

Selected and summarized 15 Mysql optimization issues

This article brings you relevant knowledge about mysql, which mainly introduces issues related to SQL optimization, including how to troubleshoot SQL statements during the development process and how to troubleshoot the production environment. Let’s take a look at SQL problems and so on. I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
How to troubleshoot SQL during the development process?
Troubleshooting Ideas
For most programmers, troubleshooting SQL during the development process is basically blank. However, with the involution of the industry, more and more attention and professionalism are paid to the development process. One of them is to solve SQL problems as much as possible during the development process to avoid exposing SQL problems during production. So how to conveniently conduct SQL troubleshooting of the program during the development process?
The idea is still to use Mysql's slow log to achieve:
-
First of all, during the development process, you also need to enable the slow query of the database Mysql
SET GLOBAL slow_query_log='on';
Copy after loginCopy after login -
Secondly set the minimum time for slow SQL
Note: The time unit here is s seconds but there are 6 decimal places so it can express subtle time intensity. Generally The SQL execution time of a single table is preferably within 20ms. On the contrary, the understanding is that during the development process, if the SQL statement you execute exceeds 20ms, you need to pay attention to it.
SET GLOBAL long_query_time=0.02;
Copy after loginCopy after login -
For the convenience of operation, slow SQL can be recorded in the table instead of the file
SET GLOBAL log_output='TABLE';
Copy after login Finally, the recorded slow SQL can be queried through the mysql.slow_log table
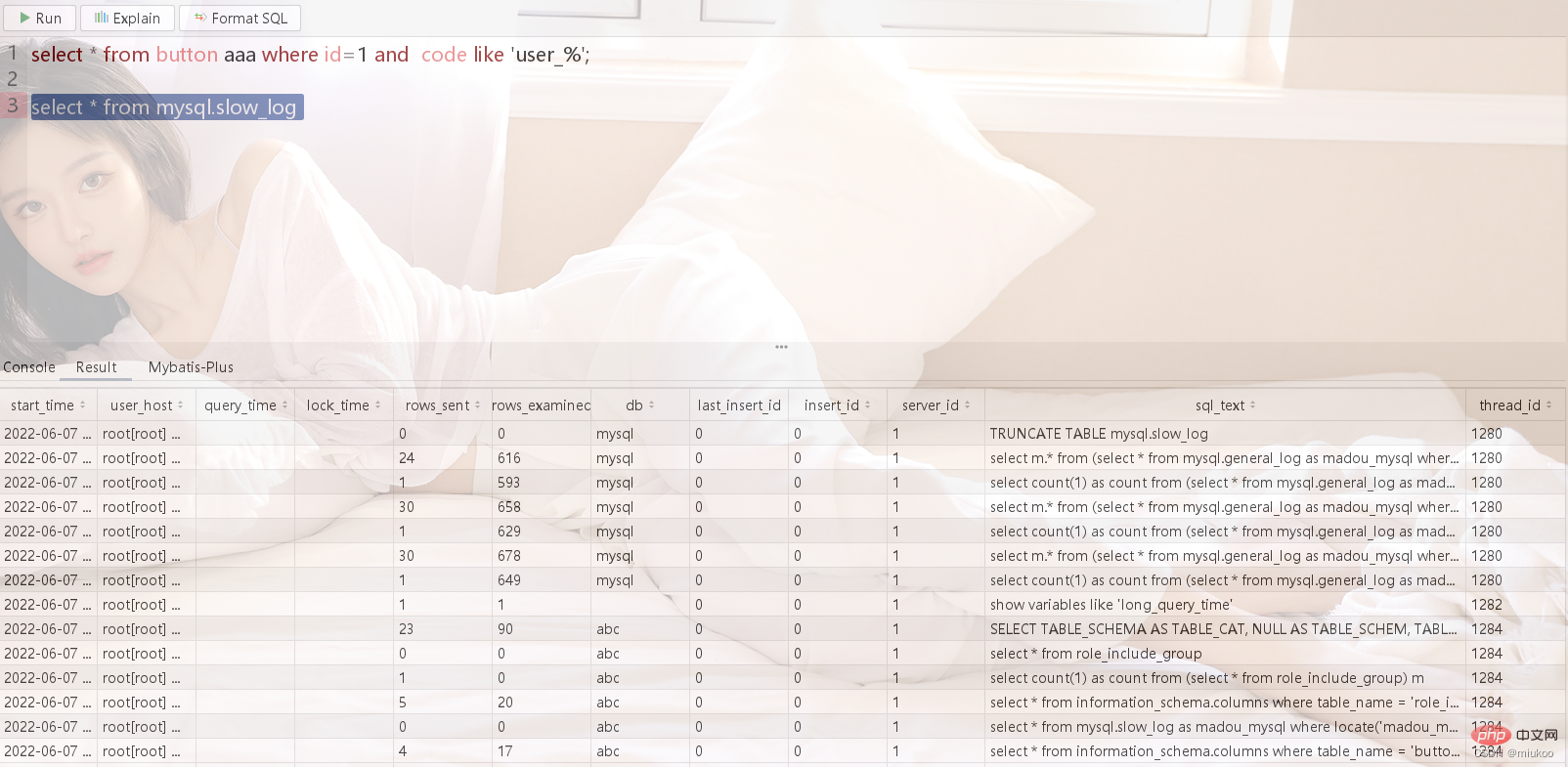
Using tools
developed for everyone by Brother Yong The software also provides a graphical interface to help you quickly implement the above functions with one click.
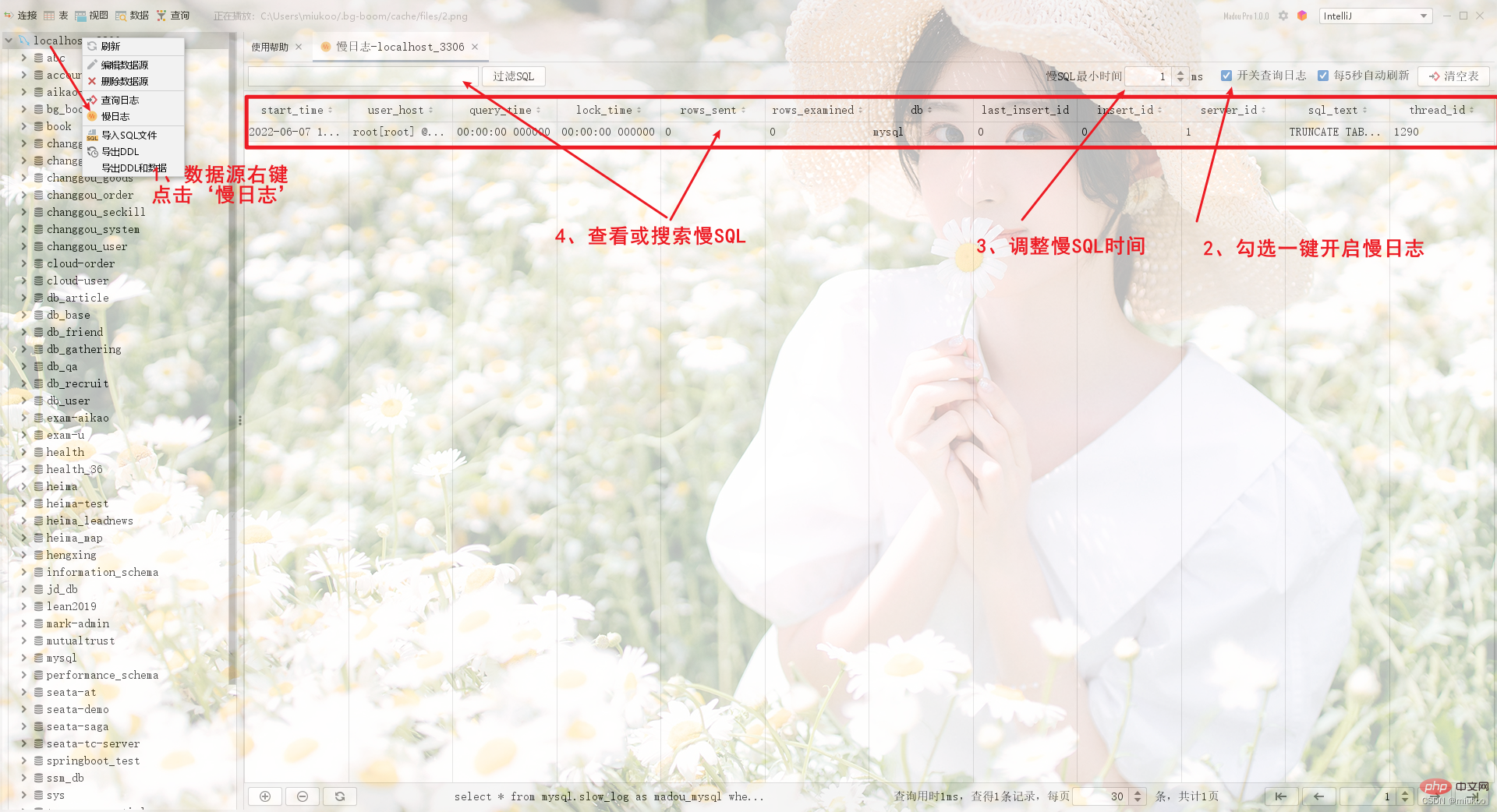
How to troubleshoot SQL problems in production environment?
