
 Java
JavaInterview questions
[Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection)
Java
JavaInterview questions
[Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection)
[Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection)

This article summarizes some 2023 selected basic Java high-frequency interview questions worth collecting (with answers). It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.
![[Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection)](https://img.php.cn/upload/article/000/000/024/62c79d0ce0756800.jpg)
#1. What are the three basic characteristics of object-oriented?
The three basic characteristics of object-oriented are: encapsulation, inheritance and polymorphism.
Inheritance: A method that allows an object of a certain type to obtain the properties of an object of another type. Inheritance means that a subclass inherits the characteristics and behaviors of the parent class, so that the subclass object (instance) has the instance fields and methods of the parent class, or the subclass inherits methods from the parent class, so that the subclass has the same behavior as the parent class. (Recommended tutorial: java introductory tutorial)
Encapsulation: Hide the properties and implementation details of some objects, and access to data can only be through externally exposed interfaces. In this way, objects provide varying levels of protection for internal data to prevent unrelated parts of the program from accidentally changing or incorrectly using the private parts of the object.
Polymorphism: For the same behavior, different subclass objects have different manifestations. There are three conditions for the existence of polymorphism: 1) inheritance; 2) overwriting; 3) parent class reference points to subclass object.
A simple example: In League of Legends, we press the Q key:
- For Yasuo, it is Steel Flash
- For Teemo, It’s the Blinding Dart
- For Juggernaut, it’s Alpha Strike
The same event will produce different results when it happens to different objects.
Let me give you another simple example to help you understand. This example may not be completely accurate, but I think it is helpful for understanding.
public class Animal { // 动物
public void sleep() {
System.out.println("躺着睡");
}
}
class Horse extends Animal { // 马 是一种动物
public void sleep() {
System.out.println("站着睡");
}
}
class Cat extends Animal { // 猫 是一种动物
private int age;
public int getAge() {
return age + 1;
}
@Override
public void sleep() {
System.out.println("四脚朝天的睡");
}
}In this example:
Both House and Cat are Animal, so they both inherit Animal and also inherit the sleep behavior from Animal.
But for the sleep behavior, House and Cat have been rewritten and have different expressions (implementations). This is called polymorphism.
In Cat, the age attribute is defined as private and cannot be directly accessed by the outside world. The only way to obtain Cat's age information is through the getAge method, thus hiding the age attribute from the outside. This is called encapsulation. Of course, age here is just an example, and it may be a much more complex object in actual use.
2. What is the difference between access modifiers public, private, protected, and not written?
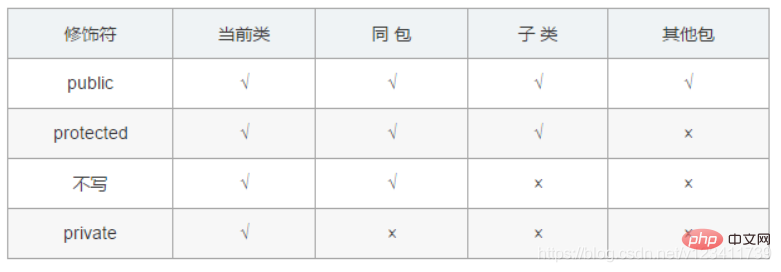
3. Can the following two code blocks be compiled and executed normally?
// 代码块1 short s1 = 1; s1 = s1 + 1; // 代码块2 short s1 = 1; s1 += 1;
Code block 1 compiles and reports an error. The reason for the error is: Incompatible type: Conversion from int to short may cause loss.
Code block 2 compiles and executes normally.
We compile code block 2. The bytecode is as follows:
public class com.joonwhee.open.demo.Convert {
public com.joonwhee.open.demo.Convert();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1 // 将int类型值1入(操作数)栈
1: istore_1 // 将栈顶int类型值保存到局部变量1中
2: iload_1 // 从局部变量1中装载int类型值入栈
3: iconst_1 // 将int类型值1入栈
4: iadd // 将栈顶两int类型数相加,结果入栈
5: i2s // 将栈顶int类型值截断成short类型值,后带符号扩展成int类型值入栈。
6: istore_1 // 将栈顶int类型值保存到局部变量1中
7: return
}You can see that the bytecode contains the i2s instruction, which is used to convert int to short. i2s is Abbreviation of int to short.
In fact, s1 = 1 is equivalent to s1 = (short)(s1 1). If you are interested, you can compile the bytecode of these two lines of code yourself. You will find that it is It’s the same.
The basic Java questions that we said started to change again???

4. Basic inspection, point out The output result of the next question
public static void main(String[] args) {
Integer a = 128, b = 128, c = 127, d = 127;
System.out.println(a == b);
System.out.println(c == d);
}The answer is: false, true.
Executing Integer a = 128 is equivalent to executing: Integer a = Integer.valueOf(128), basic type The process of automatically converting to a packaging class is called autoboxing.
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}IntegerCache is introduced in Integer to cache a certain range of values. By default, IntegerCache range is: -128~127.
127 in this question hits the IntegerCache, so c and d are the same object, while 128 does not hit, so a and b are different objects.
