor fd and save it in the input buffer querybuf.
Reception of commands
readQueryFromClient is the starting point of request processing, parsing and executing the client's request command.
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1522
// 读取client的输入缓冲区的内容
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = (client*) privdata;
int nread, readlen;
size_t qblen;
UNUSED(el);
UNUSED(mask);
...
// 输入缓冲区的长度
qblen = sdslen(c->querybuf);
// 更新缓冲区的峰值
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
// 扩展缓冲区的大小
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
// 调用read从描述符为fd的客户端socket中读取数据
nread = read(fd, c->querybuf+qblen, readlen);
...
// 处理读取的内容
processInputBufferAndReplicate(c);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1507
void processInputBufferAndReplicate(client *c) {
// 当前客户端不属于主从复制中的Master
// 直接调用 processInputBuffer,对客户端输入缓冲区中的命令和参数进行解析
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
// 客户端属于主从复制中的Master
// 调用processInputBuffer函数,解析客户端命令,
// 调用replicationFeedSlavesFromMasterStream 函数,将主节点接收到的命令同步给从节点
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1428
void processInputBuffer(client *c) {
server.current_client = c;
/* Keep processing while there is something in the input buffer */
// 持续读取缓冲区的内容
while(c->qb_pos < sdslen(c->querybuf)) {
...
/* Multibulk processing could see a <= 0 length. */
// 如果参数为0,则重置client
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
// 执行命令成功后重置client
if (processCommand(c) == C_OK) {
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
/* Update the applied replication offset of our master. */
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
// 命令处于阻塞状态中的客户端,不需要进行重置
if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE)
resetClient(c);
}
/* freeMemoryIfNeeded may flush slave output buffers. This may
* result into a slave, that may be the active client, to be
* freed. */
if (server.current_client == NULL) break;
}
}
/* Trim to pos */
if (server.current_client != NULL && c->qb_pos) {
sdsrange(c->querybuf,c->qb_pos,-1);
c->qb_pos = 0;
}
server.current_client = NULL;
}1. readQueryFromClient(), reads data from the file descriptor fd into the input buffer querybuf;
2. Use the processInputBuffer function to complete the parsing of the command, and use processInlineBuffer in it Or processMultibulkBuffer parses the command according to the Redis protocol;
3. After completing the parsing of a command, use processCommand to execute the command;
4. After the command execution is completed, finally call a member of the addReply function family The series of functions writes the response data to the write buffer corresponding to the client: client->buf or client->reply. client->buf is the preferred write buffer, with a fixed size of 16KB. Generally speaking, it can be buffered. Enough response data, but if the client needs to respond to very large data within the time window, it will automatically switch to the client->reply linked list. The use of linked lists can theoretically save infinitely large data (limited by the machine physical memory), and finally add the client to a LIFO queue clients_pending_write;
Command reply
Before the Redis event-driven framework enters the event processing function each time it loops, Before processing the monitored triggered event or the timed event, the beforeSleep function will be called to perform some task processing, which includes calling the handleClientsWithPendingWrites function, which will Redis sever client buffer The data in the zone is written back to the client.
// https://github.com/redis/redis/blob/5.0/src/server.c#L1380
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
...
// 将 Redis sever 客户端缓冲区中的数据写回客户端
handleClientsWithPendingWrites();
...
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1082
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
// 遍历 clients_pending_write 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
...
// 调用 writeToClient 函数,将客户端输出缓冲区中的数据写回
if (writeToClient(c->fd,c,0) == C_ERR) continue;
// 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就
// 会调用 aeCreateFileEvent 函数,创建可写事件,并设置回调函数 sendReplyToClien
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
// 将文件描述符fd和AE_WRITABLE事件关联起来,当客户端可写时,就会触发事件,调用sendReplyToClient()函数,执行写事件
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1072
// 写事件处理程序,只是发送回复给client
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
UNUSED(el);
UNUSED(mask);
writeToClient(fd,privdata,1);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L979
// 将输出缓冲区的数据写给client,如果client被释放则返回C_ERR,没被释放则返回C_OK
int writeToClient(int fd, client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
size_t objlen;
clientReplyBlock *o;
// 如果指定的client的回复缓冲区中还有数据,则返回真,表示可以写socket
while(clientHasPendingReplies(c)) {
// 固定缓冲区发送未完成
if (c->bufpos > 0) {
// 将缓冲区的数据写到fd中
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
...
// 如果发送的数据等于buf的偏移量,表示发送完成
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
// 固定缓冲区发送完成,发送回复链表的内容
} else {
// 回复链表的第一条回复对象,和对象值的长度和所占的内存
o = listNodeValue(listFirst(c->reply));
objlen = o->used;
if (objlen == 0) {
c->reply_bytes -= o->size;
listDelNode(c->reply,listFirst(c->reply));
continue;
}
// 将当前节点的值写到fd中
nwritten = write(fd, o->buf + c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
...
