

An article to talk about the auto-incrementing primary key in MySQL

This article will give you an in-depth understanding of the auto-incrementing primary key in MySQL. I hope it will be helpful to you!

#1. Where is the self-increased value stored?
Different engines have different strategies for saving auto-incremented values
1. The auto-incremented value of the MyISAM engine is stored in the data file
2.The auto-incremented value of the InnoDB engine , in MySQL5.7 and previous versions, the self-incremented value is stored in memory and is not persisted. After each restart, when you open the table for the first time, you will find the maximum value of the auto-increment max(id), and then use the max(id) step size as the current auto-increment value of the table
select max(ai_col) from table_name for update;
In MySQL8 .0 version records the changes in the self-increasing value in the redo log. When restarting, rely on the redo log to restore the value before restarting
2. Self-increasing value modification mechanism
If the field id is defined as AUTO_INCREMENT, when inserting a row of data, the behavior of auto-increment is as follows:
1. If the id field is specified as 0, null or unspecified value when inserting data, then this The current AUTO_INCREMENT value of the table is filled in the auto-increment field
2. If the id field specifies a specific value when inserting data, use the value specified in the statement directly
Assume that a certain value is to be inserted The value is X, and the current auto-increment value is Y
1. If The self-increment value is modified to a new self-increment value
The new self-increment value generation algorithm is: starting from auto_increment_offset (initial value), taking auto_increment_increment (step size) as the step size, and continuing to superpose until the first value is found. A value greater than Field, c is the only index. The table creation statement is as follows:CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB;
insert into t values(null, 1, 1);
1. The executor calls the InnoDB engine interface to write a row. The value of the passed row is (0,1,1)
2.InnoDB Find the value for which the auto-increment id is not specified, and obtain the current auto-increment value of table t 23. Change the value of the incoming row to (2,1,1)4 .Change the auto-increment value of the table to 35. Continue to insert data. Since the record of c=1 already exists, a Duplicate key error (unique key conflict) is reported, and the statement returns The corresponding execution flow chart is as follows:After that, when inserting a new data row, the auto-incremented ID obtained is 3. There is a situation where the auto-incrementing primary key is not continuous
Unique key conflicts and transaction rollbacks will lead to the situation where the auto-incrementing primary key id is not continuous
4. Optimization of lock increase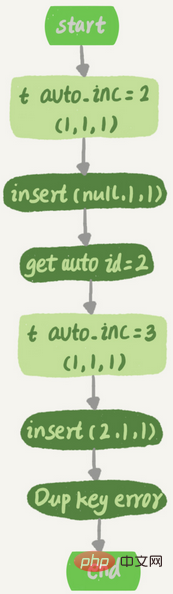
But in MySQL5. In version 0, the scope of self-increasing locks is statement level. In other words, if a statement applies for a table auto-increment lock, the lock will not be released until the statement is executed.
MySQL version 5.1.22 introduces a new strategy, a new parameter innodb_autoinc_lock_mode, the default value is 11. This parameter is set to 0, which means the strategy of the previous MySQL5.0 version is adopted, that is, the lock is released only after the statement is executed.
2. This parameter is set to 1In ordinary insert statements, the self-increasing lock is released immediately after the application.
For statements such as insert...select that insert data in batches, the self-increasing lock still has to wait until the statement is completed before being released
3. This parameter is set to 2. All actions for applying for an auto-incremented primary key are to release the lock after application. For the sake of data consistency, the default setting is 1- If sessionB releases the auto-increment lock immediately after applying for the auto-increment value, then the following situation may occur:
, sessionB continued to execute and inserted two records ( 4,3,3), (5,4,4)
- Ideas to solve this problem:
- 1) Let the original library insert data statements in batches to generate continuous id values. Therefore, the self-increasing lock is not released until the execution of the statement is completed, just to achieve this purpose
- 2) Record the operations of inserting data in the binlog truthfully, so that when the standby database is executed, it no longer relies on the self-increasing lock. Add primary key to generate. That is, set innodb_autoinc_lock_mode to 2 and binlog_format to row
如果有批量插入数据(insert … select、replace … select和load data)的场景时,从并发插入数据性能的角度考虑,建议把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row,这样做既能并发性,又不会出现数据一致性的问题
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
1.语句执行过程中,第一次申请自增id,会分配1个
2.1个用完以后,这个语句第二次申请自增id,会分配2个
3.2个用完以后,还是这个语句,第三次申请自增id,会分配4个
4.依次类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍
insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
insert … select,实际上往表t2中插入了4行数据。但是,这四行数据是分三次申请的自增id,第一次申请到了id=1,第二次被分配了id=2和id=3,第三次被分配到id=4到id=7
由于这条语句实际上只用上了4个id,所以id=5到id=7就被浪费掉了。之后,再执行insert into t2 values(null, 5,5),实际上插入了的数据就是(8,5,5)
这是主键id出现自增id不连续的第三种原因
五、自增主键用完了
自增主键字段在达到定义类型上限后,再插入一行记录,则会报主键冲突的错误
CREATE TABLE t ( id INT UNSIGNED auto_increment PRIMARY KEY ) auto_increment = 4294967295; INSERT INTO t VALUES(NULL); INSERT INTO t VALUES(NULL);
第一个insert语句插入数据成功后,这个表的AUTO_INCREMENT没有改变(还是4294967295),就导致了第二个insert语句又拿到相同的自增id值,再试图执行插入语句,报主键冲突错误
【相关推荐:mysql视频教程】
The above is the detailed content of An article to talk about the auto-incrementing primary key in MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
Recovering deleted rows directly from the database is usually impossible unless there is a backup or transaction rollback mechanism. Key point: Transaction rollback: Execute ROLLBACK before the transaction is committed to recover data. Backup: Regular backup of the database can be used to quickly restore data. Database snapshot: You can create a read-only copy of the database and restore the data after the data is deleted accidentally. Use DELETE statement with caution: Check the conditions carefully to avoid accidentally deleting data. Use the WHERE clause: explicitly specify the data to be deleted. Use the test environment: Test before performing a DELETE operation.
 How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
Steps to perform SQL in Navicat: Connect to the database. Create a SQL Editor window. Write SQL queries or scripts. Click the Run button to execute a query or script. View the results (if the query is executed).