But this cache range can be modified, maybe Some people don’t know. You can modify the upper limit value through the JVM startup parameter: -XX:AutoBoxCacheMax= 2 << 3. Advanced: Under normal circumstances, bit operations can be considered to have the highest performance . However, in fact, compilers are now "very smart", and many instruction compilers can do optimizations by themselves. Therefore, in actual practice, we do not need to pursue practical bit operations. This will not only lead to poor code readability, Moreover, some clever optimizations will mislead the compiler, preventing the compiler from performing better optimizations. This may be the so-called "pig teammate". &&:逻辑与运算符。当运算符左右两边的表达式都为 true,才返回 true。同时具有短路性,如果第一个表达式为 false,则直接返回 false。 &:逻辑与运算符、按位与运算符。 按位与运算符:用于二进制的计算,只有对应的两个二进位均为1时,结果位才为1 ,否则为0。 逻辑与运算符:& 在用于逻辑与时,和 && 的区别是不具有短路性。所在通常使用逻辑与运算符都会使用 &&,而 & 更多的适用于位运算。 答:不是。Java 中的基本数据类型只有8个:byte、short、int、long、float、double、char、boolean;除了基本类型(primitive type),剩下的都是引用类型(reference type)。 基本数据类型:数据直接存储在栈上 引用数据类型区别:数据存储在堆上,栈上只存储引用地址 不行。String 类使用 final 修饰,无法被继承。 String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的生成。 StringBuffer:跟 String 类似,但是值可以被修改,使用 synchronized 来保证线程安全。 StringBuilder:StringBuffer 的非线程安全版本,没有使用 synchronized,具有更高的性能,推荐优先使用。 一个或两个。如果字符串常量池已经有“xyz”,则是一个;否则,两个。 当字符创常量池没有 “xyz”,此时会创建如下两个对象: 一个是字符串字面量 "xyz" 所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,此时该实例也是在堆中,字符串常量池只放引用。 另一个是通过 new String() 创建并初始化的,内容与"xyz"相同的实例,也是在堆中。 两个语句都会先去字符串常量池中检查是否已经存在 “xyz”,如果有则直接使用,如果没有则会在常量池中创建 “xyz” 对象。 另外,String s = new String("xyz") 还会通过 new String() 在堆里创建一个内容与 "xyz" 相同的对象实例。 所以前者其实理解为被后者的所包含。 ==:运算符,用于比较基础类型变量和引用类型变量。 对于基础类型变量,比较的变量保存的值是否相同,类型不一定要相同。 对于引用类型变量,比较的是两个对象的地址是否相同。 equals:Object 类中定义的方法,通常用于比较两个对象的值是否相等。 equals 在 Object 方法中其实等同于 ==,但是在实际的使用中,equals 通常被重写用于比较两个对象的值是否相同。 不对。hashCode() 和 equals() 之间的关系如下: 当有 a.equals(b) == true 时,则 a.hashCode() == b.hashCode() 必然成立, 反过来,当 a.hashCode() == b.hashCode() 时,a.equals(b) 不一定为 true。 反射是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能称为反射机制。 数据分为基本数据类型和引用数据类型。基本数据类型:数据直接存储在栈中;引用数据类型:存储在栈中的是对象的引用地址,真实的对象数据存放在堆内存里。 浅拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:只是复制了对象的引用地址,新旧对象指向同一个内存地址,修改其中一个对象的值,另一个对象的值随之改变。 深拷贝:对于基础数据类型:直接复制数据值;对于引用数据类型:开辟新的内存空间,在新的内存空间里复制一个一模一样的对象,新老对象不共享内存,修改其中一个对象的值,不会影响另一个对象。 深拷贝相比于浅拷贝速度较慢并且花销较大。 并发:两个或多个事件在同一时间间隔发生。 并行:两个或者多个事件在同一时刻发生。 并行是真正意义上,同一时刻做多件事情,而并发在同一时刻只会做一件事件,只是可以将时间切碎,交替做多件事情。 网上有个例子挺形象的: 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。 Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到⼀个类中有多个构造函数的情况。 值传递。Java 中只有值传递,对于对象参数,值的内容是对象的引用。 成员变量存在于堆内存中。静态变量存在于方法区中。 成员变量与对象共存亡,随着对象创建而存在,随着对象被回收而释放。静态变量与类共存亡,随着类的加载而存在,随着类的消失而消失。 成员变量所属于对象,所以也称为实例变量。静态变量所属于类,所以也称为类变量。 成员变量只能被对象所调用 。静态变量可以被对象调用,也可以被类名调用。 区分两种情况,发出调用时是否显示创建了对象实例。 1)没有显示创建对象实例:不可以发起调用,非静态方法只能被对象所调用,静态方法可以通过对象调用,也可以通过类名调用,所以静态方法被调用时,可能还没有创建任何实例对象。因此通过静态方法内部发出对非静态方法的调用,此时可能无法知道非静态方法属于哪个对象。 2)显示创建对象实例:可以发起调用,在静态方法中显示的创建对象实例,则可以正常的调用。 执行结果:ABabab,两个考察点: 1)静态变量只会初始化(执行)一次。 2)当有父类时,完整的初始化顺序为:父类静态变量(静态代码块)->子类静态变量(静态代码块)->父类非静态变量(非静态代码块)->父类构造器 ->子类非静态变量(非静态代码块)->子类构造器 。 关于初始化,这题算入门题,我之前还写过一道有(fei)点(chang)意(bian)思(tai)的进阶题目,有兴趣的可以看看:一道有意思的“初始化”面试题 方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。 重载:一个类中有多个同名的方法,但是具有有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)。 重写:发生在子类与父类之间,子类对父类的方法进行重写,参数都不能改变,返回值类型可以不相同,但是必须是父类返回值的派生类。即外壳不变,核心重写!重写的好处在于子类可以根据需要,定义特定于自己的行为。 如果我们有两个方法如下,当我们调用:test(1) 时,编译器无法确认要调用的是哪个。 方法的返回值只是作为方法运行之后的一个“状态”,但是并不是所有调用都关注返回值,所以不能将返回值作为重载的唯一区分条件。 抽象类只能单继承,接口可以多实现。 抽象类可以有构造方法,接口中不能有构造方法。 抽象类中可以有成员变量,接口中没有成员变量,只能有常量(默认就是 public static final) 抽象类中可以包含非抽象的方法,在 Java 7 之前接口中的所有方法都是抽象的,在 Java 8 之后,接口支持非抽象方法:default 方法、静态方法等。Java 9 支持私有方法、私有静态方法。 抽象类中的方法类型可以是任意修饰符,Java 8 之前接口中的方法只能是 public 类型,Java 9 支持 private 类型。 设计思想的区别: 接口是自上而下的抽象过程,接口规范了某些行为,是对某一行为的抽象。我需要这个行为,我就去实现某个接口,但是具体这个行为怎么实现,完全由自己决定。 抽象类是自下而上的抽象过程,抽象类提供了通用实现,是对某一类事物的抽象。我们在写实现类的时候,发现某些实现类具有几乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后如果有一些差异点,则可以提供抽象方法来支持自定义实现。 我在网上看到有个说法,挺形象的: 普通类像亲爹 ,他有啥都是你的。 抽象类像叔伯,有一部分会给你,还能指导你做事的方法。 接口像干爹,可以给你指引方法,但是做成啥样得你自己努力实现。 Error 和 Exception 都是 Throwable 的子类,用于表示程序出现了不正常的情况。区别在于: Error 表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的一种严重问题,比如内存溢出,不可能指望程序能处理这样的情况。 Exception 表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。 修饰类:该类不能再派生出新的子类,不能作为父类被继承。因此,一个类不能同时被声明为abstract 和 final。 修饰方法:该方法不能被子类重写。 修饰变量:该变量必须在声明时给定初值,而在以后只能读取,不可修改。 如果变量是对象,则指的是引用不可修改,但是对象的属性还是可以修改的。 其实是三个完全不相关的东西,只是长的有点像。。 final 如上所示。 finally:finally 是对 Java 异常处理机制的最佳补充,通常配合 try、catch 使用,用于存放那些无论是否出现异常都一定会执行的代码。在实际使用中,通常用于释放锁、数据库连接等资源,把资源释放方法放到 finally 中,可以大大降低程序出错的几率。 finalize:Object 中的方法,在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。finalize()方法仅作为了解即可,在 Java 9 中该方法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的方法来释放资源。这也侧面说明了,这个方法的设计是失败的,因此更加不能去使用它。 执行结果:31。 相信很多同学应该都做对了,try、catch。finally 的基础用法,在 return 前会先执行 finally 语句块,所以是先输出 finally 里的 3,再输出 return 的 1。 执行结果:3。 这题有点陷阱,但也不难,try 返回前先执行 finally,结果 finally 里不按套路出牌,直接 return 了,自然也就走不到 try 里面的 return 了。 finally 里面使用 return 仅存在于面试题中,实际开发中千万不要这么用。 执行结果:2。 这边估计有不少同学会以为结果应该是 3,因为我们知道在 return 前会执行 finally,而 i 在 finally 中被修改为 3 了,那最终返回 i 不是应该为 3 吗?确实很容易这么想,我最初也是这么想的,当初的自己还是太年轻了啊。 这边的根本原因是,在执行 finally 之前,JVM 会先将 i 的结果暂存起来,然后 finally 执行完毕后,会返回之前暂存的结果,而不是返回 i,所以即使这边 i 已经被修改为 3,最终返回的还是之前暂存起来的结果 2。 