}
...
}
...
// 如果指定的client的回复缓冲区中已经没有数据,发送完成
if (!clientHasPendingReplies(c)) {
c->sentlen = 0;
// 删除当前client的可读事件的监听
if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
/* Close connection after entire reply has been sent. */
// 如果指定了写入按成之后立即关闭的标志,则释放client
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) {
freeClient(c);
return C_ERR;
}
}
return C_OK;
}1. The handleClientsWithPendingWrites function called by the beforeSleep function will traverse the clients_pending_write (client to be written back data) queue, call writeToClient to write the data in the client's write buffer back to the client, and then call writeToClient function, sends the data in the client output buffer to the client;
2、如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
上面的执行流程总结下来就是
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理,这个函数会解析 client 的数据,找到对应的 cmd 函数执行;
3、cmd 逻辑执行完成后,server 需要写回数据给 client,调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
4、在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将 Redis sever 客户端缓冲区中的数据写回客户端;
- beforeSleep 函数调用的 handleClientsWithPendingWrites 函数,会遍历 clients_pending_write(待写回数据的客户端) 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,然后调用 writeToClient 函数,将客户端输出缓冲区中的数据发送给客户端;
- 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
Redis 多IO线程
在 Redis6.0 的版本中,引入了多线程来处理 IO 任务,多线程的引入,充分利用了当前服务器多核特性,使用多核运行多线程,让多线程帮助加速数据读取、命令解析以及数据写回的速度,提升 Redis 整体性能。
Redis6.0 之前的版本用的是单线程 Reactor 模式,所有的操作都在一个线程中完成,6.0 之后的版本使用了主从 Reactor 模式。
由一个 mainReactor 线程接收连接,然后发送给多个 subReactor 线程处理,subReactor 负责处理具体的业务。
来看下 Redis 多IO线程的具体实现过程
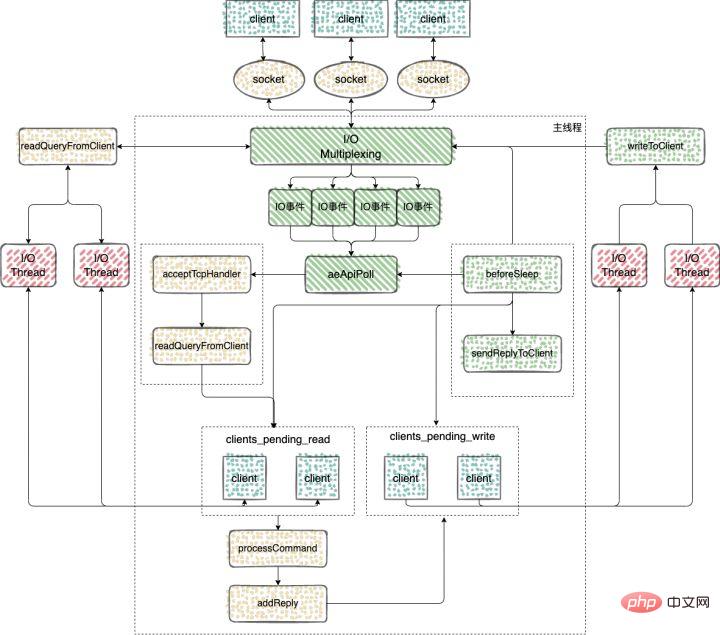
多 IO 线程的初始化
使用 initThreadedIO 函数来初始化多 IO 线程。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
// 编号为0是主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
// 初始化io_threads_mutex数组
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 初始化io_threads_pending数组
setIOPendingCount(i, 0);
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}可以看到在 initThreadedIO 中完成了对下面四个数组的初始化工作
io_threads_list 数组:保存了每个 IO 线程要处理的客户端,将数组每个元素初始化为一个 List 类型的列表;
io_threads_pending 数组:保存等待每个 IO 线程处理的客户端个数;
io_threads_mutex 数组:保存线程互斥锁;
io_threads 数组:保存每个 IO 线程的描述符。
命令的接收
Redis server 在和一个客户端建立连接后,就开始了监听客户端的可读事件,处理可读事件的回调函数就是 readQueryFromClient
// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
// 判断是否从客户端延迟读取数据
if (postponeClientRead(c)) return;
...
