

What is the pipe character in linux

In Linux, the pipe character is "|", which is mainly used to connect two or more commands together and use the output of one command as the input of the next command; the syntax is "command1 | command2 [ | commandN... ]", the output of the command on the left side of the "|" character will be used as the input of the command on the right side of the "|" character. The pipe character can be used continuously. The output of the first command will be used as the input of the second command, and the output of the second command will be used as the input of the third command, and so on.

#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
Shell also has a function, which is to connect two or more commands (programs or processes) together, and use the output of one command as the input of the next command. The two connected in this way Or multiple commands form a pipeline.
Linux pipes use vertical bars| to connect multiple commands, which is called the pipe character.
command1 | command2 command1 | command2 [ | commandN... ]
When a pipe is set between two commands, the output of the command on the left of the pipe symbol | becomes the input of the command on the right. As long as the first command writes to standard output and the second command reads from standard input, the two commands can form a pipe. Most Linux commands can be used to form pipes.
The pipe character can be used continuously. The output of the first command will be used as the input of the second command, and the output of the second command will be used as the input of the third command, and so on.

It should be noted here that command1 must have correct output, and command2 must be able to process the output result of command2; and command2 can only process the correct output result of command1, not Handle the error message of command1.
For example: sort the hello.sh file and find the line containing "better" after sorting and deduplicating it.
The command is: cat hello.sh | sort | uniq | grep 'better'
- View text
- Sort
- Deduplication
- Filter