In fact, it can be easily seen based on the bytecode. Before entering finally, the JVM will use the iload and istore instructions to temporarily store the results. When it finally returns, it will return the temporary results through the iload and ireturn instructions. result. In order to prevent the atmosphere from becoming abnormal again, I will not post the specific bytecode program here. Interested students can compile and check it out by themselves. Interface default method: Java 8 allows us to add a non-abstract method implementation to the interface, just use the default keyword Lambda expression and functional interface: Lambda An expression is essentially an anonymous inner class, or it can be a piece of code that can be passed around. Lambda allows the function to be used as a parameter of a method (the function is passed to the method as a parameter). Use Lambda expressions to make the code more concise, but do not abuse it, otherwise there will be readability problems, Josh Bloch, author of "Effective Java" suggested It is best to use lambda expressions in no more than 3 lines. Stream API: A tool for performing complex operations on collection classes using functional programming. It can be used with Lambda expressions to easily process collections. A key abstraction for working with collections in Java 8. It allows you to specify the operations you want to perform on collections, and can perform very complex operations such as finding, filtering, and mapping data. Using the Stream API to operate on collection data is similar to using SQL to perform database queries. You can also use the Stream API to perform operations in parallel. In short, the Stream API provides an efficient and easy-to-use way to process data. Method reference: Method reference provides a very useful syntax that can directly reference methods or constructors of existing Java classes or objects (instances). Used in conjunction with lambda, method references can make the language structure more compact and concise and reduce redundant code. Date and time API: Java 8 introduces a new date and time API to improve date and time management. Optional class: The famous NullPointerException is the most common cause of system failure. The Google Guava project introduced Optional a long time ago as a way to solve null pointer exceptions, disapproving of code being polluted by null-checking code, and expecting programmers to write clean code. Inspired by Google Guava, Optional is now part of the Java 8 library. New tools: new compilation tools, such as: Nashorn engine jjs, class dependency analyzer jdeps. The sources are different: sleep() comes from the Thread class, and wait() comes from the Object class. The impact on synchronization locks is different: sleep() will not behave as a synchronization lock on the table. If the current thread holds a synchronization lock, sleep will not allow the thread to release the synchronization lock. wait() will release the synchronization lock and allow other threads to enter the synchronized code block for execution. Different scope of use: sleep() can be used anywhere. wait() can only be used in synchronized control methods or synchronized control blocks, otherwise IllegalMonitorStateException will be thrown. The recovery methods are different: the two will suspend the current thread, but the recovery is different. sleep() will resume after the time is up; wait() requires other threads to call notify()/nofityAll() of the same object to resume again. The thread enters the timeout waiting (TIMED_WAITING) state after executing the sleep() method, and enters the READY state after executing the yield() method. The sleep() method does not consider the priority of the thread when giving other threads a chance to run, so it will give low-priority threads a chance to run; the yield() method will only give the same priority or higher priority. The thread has a chance to run. is used to wait for the current thread to terminate. If a thread A executes the threadB.join() statement, the meaning is: the current thread A waits for the threadB thread to terminate before returning from threadB.join() and continuing to execute its own code. Generally speaking, there are three ways: 1) inherit the Thread class; 2) implement the Runnable interface; 3) implement the Callable interface. Among them, Thread actually implements the Runable interface. The main difference between Runnable and Callable is whether there is a return value. run(): ordinary method call, executed in the main thread, not A new thread will be created for execution. start(): Start a new thread. At this time, the thread is in the ready (runnable) state and is not running. Once the CPU time slice is obtained, the run() method starts to be executed. A thread can be in one of the following states: NEW:新建但是尚未启动的线程处于此状态,没有调用 start() 方法。 RUNNABLE:包含就绪(READY)和运行中(RUNNING)两种状态。线程调用 start() 方法会会进入就绪(READY)状态,等待获取 CPU 时间片。如果成功获取到 CPU 时间片,则会进入运行中(RUNNING)状态。 BLOCKED:线程在进入同步方法/同步块(synchronized)时被阻塞,等待同步锁的线程处于此状态。 WAITING:无限期等待另一个线程执行特定操作的线程处于此状态,需要被显示的唤醒,否则会一直等待下去。例如对于 Object.wait(),需要等待另一个线程执行 Object.notify() 或 Object.notifyAll();对于 Thread.join(),则需要等待指定的线程终止。 TIMED_WAITING:在指定的时间内等待另一个线程执行某项操作的线程处于此状态。跟 WAITING 类似,区别在于该状态有超时时间参数,在超时时间到了后会自动唤醒,避免了无期限的等待。 TERMINATED:执行完毕已经退出的线程处于此状态。 线程在给定的时间点只能处于一种状态。这些状态是虚拟机状态,不反映任何操作系统线程状态。 1)Lock 是一个接口;synchronized 是 Java 中的关键字,synchronized 是内置的语言实现; 2)Lock 在发生异常时,如果没有主动通过 unLock() 去释放锁,很可能会造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁;synchronized 不需要手动获取锁和释放锁,在发生异常时,会自动释放锁,因此不会导致死锁现象发生; 3)Lock 的使用更加灵活,可以有响应中断、有超时时间等;而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,直到获取到锁; 4)在性能上,随着近些年 synchronized 的不断优化,Lock 和 synchronized 在性能上已经没有很明显的差距了,所以性能不应该成为我们选择两者的主要原因。官方推荐尽量使用 synchronized,除非 synchronized 无法满足需求时,则可以使用 Lock。 1.作用于非静态方法,锁住的是对象实例(this),每一个对象实例有一个锁。 2.作用于静态方法,锁住的是类的Class对象,因为Class的相关数据存储在永久代元空间,元空间是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程。 3.作用于 Lock.class,锁住的是 Lock 的Class对象,也是全局只有一个。 4.作用于 this,锁住的是对象实例,每一个对象实例有一个锁。 5.作用于静态成员变量,锁住的是该静态成员变量对象,由于是静态变量,因此全局只有一个。 