Troubleshooting ideas
The troubleshooting of generated SQL problems is relatively complicated, but the overall idea is to troubleshoot through slow SQL. The specific ideas are as follows:
-
First enable the slow query of database Mysql
SET GLOBAL slow_query_log='on';
Copy after loginCopy after login -
Secondly set the minimum time for slow SQL
SET GLOBAL long_query_time=0.02;
Copy after loginCopy after login -
Generally put slow SQL in File
SET GLOBAL log_output='FILE';
Copy after login Download the slow SQL log file to the local
-
Finally close the slow query of the database Mysql
Important note: It is best to open the slow SQL for production only when using it, and close it after use to avoid logging from affecting business performance
SET GLOBAL slow_query_log='off';
Copy after login
How to tune SQL?
SQL tuning integrates multiple aspects of knowledge. Generally speaking, it is common to optimize from two aspects: table structure and table index.
Table structure optimization
1. Reasonable use of field classes and lengths
An example to understand: Just a gender field, stored with tinyint(1) It occupies 1 byte, and int(1) storage occupies 4 bytes. If there are 1 million records, then the table file stored in int is about 2.8M larger than the table file stored in tinyint. Therefore, when reading the int type stored The table file is large and the reading speed is slower than reading tinyint. This is actually the essence of why it is necessary to use field type lengths rationally: to reduce the size of stored files to provide read performance.
Of course, some friends may say that 2.8M does not affect the overall situation, so it can be ignored. Brother Yong would like to add something to this idea: Suppose a table has 10 fields, and your system has a total of 30 tables. Then let’s take a look at the extra file size? (2.8Mx10x30=840M, it will take several seconds to download 840M using Thunder Super. This time is considered very slow in the computer...)
2. Reasonable use of redundant design
2.1. Redundant design background - temporary table
There is a special and lightweight temporary table inside Mysql, which is automatically created and deleted by Mysql. Temporary tables are mainly used during the execution of SQL to store the intermediate results of certain operations. This process is automatically completed by MySQL and users cannot intervene manually, and this internal table is invisible to users.
Internal temporary tables are very important in the optimization process of SQL statements. Many operations in MySQL rely on internal temporary tables for optimization operations. However, using internal temporary tables requires the cost of creating tables and accessing intermediate data, so should try to avoid using temporary tables when writing SQL statements.
So in those scenarios, will Mysql use temporary tables internally?
In multi-table related queries (JOIN), the columns used in order by or group by are not columns of the first table
