

Python automation practice for screening resumes

This article brings you relevant knowledge about python, which mainly introduces issues related to resume screening, including defining the ReadDoc class to read word files and defining the search_word function. Let’s take a look at the relevant content of the screening. I hope it will be helpful to everyone.

Recommended learning: python video tutorial
Resume screening
The relevant resume information is as follows:

Define the ReadDoc class to read word files
Known conditions:
Want to find files containing the specified Keyword resume (such as Python, Java)
Implementation idea:
Read each word file in batches (obtain word information through glob), and combine all their readable contents Obtain and filter through keywords to get the target resume address.
One thing to note here is that not all "resumes" are presented in the form of paragraphs. For example, the resume downloaded from the "Liepin" website is " "Tabular format", and the resume downloaded from "boss" is in "paragraph format". You need to pay attention when reading it here. The demonstration script exercise we did is in "table format".
Here, we can specifically define a "ReadDoc" class, which defines two functions for reading "paragraphs" and "tables".
The practical case script is as follows:
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + '\n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + '\n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
Look at the running results of the ReadDoc class
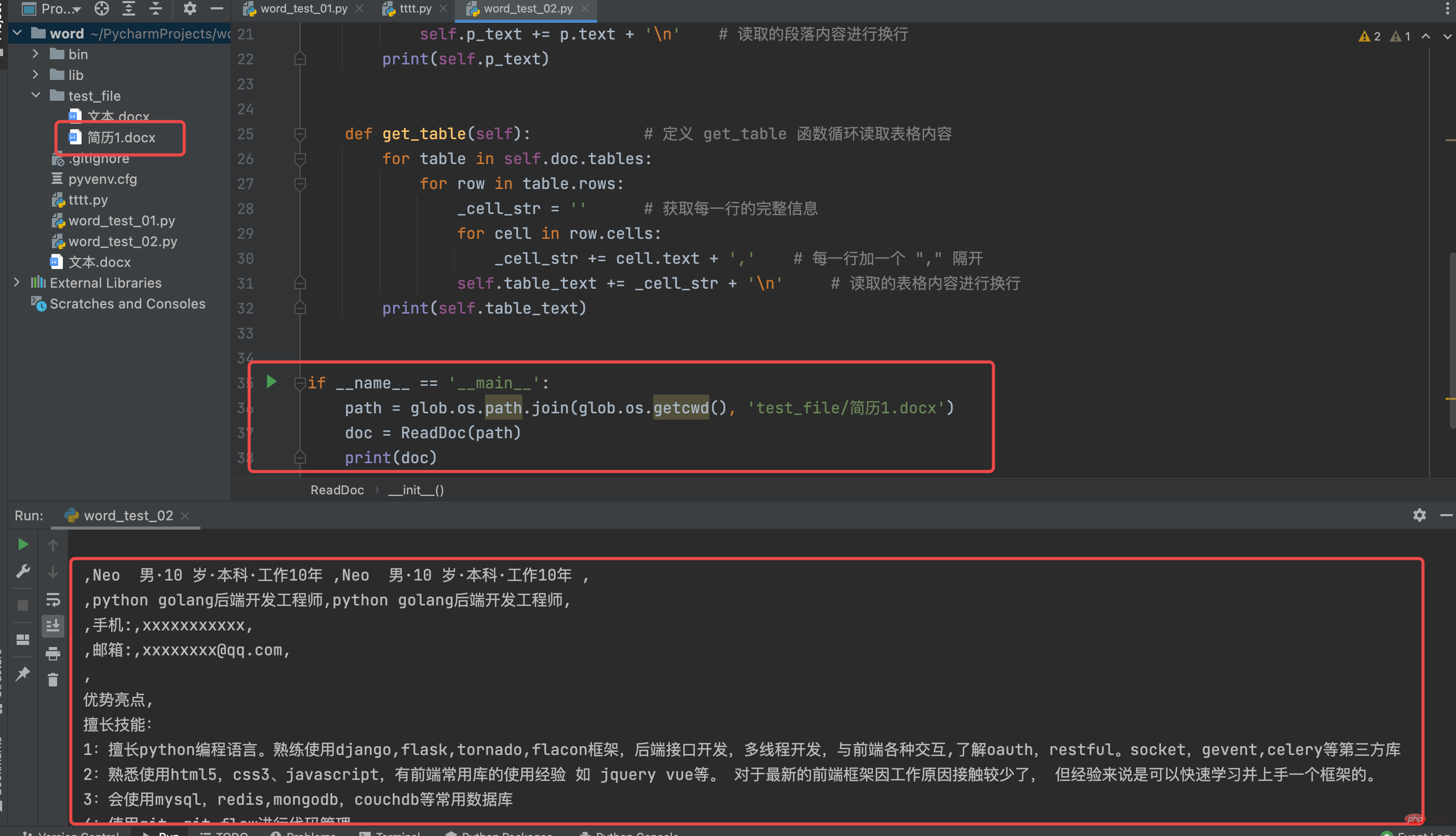
Define the search_word function to filter the word file content to match the desired resume
OK, the above has successfully read the word document of the resume, next we will read The obtained content is filtered out by selecting keyword information, and resumes containing keywords are filtered out.
The practical case script is as follows:
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
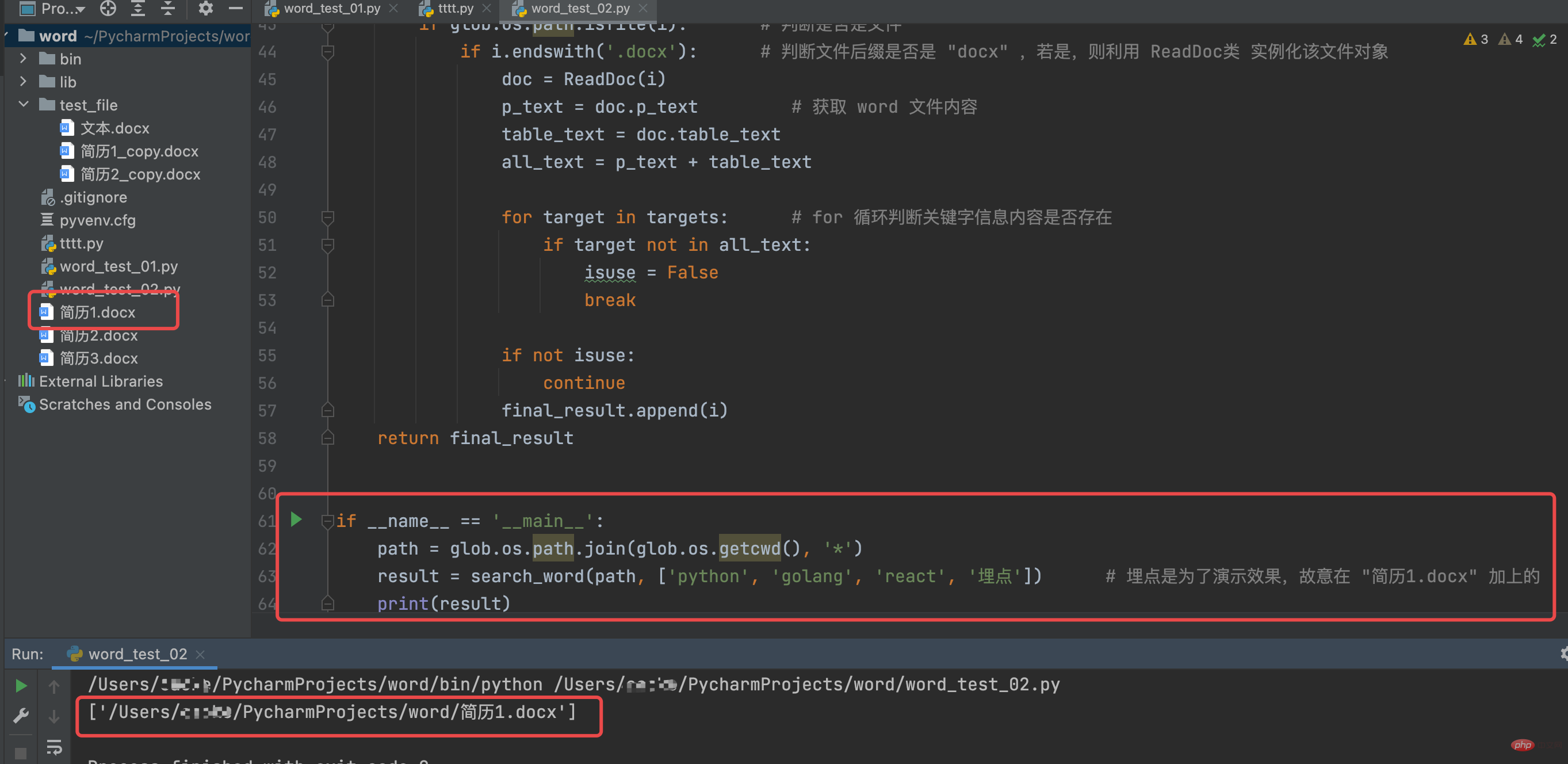
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)The running results are as follows:
Recommended learning: python video tutorial
The above is the detailed content of Python automation practice for screening resumes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