死锁的四个必要条件: 1)互斥条件:进程对所分配到的资源进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。 2)请求和保持条件:进程已经获得了至少一个资源,但又对其他资源发出请求,而该资源已被其他进程占有,此时该进程的请求被阻塞,但又对自己获得的资源保持不放。 3)不可剥夺条件:进程已获得的资源在未使用完毕之前,不可被其他进程强行剥夺,只能由自己释放。 4)环路等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中 Pi 等待的资源被 P(i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0占 有,如下图所示。 预防死锁的方式就是打破四个必要条件中的任意一个即可。 1)打破互斥条件:在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。因此,在死锁预防里主要是破坏其他几个必要条件,而不去涉及破坏“互斥”条件。。 2)打破请求和保持条件:1)采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待。 2)每个进程提出新的资源申请前,必须先释放它先前所占有的资源。 3) Break the inalienable condition: When a process occupies certain resources and then further applies for other resources but cannot satisfy them, the process must release the resources it originally occupied. 4) Break the loop waiting condition: implement an orderly resource allocation strategy, number all resources in the system uniformly, and all processes can only apply for resources in the form of increasing sequence numbers. If we directly create a new thread in the method, many threads will be created when this method is called frequently, which will not only consume system resources, but also reduce the stability of the system. Be careful to crash the system, and you can go directly to the finance department to settle the bill. If we use the thread pool reasonably, we can avoid the dilemma of crashing the system. In general, using a thread pool can bring the following benefits: threadFactory (thread factory): Factory used to create worker threads. corePoolSize (number of core threads): When the thread pool is running less than corePoolSize threads, a new thread will be created to handle the request, even if other worker threads are idle. workQueue (queue): A blocking queue used to retain tasks and hand them over to worker threads. maximumPoolSize (maximum number of threads): The maximum number of threads allowed to be opened in the thread pool. handler (rejection policy): When adding a task to the thread pool, the rejection policy will be triggered in the following two situations: 1) The running status of the thread pool is not RUNNING; 2) The thread pool has reached the maximum number of threads and is blocked. When the queue is full. keepAliveTime (keep alive time): If the current number of threads in the thread pool exceeds corePoolSize, the excess threads will be terminated when their idle time exceeds keepAliveTime. AbortPolicy: Abort policy. The default rejection strategy directly throws RejectedExecutionException. The caller can catch this exception and write its own handling code according to the needs. DiscardPolicy: Discard policy. Do nothing and simply discard the rejected task. DiscardOldestPolicy: Discard the oldest policy. Abandoning the oldest task in the blocking queue is equivalent to the next task in the queue to be executed, and then resubmitting the rejected task. If the blocking queue is a priority queue, then the "drop oldest" strategy will cause the highest priority tasks to be dropped, so it is best not to use this strategy with a priority queue. CallerRunsPolicy: Caller run policy. Execute the task in the caller thread. This strategy implements an adjustment mechanism that neither abandons the task nor throws an exception, but rolls the task back to the caller (the main thread that calls the thread pool to execute the task). Since executing the task takes a certain amount of time , so the main thread cannot submit tasks for at least a period of time, allowing the thread pool time to finish processing the tasks being executed. List (a good helper for dealing with sequences): The List interface stores a set of non-unique ( There can be multiple elements referencing the same object), ordered objects. Set (focus on unique properties): Duplicate sets are not allowed, and multiple elements will not reference the same object. Map (professional users who use Key to search): Use key-value pair storage. Map maintains values associated with Key. Two Keys can refer to the same object, but the Key cannot be repeated. A typical Key is a String type, but it can also be any object. The bottom layer of ArrayList is based on dynamic array implementation, and the bottom layer of LinkedList is based on linked list implementation. For index data (get/set method): ArrayList directly locates the node at the corresponding position of the array through index, while LinkedList needs to start traversing from the head node or tail node until the target node is found, so in In terms of efficiency, ArrayList is better than LinkedList. For random insertion and deletion: ArrayList needs to move the nodes behind the target node (use the System.arraycopy method to move the nodes), while LinkedList only needs to modify the next or prev attributes of the nodes before and after the target node, so it is more efficient. LinkedList is better than ArrayList. For sequential insertion and deletion: Since ArrayList does not need to move nodes, it is better than LinkedList in terms of efficiency. This is why there are more ArrayLists in actual use, because in most cases our usage is sequential insertion. Vector and ArrayList are almost the same. The only difference is that Vector uses synchronized on the method to ensure thread safety, so ArrayList has better performance in terms of performance. Similar relationships include: StringBuilder and StringBuffer, HashMap and Hashtable. We are now using JDK 1.8. The bottom layer is composed of "array linked list red-black tree", as shown below , and before JDK 1.8, it was composed of "array linked list". Mainly to improve the search performance when hash conflicts are severe (the linked list is too long). The search