

Let's talk about MySQL global lock

This article brings you relevant knowledge about mysql, which mainly introduces related issues about global locks. Global locks are to lock the entire database. After we add a read lock to the database, no other requests can add a write lock to the database. Let's take a look at it together. I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
The original intention of database design is to deal with concurrency issues, as a resource shared by multiple users. When concurrent access occurs, the database needs to reasonably control resource access rules. The lock is an important data structure used to implement this access rule.
Let’s first post a diagram of the general classification of locks
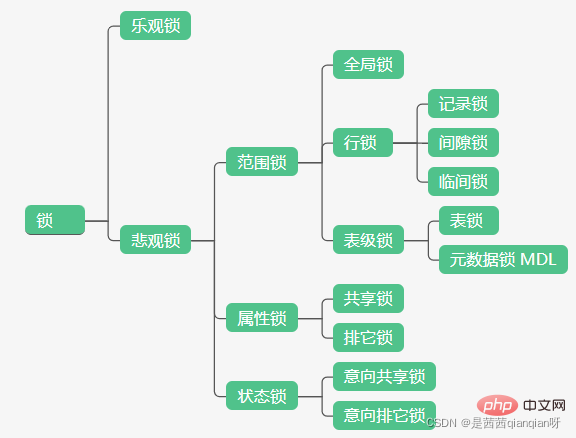
According to the scope of locking, the locks in MySQL can be roughly divided into global locks, table locks and table locks. Lock, row lock. We will mainly learn these types of locks first. In this article, we will learn about global locks.
Global lock
Global lock is to lock the entire database. After we add a read lock to the database, no other requests can add write locks to the database. When we add a write lock to the database, no other subsequent requests can add read or write locks to the database.
FTWRL
MySQL provides a method to add a global read lock, Flush tables with read lock (FTWRL). When we need to make the entire library in a read-only state, we can use this command. Then the following statements of other threads will be blocked: data update statements (add, delete, modify), data definition statements (including creating tables, modifying table structures, etc.) and update A commit statement for a class transaction.
Usage scenarios of global locks
Usage scenarios of global locks: Make logical backup of the entire database. Logical backup means selecting every table in the entire database and saving it as text. That is to say, the global lock is only used when performing master-slave backup data or importing and exporting data.
So why do we need a global lock?
Because when we are doing data backup or importing and exporting data, if data can be added, deleted, and modified at the same time during this period, data inconsistency will occur.
In the past, there was a way to use the FTWRL mentioned above to ensure that no other thread would update the database during the backup. Note: During the backup process, the entire library is completely in a read-only state.
Because the global lock is oriented to this database, adding a global lock sounds very dangerous:
- If we back up on the main database, updates cannot be performed during the backup period, and Basically all business is suspended.
- If we back up on the slave database, the binlog synchronized from the master database during the backup period cannot be executed, which will lead to master-slave delay and data inconsistency.
How to avoid locking
Since adding global lock has such a big impact, can we avoid locking?
Through the above introduction, we know that locking is to solve the problem of data inconsistency. So as long as we can solve the problem of data inconsistency, we don't need to add a global lock. There is such an idea: if we record an operation log when we start data backup, additions, deletions, modifications and queries to the database are allowed without locking during the backup process, and during the backup process, the operation records of additions, deletions, modifications and queries are recorded in one In the log file, after our backup is completed, we will execute all the operations in the log file during this period. This ensures the consistency of data before and after backup.
Summary, without locking, the backup data and the main data are not at a logical time point, and this view is logically inconsistent. If we ensure that the logical time points are consistent, that is, the logical views are consistent, we can ensure data consistency. From this, we think of the transaction isolation level we learned before. Opening a transaction under the repeatable isolation level is a consistent view.
There is a mechanism in InnoDB, the default engine of MySQL, to ensure data consistency. The InnoDB engine has a data snapshot version function. This function is called MVCC because MVCC retains snapshots of historical versions. Each snapshot corresponds to a transaction version number. When we back up data, we will apply for a transaction version number. When reading When fetching data, you only need to read data with a smaller transaction version number than your own.
–single-transaction command locking
The official logical backup tool is mysqldump. When mysqldump uses the parameter –single-transaction, a transaction will be started before importing data to ensure that a consistent view is obtained. Due to the support of MVCC, the data can be updated normally during this process.
--The role of the single-transaction parameter is to set the isolation level of the transaction to repeatable read, that is, REPEATABLE READ. This ensures that all the same queries in a transaction read the same data, which roughly guarantees that the During the dump, if other InnoDB engine threads modify the table data and submit it, it will have no impact on the data of the dump thread.
And set WITH CONSISTENT SNAPSHOT to the snapshot level. Imagine that if it is only repeatable reading, then before the data is dumped at the beginning of the transaction, other threads modify and submit the data, then the result of the first query at this time is the result submitted by other threads, and WITH CONSISTENT SNAPSHOT can ensure that when a transaction is started, the result of the first query is the data A at the beginning of the transaction. Even if other threads modify its data to B at this time, the result of the query is still A.
The single-transaction method only applies to libraries where all tables use transaction engines. In the mysqldump process, adding --single-transaction can ensure that the InnoDB data is completely consistent. For engines like MyISAM that do not support transactions, if there are updates during the backup process, only the latest data can be obtained. Then This destroys the consistency of the backup. At this time, a global lock is still needed, so we still need to use the FTWRL command.
Read-only setting
We may also have this question, since the whole library is read-only, why don't we use set global readonly = true?
It is true that the readonly method can also put the entire library into a read-only state, but it is still recommended to use the FTWRL method, mainly for two reasons:
- In some systems, the value of readonly will It is used for other logic, such as determining whether a database is the main database or the standby database. Therefore, modifying global variables has a greater impact.
- There are differences in the exception handling mechanism. If the client disconnects abnormally after executing the FTWRL command, MySQL will automatically release the global lock and the entire library will return to a state where it can be updated normally.
After setting the entire library to readonly, if an exception occurs on the client, the database will remain in the readonly state, which will cause the entire library to be in an unwritable state for a long time, with a high risk.
Recommended learning: mysql video tutorial
The above is the detailed content of Let's talk about MySQL global lock. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