When the column grouped by is not an index column
Distinct and group by are used together
The distinct keyword is used in the order by statement
group by The columns are index columns, but the amount of data is too large
2.2. How to check whether an internal temporary table is used?
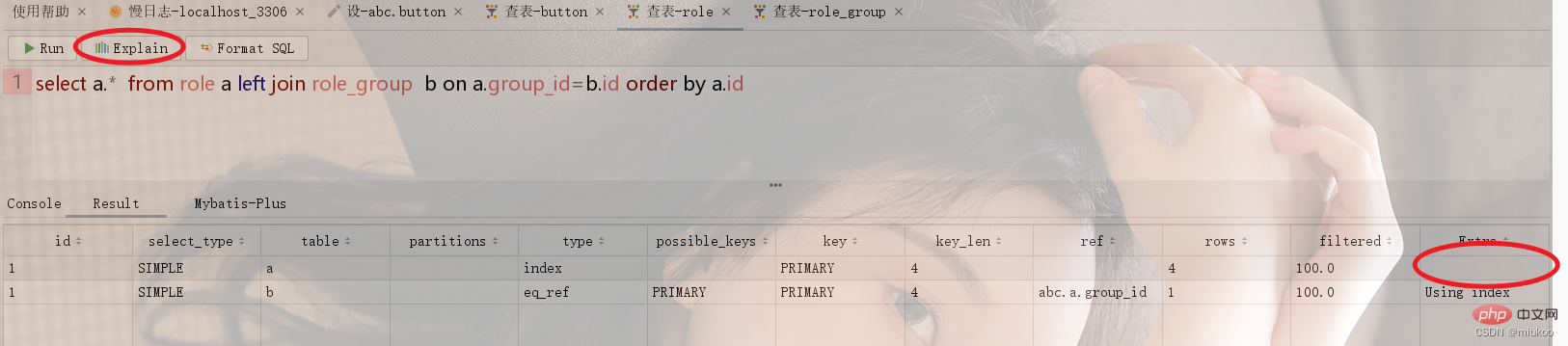
Use the Explain keyword or the function button of the tool to view the execution process of SQL. If the Using temporary keyword appears in the Extra column in the result, it means that your SQL statement uses a temporary table when executing.
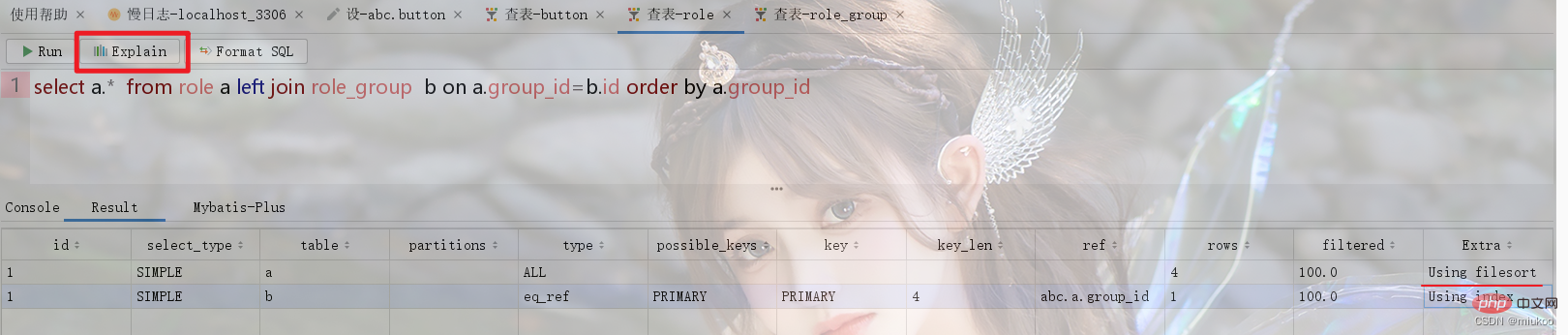
As shown below, the role Role table and the role group Role_Group have a many-to-1 relationship. When performing related queries, the temporary table will be used to sort by the id of role_group (see Figure 1 below). If the sorting is done using The role's id will not use the temporary table (see Figure 2).