performance using a linked list is O(n), while using a red-black tree is O(logn). For insertion, linked list nodes are used by default. When the number of nodes at the same index position exceeds 8 (threshold 8) after being added: if the array length is greater than or equal to 64 at this time, it will trigger the conversion of the linked list node into a red-black tree node (treeifyBin); and if the array length is less than 64, then The linked list will not be triggered to convert to a red-black tree, but will be expanded because the amount of data at this time is still relatively small. For removal, when the number of nodes at the same index position reaches 6 after removal, and the node at the index position is a red-black tree node, the conversion of the red-black tree node to the linked list node (untreeify) will be triggered. The default initial capacity is 16. The capacity of HashMap must be 2 to the Nth power. HashMap will calculate the smallest 2 to the Nth power that is greater than or equal to the capacity based on the capacity we pass in. For example, if 9 is passed, the capacity is 16. HashMap allows key and value to be null, but Hashtable does not. The default initial capacity of HashMap is 16 and Hashtable is 11. The expansion of HashMap is 2 times of the original, and the expansion of Hashtable is 2 times of the original plus 1. HashMap is not thread-safe, Hashtable is thread-safe. The hash value of HashMap has been recalculated, and Hashtable uses hashCode directly. HashMap removes the contains method in Hashtable. HashMap inherits from the AbstractMap class, and Hashtable inherits from the Dictionary class. Program counter: Thread private. A small memory space that can be regarded as a line number indicator of the bytecode executed by the current thread. If the thread is executing a Java method, this counter records the address of the virtual machine bytecode instruction being executed; if the thread is executing a Native method, the counter value is empty. Java virtual machine stack: thread private. Its life cycle is the same as that of a thread. The virtual machine stack describes the memory model of Java method execution: when each method is executed, a stack frame is created to store local variable tables, operand stacks, dynamic links, method exits and other information. The process from the call to the completion of execution of each method corresponds to the process from pushing a stack frame into the virtual machine stack to popping it out. Local method stack: thread private. The functions played by the local method stack and the virtual machine stack are very similar. The only difference between them is that the virtual machine stack serves the virtual machine to execute Java methods (that is, bytecode), while the local method stack is used by the virtual machine. To the Native method service. Java heap: thread sharing. For most applications, the Java heap is the largest piece of memory managed by the Java virtual machine. The Java heap is a memory area shared by all threads and is created when the virtual machine starts. The only purpose of this memory area is to store object instances, and almost all object instances allocate memory here. Method area: Like the Java heap, it is a memory area shared by each thread. It is used to store class information (construction methods, interface definitions), constants, static variables, and just-in-time compilers that have been loaded by the virtual machine. Compiled code (bytecode) and other data. The method area is a concept defined in the JVM specification. Where it is placed, different implementations can be placed in different places. 运行时常量池:运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。 上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而"hello"这个字面量是放在堆中。 如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。 启动类加载器(Bootstrap ClassLoader): 这个类加载器负责将存放在 扩展类加载器(Extension ClassLoader): 这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载 应用程序类加载器(Application ClassLoader): 这个类加载器由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。 自定义类加载器: 用户自定义的类加载器。 类加载的过程包括:加载、验证、准备、解析、初始化,其中验证、准备、解析统称为连接。 加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.Class对象。 验证:确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。 准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。 解析:将常量池内的符号引用替换为直接引用。 初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(static{})中的语句。 在什么时候? 在触发GC的时候,具体如下,这里只说常见的 Young GC 和 Full GC。 触发Young GC:当新生代中的 Eden 区没有足够空间进行分配时会触发Young GC。 触发Full GC: 对什么? 对那些JVM认为已经“死掉”的对象。即从GC Root开始搜索,搜索不到的,并且经过一次筛选标记没有复活的对象。 做了什么? 对这些JVM认为已经“死掉”的对象进行垃圾收集,新生代使用复制算法,老年代使用标记-清除和标记-整理算法。 在Java语言中,可作为GC Roots的对象包括下面几种: Marking - Clearing Algorithm First mark all objects that need to be recycled, and after the marking is completed, all marked objects will be recycled uniformly. There are two main shortcomings: one is the efficiency problem, the efficiency of the marking and clearing processes is not high; the other is the space problem. After marking and clearing, a large number of discontinuous memory fragments will be generated. Too many space fragments may cause In the future, when a larger object needs to be allocated while the program is running, sufficient contiguous memory cannot be found and another garbage collection action has to be triggered in advance. Copy algorithm In order to solve the efficiency problem, a collection algorithm called "Copying" (Copying) appeared, which divides the available memory into sizes according to capacity. Two equal pieces, only use one of them at a time. When this block of memory runs out, copy the surviving objects to another block, and then clean up the used memory space at once. In this