

This article brings you relevant knowledge about python, which mainly introduces the related issues about pdfplumber reading PDF and writing to Excel, including the installation of pdfplumber module, loading PDF, and Let’s take a look at some practical operations and so on. I hope it will be helpful to everyone.

Recommended learning: python video tutorial
PDF ( Portable Document Format) is a portable document format that facilitates the dissemination of documents across operating systems. PDF documents follow a standard format, so there are many tools that can operate on PDF documents, and Python is no exception.
Comparison chart of Python operating PDF modules is as follows:
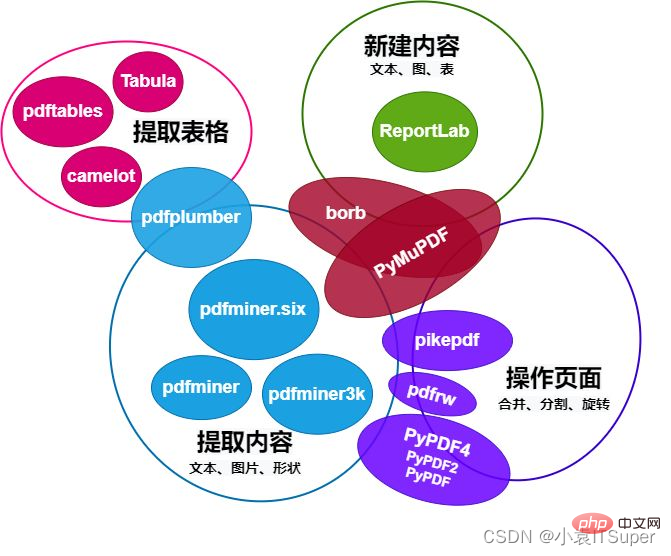
This article mainly introduces pdfplumberFocus on PDF content extraction, such as text (position, font and colors, etc.) and shapes (rectangles, straight lines, curves), as well as the function of parsing tables.
Several other Python libraries help users extract information from PDFs. As a broad overview, pdfplumber differentiates itself from other PDF processing libraries by combining the following features:
cmd console input:
pip install pdfplumber
Guide package:
import pdfplumber
Case PDF screenshot (two pages are not cut off):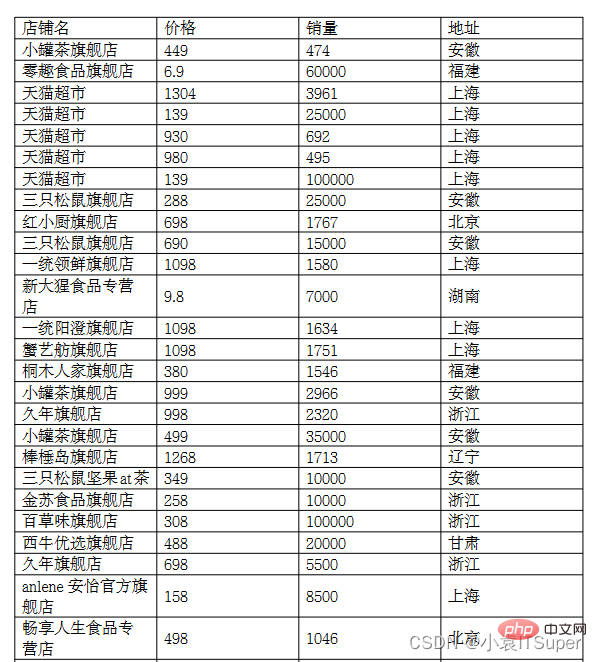
Read PDF code: pdfplumber.open("path/filename.pdf", password = "test", laparams = { "line_overlap": 0.7 })
Parameter interpretation:
password : To load a password-protected PDF, please pass the password keyword parameter laparams: To set the layout analysis parameters to the layout engine of pdfminer.six, pass the laparams keyword argument Case code:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))Output Result:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
pdfplumber.PDF class represents a single PDF and has two main properties:
| Properties | Description |
|---|---|
##.metadata | From PDF Get the metadata key/value pair dictionary from Info. Usually includes "CreationDate", "ModDate", "Producer", etc.
|
.pages | Returns a list containing pdfplumber.Page instances, each instance represents the information of each page of the PDF
1. Read PDF document information (.metadata) :
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata){'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}2. Output the total number of pages
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))2
pdfplumber.PageThe class is the core of pdfplumber. Most operations revolve around this class. It has the following attributes:
| Description | |
|---|---|
.page_number | Sequential page numbers, starting from 1 on the first page, starting from the second page 2, and so on analogy. |
.width | The width of the page. |
.height | The height of the page. |
.objects/.chars/.lines/.rects/.curves/.figures/.images | Each of these properties is a list, each containing a dictionary for each such object embedded on the page. See "Objects" below for details.
Commonly used methods are as follows:
| Description | |
|---|---|
.extract_text() | is used to extract the text in the page and organize all the character objects on the page into That string |
.extract_words() | returns all the words and their related information|
.extract_tables() | Extract the tables of the page|
.to_image() | When used for visual debugging, return an instance of the PageImage class|
.close() | By default, the Page object caches its layout and object information to avoid reprocessing it. However, these cached properties can require a lot of memory when parsing large PDFs. You can use this method to flush the cache and free up memory.
The above is the detailed content of Python example detailed explanation of pdfplumber reading PDF and writing to Excel. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