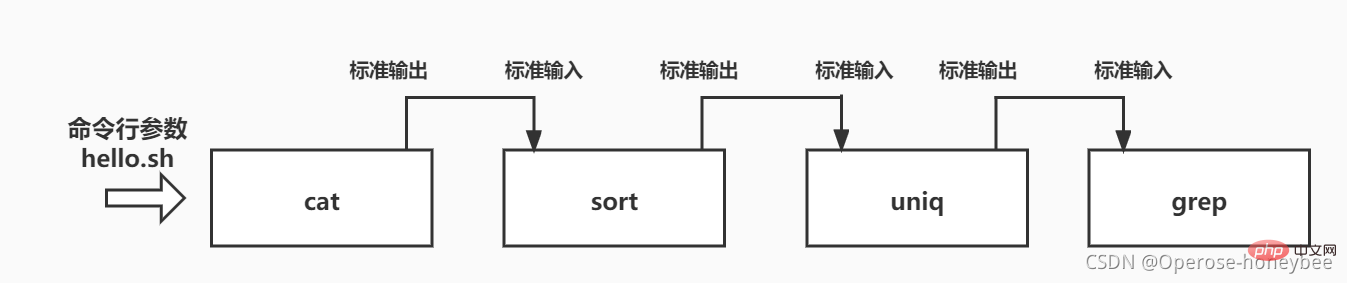
[1] The first step - view the text
First use the cat command to view the text, and the content printed on the screen is the output result of the cat command
[root@linuxforliuhj test]# cat hello.sh hello this is linux be better be better i am lhj hello this is linux i am lhj i am lhj be better i am lhj have a nice day have a nice day hello this is linux hello this is linux have a nice day zzzzzzzzzzzzzz dddddddd gggggggggggggggggggg [root@linuxforliuhj test]#
[2] The second process - sorting
Throw the results output by the previous cat command to the sort command through the pipeline, so the sort command sorts the text output by the previous cat command
[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
[3] The third process - deduplication
As mentioned in the previous article introducing uniq, sort can be effectively deduplicated when used in combination with uniq, so sort is processed through the pipeline and output The text is thrown to uniq for processing, so uniq processes the sorted text, which can effectively remove duplicates
[root@linuxforliuhj test]# cat hello.sh | sort | uniq be better dddddddd gggggggggggggggggggg have a nice day hello this is linux i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
[4] The fourth step - filtering
The last step of filtering is the same It is to filter the text output after processing the previous command, that is, the uniq command.
[root@linuxforliuhj test]# cat hello.sh | sort | uniq | grep 'better' be better [root@linuxforliuhj test]#
Here comes the important point!
Here comes the important point!
Here’s the point!
The above cat, sort, uniq, grep and other commands all support the pipe character because these commands can be read from the standard input. The text to be processed (that is, reading parameters from the standard input); for some commands, such as rm, kill and other commands, do not support reading parameters from the standard input, but only support reading parameters from the command line (that is, the rm command The file or directory to be deleted must be specified later, and the process number to be killed must be specified after the kill command.)
So what kind of commands support pipes, and what kind of commands do not support pipes? ?
Generally, commands that process text, such as sort, uniq, grep, awk, sed, etc., all support pipes; commands that do not process text, such as rm and ls, do not support pipes.
[root@linuxforliuhj test]# cat hello.sh | sort be better be better be better dddddddd gggggggggggggggggggg have a nice day have a nice day have a nice day hello this is linux hello this is linux hello this is linux hello this is linux i am lhj i am lhj i am lhj i am lhj zzzzzzzzzzzzzz [root@linuxforliuhj test]#
When there are no parameters after sort, the output of the previous command thrown to it by the pipe character is processed (that is, the standard output of the previous command is used as the standard input of this command)
[root@linuxforliuhj test]# ls beifen.txt hello.sh mk read.ln read.sh read.txt sub.sh [root@linuxforliuhj test]# ls | grep read.sh read.sh [root@linuxforliuhj test]# ls | grep read.sh | rm rm: missing operand Try 'rm --help' for more information. [root@linuxforliuhj test]#
When If the deleted file is not specified after rm, an error will be reported as missing parameters. Therefore, commands such as rm do not support reading parameters from the standard input. They only support specifying parameters on the command line, that is, specifying the deleted file.
Which takes precedence between standard input and command line parameters?
There are the following two files
[root@linuxforliuhj test]# cat a.txt aaaa dddd cccc bbbb [root@linuxforliuhj test]# cat b.txt 1111 3333 4444 2222 [root@linuxforliuhj test]#
Execute the command: cat a.txt | sort
[root@linuxforliuhj test]# cat a.txt | sort aaaa bbbb cccc dddd [root@linuxforliuhj test]#
When the command line parameter of sort is empty, the former is used by default The output result of a command is used as the input of this command.
Execute the command: cat a.txt | sort b.txt
[root@linuxforliuhj test]# cat a.txt | sort b.txt 1111 2222 3333 4444 [root@linuxforliuhj test]#
You can see that when the command line parameters of sort (here are b.txt) is not empty, sort will not read the parameters in the standard input, but will read the command line parameters
Execute the command: cat a.txt | sort b.txt -
[root@linuxforliuhj test]# cat a.txt | sort b.txt - 1111 2222 3333 4444 aaaa bbbb cccc dddd [root@linuxforliuhj test]#
" - "means standard input, that is, the output of the command cat a.txt, which is equivalent to sorting the file b.txt and standard input together, which is equivalent to sort a.txt b.txt
[root@linuxforliuhj test]# sort a.txt b.txt 1111 2222 3333 4444 aaaa bbbb cccc dddd [root@linuxforliuhj test]#
思考:对于rm、kill等命令,我们写脚本时常常会遇到需要查询某个进程的进程号然后杀掉该进程,查找某个文件然后删除它这样的需求,该怎么办呢?那就用xargs吧!
相关推荐:《Linux视频教程》
The above is the detailed content of What is the pipe character in linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
Linux is suitable for servers, development environments, and embedded systems. 1. As a server operating system, Linux is stable and efficient, and is often used to deploy high-concurrency applications. 2. As a development environment, Linux provides efficient command line tools and package management systems to improve development efficiency. 3. In embedded systems, Linux is lightweight and customizable, suitable for environments with limited resources.
 How to start apache
Apr 13, 2025 pm 01:06 PM
How to start apache
Apr 13, 2025 pm 01:06 PM
The steps to start Apache are as follows: Install Apache (command: sudo apt-get install apache2 or download it from the official website) Start Apache (Linux: sudo systemctl start apache2; Windows: Right-click the "Apache2.4" service and select "Start") Check whether it has been started (Linux: sudo systemctl status apache2; Windows: Check the status of the "Apache2.4" service in the service manager) Enable boot automatically (optional, Linux: sudo systemctl
 What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
When the Apache 80 port is occupied, the solution is as follows: find out the process that occupies the port and close it. Check the firewall settings to make sure Apache is not blocked. If the above method does not work, please reconfigure Apache to use a different port. Restart the Apache service.
 How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
This article describes how to effectively monitor the SSL performance of Nginx servers on Debian systems. We will use NginxExporter to export Nginx status data to Prometheus and then visually display it through Grafana. Step 1: Configuring Nginx First, we need to enable the stub_status module in the Nginx configuration file to obtain the status information of Nginx. Add the following snippet in your Nginx configuration file (usually located in /etc/nginx/nginx.conf or its include file): location/nginx_status{stub_status
 How to start monitoring of oracle
Apr 12, 2025 am 06:00 AM
How to start monitoring of oracle
Apr 12, 2025 am 06:00 AM
The steps to start an Oracle listener are as follows: Check the listener status (using the lsnrctl status command) For Windows, start the "TNS Listener" service in Oracle Services Manager For Linux and Unix, use the lsnrctl start command to start the listener run the lsnrctl status command to verify that the listener is started
 How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
This article introduces two methods of configuring a recycling bin in a Debian system: a graphical interface and a command line. Method 1: Use the Nautilus graphical interface to open the file manager: Find and start the Nautilus file manager (usually called "File") in the desktop or application menu. Find the Recycle Bin: Look for the Recycle Bin folder in the left navigation bar. If it is not found, try clicking "Other Location" or "Computer" to search. Configure Recycle Bin properties: Right-click "Recycle Bin" and select "Properties". In the Properties window, you can adjust the following settings: Maximum Size: Limit the disk space available in the Recycle Bin. Retention time: Set the preservation before the file is automatically deleted in the recycling bin
 How to restart the apache server
Apr 13, 2025 pm 01:12 PM
How to restart the apache server
Apr 13, 2025 pm 01:12 PM
To restart the Apache server, follow these steps: Linux/macOS: Run sudo systemctl restart apache2. Windows: Run net stop Apache2.4 and then net start Apache2.4. Run netstat -a | findstr 80 to check the server status.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