way, the entire half area is recycled every time, and there is no need to consider complex situations such as memory fragmentation when allocating memory. Just move the top pointer of the heap and allocate memory in order. It is simple to implement and efficient to run. It's just that the cost of this algorithm is to reduce the memory to half of its original size, which is a bit too high. Mark - Collation Algorithm The copy collection algorithm will perform more copy operations when the object survival rate is high, and the efficiency will become lower. More importantly, if you don't want to waste 50% of the space, you need to have additional space for allocation guarantee to cope with the extreme situation where all objects in the used memory are 100% alive, so this method generally cannot be directly used in the old generation. algorithm. According to the characteristics of the old generation, someone has proposed another "mark-compact" algorithm. The marking process is still the same as the "mark-clear" algorithm, but the subsequent steps are not directly related to the recyclables. Objects are cleaned up, but all surviving objects are moved to one end, and then the memory outside the end boundary is directly cleared. Generational Collection Algorithm Currently commercial virtual machines use the "Generational Collection" (Generational Collection) algorithm for garbage collection. There is nothing new about this algorithm. The idea is just to divide the memory into several blocks according to the different life cycles of the objects. Generally, the Java heap is divided into the new generation and the old generation, so that the most appropriate collection algorithm can be used according to the characteristics of each generation. In the new generation, it is found that a large number of objects die every time during garbage collection, and only a few survive. Then use the copy algorithm, and only need to pay the copy cost of a small number of surviving objects to complete the collection. In the old generation, because the object survival rate is high and there is no extra space to allocate it to guarantee it, the mark-clean or mark-clean algorithm must be used for recycling. In the season of gold, three and silver, I believe many students are preparing to change jobs. I have summarized my recent original articles: original summary, which contains analysis of many high-frequency interview questions, many of which I encountered when interviewing with big companies. I am reviewing each When analyzing the questions, they will be analyzed in depth according to higher standards. You may not be able to fully understand it after reading it only once, but I believe that you will gain something by reading it repeatedly. For more programming-related knowledge, please visit: Programming Courses! ! The above is the detailed content of [Hematemesis compilation] 2023 Java basic high-frequency interview questions and answers (Collection). For more information, please follow other related articles on the PHP Chinese website!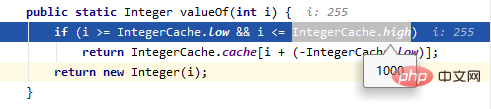
5 , use the most efficient method to calculate 2 times 8?

6、&和&&的区别?
7、String 是 Java 基本数据类型吗?
8、String 类可以继承吗?
9、String和StringBuilder、StringBuffer的区别?
10、String s = new String("xyz") 创建了几个字符串对象?
11、String s = "xyz" 和 String s = new String("xyz") 区别?
12、== 和 equals 的区别是什么?
short s1 = 1; long l1 = 1;
// 结果:true。类型不同,但是值相同
System.out.println(s1 == l1);
Integer i1 = new Integer(1);
Integer i2 = new Integer(1);
// 结果:false。通过new创建,在内存中指向两个不同的对象
System.out.println(i1 == i2);
Integer i1 = new Integer(1);
Integer i2 = new Integer(1);
// 结果:true。两个不同的对象,但是具有相同的值
System.out.println(i1.equals(i2));
// Integer的equals重写方法
public boolean equals(Object obj) {
if (obj instanceof Integer) {
// 比较对象中保存的值是否相同
return value == ((Integer)obj).intValue();
}
return false;
}13、两个对象的 hashCode() 相同,则 equals() 也一定为 true,对吗?
14、什么是反射
15、深拷贝和浅拷贝区别是什么?
16、并发和并行有什么区别?
17、构造器是否可被 重写?
18、当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
19、Java 静态变量和成员变量的区别。
public class Demo {
/**
* 静态变量:又称类变量,static修饰
*/
public static String STATIC_VARIABLE = "静态变量";
/**
* 实例变量:又称成员变量,没有static修饰
*/
public String INSTANCE_VARIABLE = "实例变量";
}20、是否可以从一个静态(static)方法内部发出对非静态(non-static)方法的调用?
public class Demo {
public static void staticMethod() {
// 直接调用非静态方法:编译报错
instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}public class Demo {
public static void staticMethod() {
// 先创建实例对象,再调用非静态方法:成功执行
Demo demo = new Demo();
demo.instanceMethod();
}
public void instanceMethod() {
System.out.println("非静态方法");
}
}21、初始化考察,请指出下面程序的运行结果。
public class InitialTest {
public static void main(String[] args) {
A ab = new B();
ab = new B();
}
}
class A {
static { // 父类静态代码块
System.out.print("A");
}
public A() { // 父类构造器
System.out.print("a");
}
}
class B extends A {
static { // 子类静态代码块
System.out.print("B");
}
public B() { // 子类构造器
System.out.print("b");
}
}22、重载(Overload)和重写(Override)的区别?
23、为什么不能根据返回类型来区分重载?
// 方法1
int test(int a);
// 方法2
long test(int a);
24、抽象类(abstract class)和接口(interface)有什么区别?
25、Error 和 Exception 有什么区别?
26、Java 中的 final 关键字有哪些用法?
public class FinalDemo {
// 不可再修改该变量的值
public static final int FINAL_VARIABLE = 0;
// 不可再修改该变量的引用,但是可以直接修改属性值
public static final User USER = new User();
public static void main(String[] args) {
// 输出:User(id=0, name=null, age=0)
System.out.println(USER);
// 直接修改属性值
USER.setName("test");
// 输出:User(id=0, name=test, age=0)
System.out.println(USER);
}
}27、阐述 final、finally、finalize 的区别。
28、try、catch、finally 考察,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
}29、try、catch、finally 考察2,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
try {
return 2;
} finally {
return 3;