}
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3746
int postponeClientRead(client *c) {
// 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
// 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作
c->flags |= CLIENT_PENDING_READ;
// 将可获得加入clients_pending_write列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}使用 clients_pending_read 保存了需要进行延迟读操作的客户端之后,这些客户端又是如何分配给多 IO 线程执行的呢?
handleClientsWithPendingWritesUsingThreads 函数:该函数主要负责将 clients_pending_write 列表中的客户端分配给 IO 线程进行处理。
看下如何实现
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766
int handleClientsWithPendingReadsUsingThreads(void) {
// 当多线程 I/O 模式开启,才能执行下面的流程
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
// 遍历待读取的 client 队列 clients_pending_read,
// 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算
// 取模的结果就是客户端分配给对应IO线程的编号
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作:只读取和解析命令,不执行
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,等待所有 IO 线程完成待读客户端的处理
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记,
// 然后解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
serverAssert(!(c->flags & CLIENT_BLOCKED));
// client 的第一条命令已经被解析好了,直接尝试执行。
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
// 解析并执行 client 命令
processInputBuffer(c);
// 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}1、当客户端发送命令请求之后,会触发 Redis 主线程的事件循环,命令处理器 readQueryFromClient 被回调,多线程模式下,则会把 client 加入到 clients_pending_read 任务队列中去,后面主线程再分配到 I/O 线程去读取客户端请求命令;
2、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
3、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
4、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
命令的回复
完成命令的读取、解析以及执行之后,客户端命令的响应数据已经存入 client->buf 或者 client->reply 中。
主循环在捕获 IO 事件的时候,beforeSleep 函数会被调用,进而调用 handleClientsWithPendingWritesUsingThreads ,写回响应数据给客户端。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client
// 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠,
// 直接在主线程把所有 client 的相应数据回写到客户端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */
// 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。
// 可以看到写回操作也是多线程执行的
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
// 等待所有的线程完成对应的工作
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据,
// 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}1、也是会将 client 分配给所有的 IO 线程;
2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
通过上面的分析可以得出结论,Redis 多IO线程中多线程的应用
1、解析客户端的命令的时候用到了多线程,但是对于客户端命令的执行,使用的还是单线程;
2、给客户端回复数据的时候,使用到了多线程。
来总结下 Redis 中多线程的执行过程
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理;
3、客户端发送给服务端的数据,不会类似 6.0 之前的版本使用 socket 直接去读,而是会将 client 放入到 clients_pending_read 中,里面保存了需要进行延迟读操作的客户端;
4、处理 clients_pending_read 的函数 handleClientsWithPendingReadsUsingThreads,在每次事件循环的时候都会调用;
- 1、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
- 2、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
- 3、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
5、命令执行完成以后,回复的内容还是会被写入到 client 的缓存区中,这些 client 和6.0之前的版本处理方式一样,也是会被放入到 clients_pending_write(待写回数据的客户端);
6、6.0 对于clients_pending_write 的处理使用到了多线程;
- 1、也是会将 client 分配给所有的 IO 线程;
- 2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
- 3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
原子性的单命令
通过上面的分析,我们知道,Redis 的主线程是单线程执行的,所有 Redis 中的单命令,都是原子性的。
所以对于一些场景的操作尽量去使用 Redis 中单命令去完成,就能保证命令执行的原子性。
比如对于上面的读取-修改-写回操作可以使用 Redis 中的原子计数器, INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1) 等命令。
这些命令可以直接帮助我们处理并发控制
127.0.0.1:6379> incr test-1 (integer) 1 127.0.0.1:6379> incr test-1 (integer) 2 127.0.0.1:6379> incr test-1 (integer) 3
分析下源码,看看这个命令是如何实现的
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L617
void incrCommand(client *c) {
incrDecrCommand(c,1);
}
void decrCommand(client *c) {
incrDecrCommand(c,-1);
}
void incrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,incr);
}
void decrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,-incr);
}可以看到 INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1)这几个命令最终都是调用的 incrDecrCommand
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L579
void incrDecrCommand(client *c, long long incr) {
long long value, oldvalue;
robj *o, *new;
// 查找有没有对应的键值
o = lookupKeyWrite(c->db,c->argv[1]);
// 判断类型,如果value对象不是字符串类型,直接返回
if (checkType(c,o,OBJ_STRING)) return;
// 将字符串类型的value转换为longlong类型保存在value中
if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;
// 备份旧的value
oldvalue = value;
// 判断 incr 的值是否超过longlong类型所能表示的范围
// 长度的范围,十进制 64 位有符号整数
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
// 计算新的 value值
value += incr;
if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT &&
(value < 0 || value >= OBJ_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
new = o;
o->ptr = (void*)((long)value);
} else {
new = createStringObjectFromLongLongForValue(value);
// 如果之前的 value 对象存在
if (o) {
// 重写为 new 的值
dbOverwrite(c->db,c->argv[1],new);
} else {
// 如果之前没有对应的 value,新设置 value 的值
dbAdd(c->db,c->argv[1],new);
}
}
// 进行通知
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id);
server.dirty++;
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
}总结
1、Redis 中的命令执行都是单线程的,所以单命令的执行都是原子性的;
2、虽然 Redis6.0 版本引入了多线程,但是仅是在接收客户端的命令和回复客户端的数据用到了多线程,实际命令的执行还是单线程在处理;
推荐学习:Redis视频教程
The above is the detailed content of Detailed analysis of the atomicity of commands in Redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