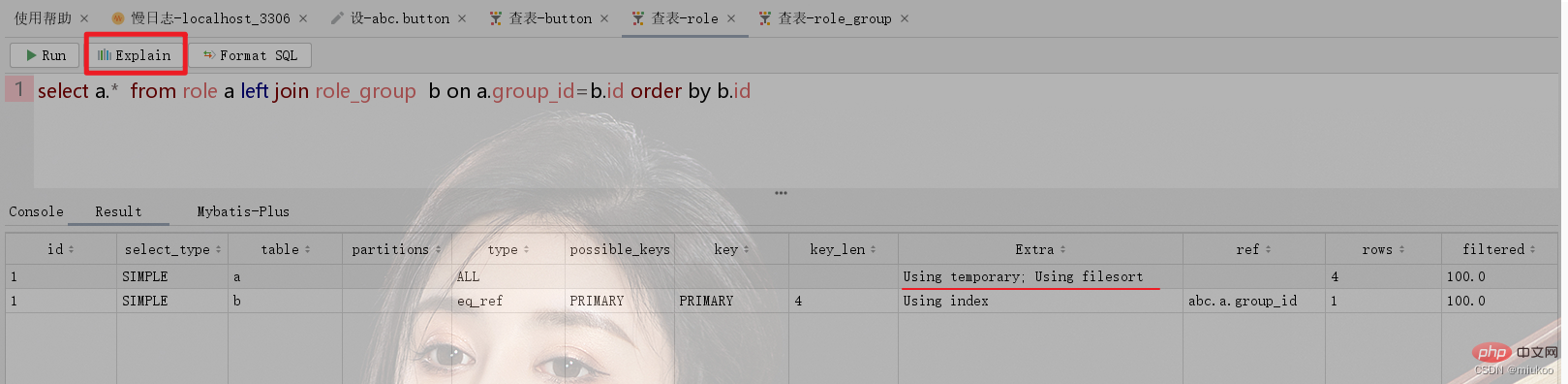
2.3. How to solve the problem of not using internal temporary tables?
There are two solutions to this problem. One is to adjust the SQL statement to avoid using temporary tables, and the other is to store redundantly in the table. For example, in the example of Figure 1 in 2.2, if you must sort by the id of role_group, you can sort by the group_id in the role table, and this column is the id column value in the role_group table that is redundantly stored.
3. Reasonable use of sub-database and table sub-database
Sub-database and sub-table are not only used for optimization in large quantities, but vertical table sub-tables can also be used. Use it under SQL tuning. (I won’t explain the vertical and horizontal sub-tables here. If you are interested, please send me a private message)
For example: the general design of an article table will not include the large field of article content.

The large field of article content is placed in a separate table

Why should the article table use the above What about designing without merging fields into one table?
Let’s first calculate a math problem. Assume that an article is 1M in size, with the article content 824KB and the remaining fields 200KB. There are a total of 1 million such articles, then:
Option 1, if a table is used for storage, the table size is 100W*1M=100WM
Option 2, if vertical table storage is used, the basic The table is 200KBx100W, and the content table is 824KBx100W
We have two pages of article list and article details on the front end. We need to directly query the relevant content from the database, then:
Plan one, the article list and article details will be queried from 100WM data
Plan 2, the article list will be queried from 200KBx100W, and the article details will be queried from 824KBx100W Query from 200KBx100W (currently you may also need to query from 200KBx100W)
Having said this, I believe everyone should have a clear answer in their minds! Vertical table splitting allows different amounts of data to be queried in different business scenarios. Often this data amount is smaller than the total table data amount, which is more flexible and efficient than querying from a fixed large or small amount.
Table index optimization
1. Reasonably add index columns
Most people’s understanding of indexes is that “indexes can speed up queries. "Speed", however Brother Yong would like to add the second half of this sentence"Indexes can speed up the query, but also slow down the speed of data insertion or modification".
If a table has 5 indexes, then you can simply regard an index as a table, then there will be 1 table and 6 index tables = equivalent to 6 tables, then these 6 tables When will it operate? Let’s calculate it:
insert operation, after data insertion, you need to insert index data into 5 index tables
delete operation, data After deletion, you need to delete the indexes in the 5 index tables
-
update operation
If the data of the index column is modified, first To modify the data, you also need to modify the index in the index table
If the data in the index column is not modified, only the data table is modified
-
select operation
If the query index is hit, query the index first, and then query the data table
If the query index is not hit, Then directly check the data table
Through the above calculation, you will magically find that the more the number of indexes, the better for insert and delete , The update operation has an impact, and it has a negative impact. Therefore, may assess that the impact of the index is less than the benefit of the query, and then add it instead of blindly adding .