}
}
}30、try、catch、finally 考察3,请指出下面程序的运行结果。
public class TryDemo {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
}
31. What are the new features after JDK1.8?
32. The difference between wait() and sleep() methods
33. What is the difference between the sleep() method and the yield() method of a thread?
34. What is the join() method of thread used for?
35. How many ways are there to write multi-threaded programs?
36. The difference between Thread calling start() method and calling run() method
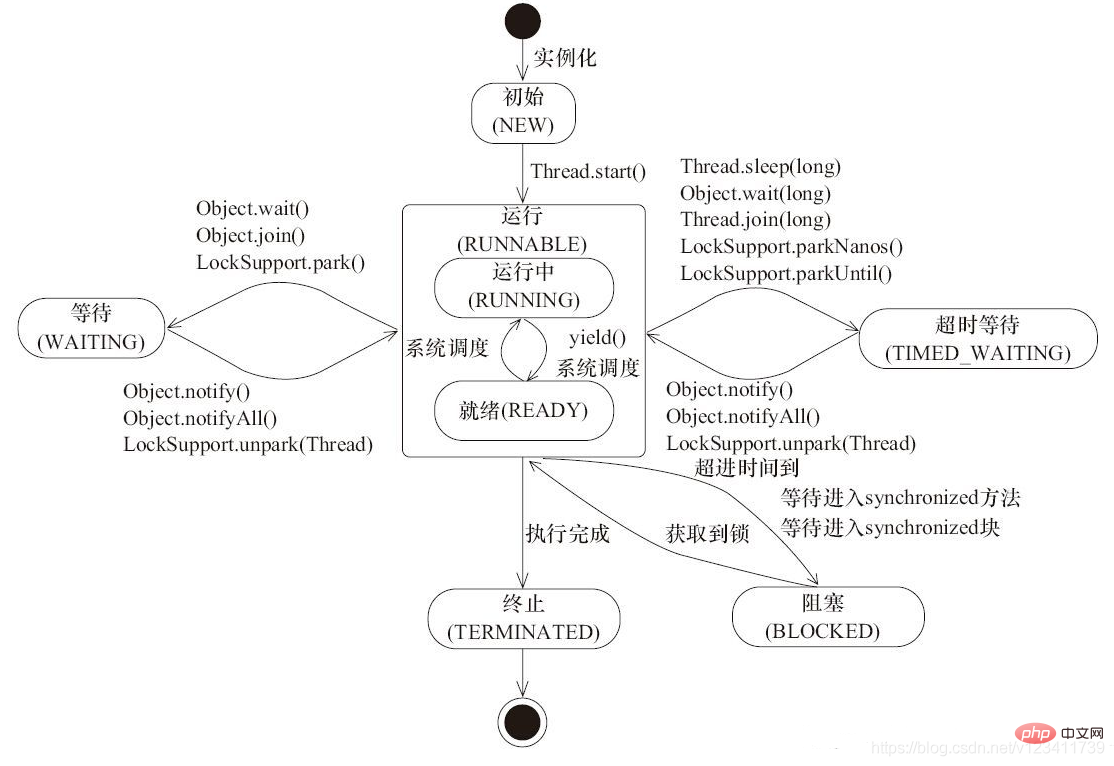
37. Thread state flow
38、synchronized 和 Lock 的区别
39、synchronized 各种加锁场景的作用范围
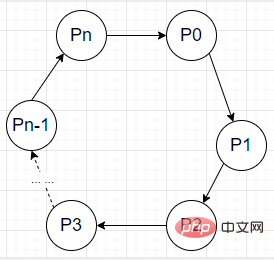
public synchronized void method() {}public static synchronized void method() {}synchronized (Lock.class) {}synchronized (this) {}public static Object monitor = new Object(); synchronized (monitor) {}40、如何检测死锁?
41、怎么预防死锁?
42. Why use thread pool? Isn’t it comfortable to create a new thread directly?
43. What are the core attributes of the thread pool?
44. Let’s talk about the operation process of the thread pool.

#45. What are the rejection strategies for the thread pool?
46. What are the differences between List, Set and Map?
47. The difference between ArrayList and LinkedList.
48. The difference between ArrayList and Vector.
49. Introduce the underlying data structure of HashMap
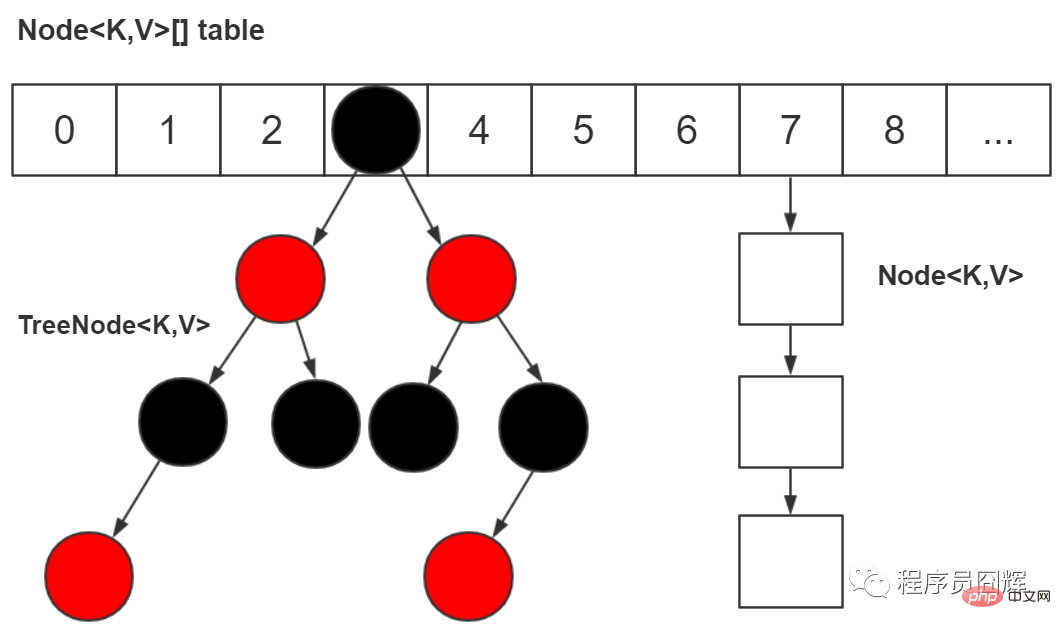
#50. Why should it be changed to "array, linked list, red-black tree"?
51. When should you use a linked list? When to use red-black trees?
52. What is the default initial capacity of HashMap? Is there any limit to the capacity of HashMap?
53. What is the insertion process of HashMap?
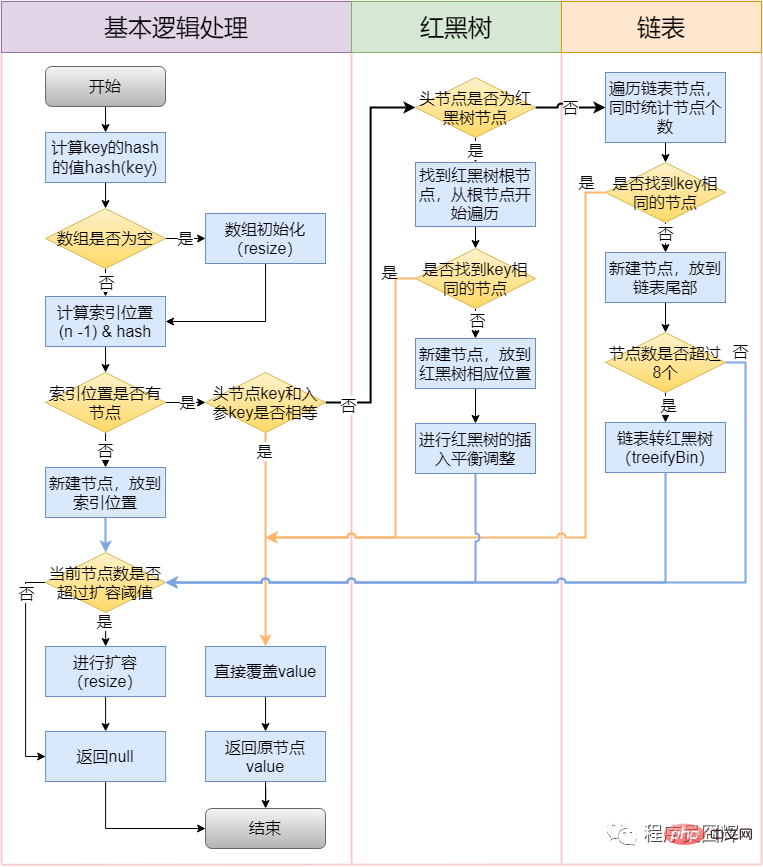
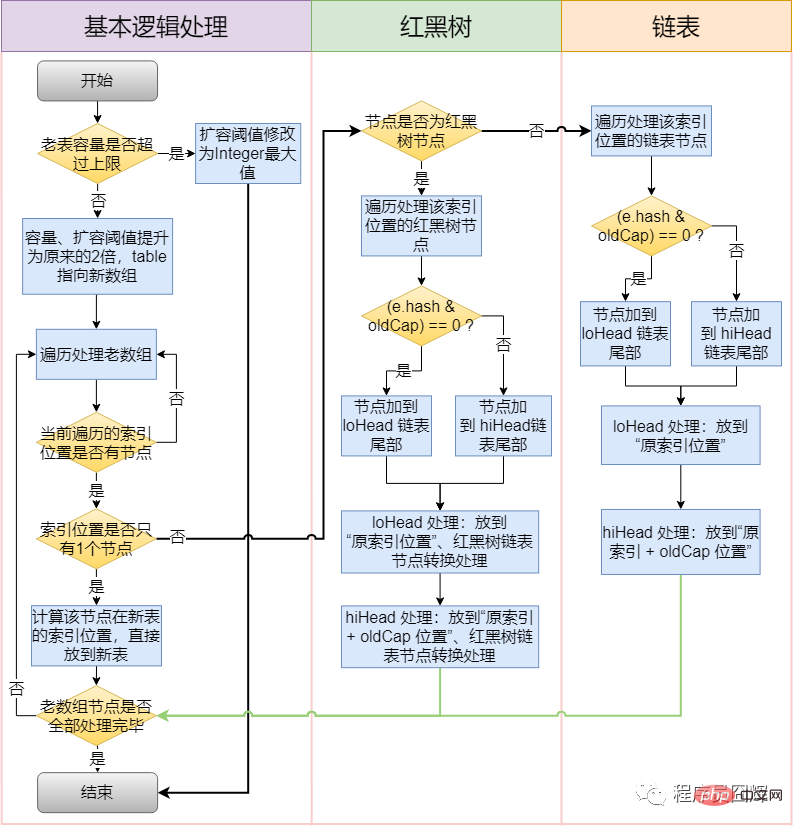
54. What is the expansion (resize) process of HashMap?
55. In addition to HashMap, what other Maps have been used, and how to choose when using them?

56. What is the difference between HashMap and Hashtable?
57. Java memory structure (runtime data area)
String str = new String("hello");58、什么是双亲委派模型?
59、Java虚拟机中有哪些类加载器?
60、类加载的过程
61、介绍下垃圾收集机制(在什么时候,对什么,做了什么)?
62、GC Root有哪些?
63. What are the garbage collection algorithms and their respective characteristics?
Finally

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
You must know Spring, so let’s talk about the order of all notifications of Aop. How does Spring Boot or Spring Boot 2 affect the execution order of aop? Tell us about the pitfalls you encountered in AOP?
 Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
OOM means that there is a vulnerability in the program, which may be caused by the code or JVM parameter configuration. This article talks to readers about how to troubleshoot when a Java process triggers OOM.
 Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Don’t underestimate the written examination questions of many companies. There are pitfalls and you can fall into them accidentally. When you encounter this kind of written test question about cycles, I suggest you think calmly and take it step by step.
 Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, a friend in the group went for an interview with Ping An Insurance. The result was a bit regretful, which is quite a pity, but I hope you don’t get discouraged. As you said, basically all the questions encountered in the interview can be solved by memorizing the interview questions. It’s solved, so please work hard!
 Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
The extra chapter of the Java concurrent programming series, C A S (Compare and swap), is still in an easy-to-understand style with pictures and texts, allowing readers to have a crazy conversation with the interviewer.
 5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
This article will take a look at 5 interview questions about the Java String class. I have personally experienced several of these five questions during the interview process. This article will help you understand why the answers to these questions are like this.

 It is recommended to collect 100 Linux interview questions with answers
Aug 23, 2023 pm 02:37 PM
It is recommended to collect 100 Linux interview questions with answers
Aug 23, 2023 pm 02:37 PM
This article has a total of more than 30,000 words, covering Linux overview, disk, directory, file, security, syntax level, practical combat, file management commands, document editing commands, disk management commands, network communication commands, system management commands, backup compression commands, etc. Dismantling Linux knowledge points.