2、合理的调配复合索引列个数和顺序
复合索引指的是包括有多个列的索引,它能有效的减少表的索引个数,平衡了多个字段需要多个索引直接的性能平衡,但是再使用复合索引的时候,需要注意索引列个数和顺序的问题。
先说列个数的问题,指的是一个复合索引中包括的列字段太多影响性能的问题,主要是对update操作的性能影响,如下红字:
如果修改了索引列的数据,则先修改数据,还需要修改索引表中的索引,如果索引列个数越多则修改该索引的概率越大
如果没有修改索引列的数据,则只修改数据表
再说复合索引中列顺序的问题,是指索引的最左匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,这个比较容易理解,就不多做阐述。
那些情况索引会失效?
索引无法存储null值,当使用is null或is not nulli时会全表扫描
like查询以"%"开头
对于复合索引,查询条件中没有给出索引中第一列的值时
mysql内部评估全表扫描比索引快时
or、!=、<>、in、not in等查询也可能引起索引失效
表设计有那些规范?
建表规约
表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型为
unsigned tinyint。 说明:任何字段如果为非负数,则必须是 unsigned。-
字段允许适当冗余,以提高查询性能,但必须考虑数据一致。e.g. 商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称,
避免关联查询
。冗余字段遵循:
不是频繁修改的字段;
不是 varchar 超长字段,更不能是 text 字段。
索引规约
在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
页面搜索严禁左模糊或者全模糊,如果需要请通过搜索引擎来解决。 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
-
如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
正例:where a=? and b=? order by c; 索引: a_b_c。
反例:索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b; 索引 a_b 无法排序。
利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 的行,返回 N 行。当 offset 特别大的时候,效率会非常的低下,要么控制返回的总页数,要么对超过阈值的页数进行 SQL 改写。
建组合索引的时候,区分度最高的在最左边。
SQL 性能优化的目标,至少要达到 range 级别,要求是 ref 级别,最好是 consts。
SQL 语句
不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语句,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
count(distinct column)计算该列除 NULL 外的不重复行数。注意,count(distinct column1,column2)如果其中一列全为 NULL,那么即使另一列用不同的值,也返回为 0。当某一列的值全为 NULL 时,
count(column)的返回结果为 0,但sum(column)的返回结果为 NULL,因此使用 sum() 时需注意 NPE 问题。 可以使用如下方式来避免 sum 的 NPE 问题。
SELECT IF(ISNULL(SUM(g), 0, SUM(g))) FROM table;
使用
ISNULL()来判断是否为 NULL 值。 说明:NULL 与任何值的直接比较都为 NULL。Foreign keys and cascades must not be used, and all foreign key concepts must be resolved at the application layer. Explanation: Take the relationship between students and grades as an example. The student_id of the student table is the primary key, and the student_id of the grade table is the foreign key. If the student_id in the student table is updated, the update of student_id in the grade table is also triggered, which is cascade update. Foreign keys and cascade updates are suitable for low concurrency on a single machine, but are not suitable for distributed and high-concurrency clusters; cascade updates are strongly blocking and have the risk of database update storms; foreign keys affect the insertion speed of the database.
The use of stored procedures is prohibited. Stored procedures are difficult to debug and extend, and they are not portable.
#inAvoid the operation if it can be avoided. If it cannot be avoided, you need to carefully evaluate the number of collection elements after in and control it within 1000.
ORM Mapping
The Boolean attributes of the POJO class cannot be added with is, but the database fields must be added with is_, which requires fields and attributes in the resultMap of mapping.
sql.xmlConfiguration parameters use:#{}, #param#, do not use ${}, this method is easy to occur SQL injection.@TransactionalDon’t abuse transactions. Transactions affect the QPS of the database. In addition, where transactions are used, various aspects of rollback solutions need to be considered, including cache rollback, search engine rollback, message compensation, statistical correction, etc.
Recommended learning: mysql video tutorial
The above is the detailed content of Selected and summarized 15 Mysql optimization issues. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to view sql database error
Apr 10, 2025 pm 12:09 PM
How to view sql database error
Apr 10, 2025 pm 12:09 PM
The methods for viewing SQL database errors are: 1. View error messages directly; 2. Use SHOW ERRORS and SHOW WARNINGS commands; 3. Access the error log; 4. Use error codes to find the cause of the error; 5. Check the database connection and query syntax; 6. Use debugging tools.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
