

Let's talk about using redis to implement distributed caching

This article brings you relevant knowledge about Redis, which mainly organizes issues related to distributed cache. Distributed means that it consists of multiple applications, which may be distributed on different servers. Above, we are ultimately providing services for the web side. Let’s take a look at them together. I hope it will be helpful to everyone.

Recommended learning: Redis video tutorial
Distributed cache description:
The focus of distributed caching is on distribution. I believe you have come into contact with many distributed ones, such as distributed development, distributed deployment, distributed locks, things, systems, etc. There are many. This gives us a clear understanding of distribution itself. Distribution is composed of multiple applications, which may be distributed on different servers, and ultimately provide services to the web side.
Distributed caching has the following advantages:
- The cached data on all Web servers is the same, and the cached data will not be different due to different applications and different servers. .
- The cache is independent and not affected by the restart of the Web server or deletion and addition, which means that these changes to the Web will not cause changes to the cached data.
In the traditional single application architecture, because the number of user visits is not high, most of the cache exists to store user information and some pages, and most operations are performed directly with the DB. Reading and writing interaction, this kind of architecture is simple, also called simple architecture,
Traditional OA projects such as ERP, SCM, CRM and other systems have a small number of users and are also due to the business reasons of most companies. The single application architecture is still very complicated. It is a commonly used architecture, but in some systems, as the number of users increases and the business expands, DB bottlenecks appear.
There are two ways to deal with this situation that I have learned below
(1): When the number of user visits is not large, but the amount of data read and written is large, What we generally adopt is to separate the reading and writing of the DB, use one master and multiple slaves, and upgrade the hardware to solve the DB bottleneck problem.
Such shortcomings are also pure:
1. What to do when the number of users is large? ,
2. The performance improvement is limited,
3. The price/performance ratio is not high. Improving performance requires a lot of money (for example, the current I/O throughput is 0.9 and needs to be increased to 1.0. This price is indeed considerable when we increase the machine configuration)
(2): When the number of user visits also increases, we need to introduce caching to solve the problem. A picture describes the general function of caching.
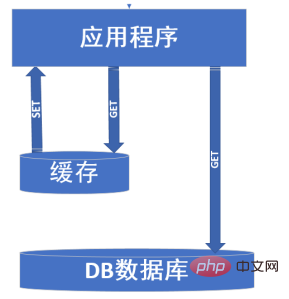
The cache is mainly aimed at data that does not change frequently and has a large number of visits. The DB database can be understood as only for data solidification or only for reading frequently. For the changed data, I did not draw the SET operation in the picture above. I just want to explain that the cache can be used as a temporary database. We can synchronize the data in the cache and the database through scheduled tasks. In this way The advantage is that it can transfer the pressure of the database to the cache.
The emergence of cache solves the problem of database pressure, but when the following situations occur, the cache will no longer play a role, cache penetration, cache breakdown, cache avalanche, these three situations.
Cache penetration: When using cache in our program, we usually first go to the cache to query the cache data we want. If the data we want does not exist in the cache, If so, the cache will lose its function (cache failure). We just need to reach out to the DB library to ask for data. At this time, if there are too many such actions, the database will crash. This situation needs to be prevented by us. For example: we obtain user information from the cache, but deliberately enter user information that does not exist in the cache, thus avoiding the cache and shifting the pressure back to the data. To deal with this problem, we can cache the data accessed for the first time, because the cache cannot find the user information, and the database cannot query the user information. At this time, to avoid repeated access, we cache the request and put the pressure back on Turning to the cache, some people may have questions. What to do when there are tens of thousands of accessed parameters that are unique and can avoid cache. We also store the data and set a shorter expiration time to clear the cache.
Cache breakdown: The thing is like this. For some cache KEYs with expiration times set, when they expire, the program is accessed with high concurrent access (cache invalidation). At this time Use a mutex lock to solve the problem.
Mutex lock principle:The popular description is that 10,000 users access the database, but only one user can get access to the database. When After the user obtains this permission, he re-creates the cache. At this time, the remaining visitors are waiting to access the cache because they have not obtained the permission.
Never expires: Some people may think, can’t it be enough if I don’t set the expiration time? Yes, but this also has disadvantages. We need to update the cache regularly. At this time, the data in the cache is relatively delayed.
Cache avalanche: means that multiple caches are set to expire at the same time. At this time, a large number of data accesses come, (Cache invalidation) The pressure on the database DB Up again. The solution is to add a random number to the expiration time when setting the expiration time to ensure that the cache does not fail in large areas.
Project preparation
1. First install Redis, you can refer to here
2. Then download and install: client tool: RedisDesktopManager (convenient management)
3. Reference Microsoft.Extensions.Caching.Redis in our project Nuget
For this we create a new ASP.NET Core MVC project and first register the Redis service in the ConfigureServices method of the project Startup class:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
You can also specify the IP address, port number and login password of the Redis server when registering the Redis service above:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
Later we will explain how the Redis instance name DemoInstance set by options.InstanceName above is used What to do
In addition, you can also specify the timeout period of the Redis server in the services.AddDistributedRedisCache method. If you call the method in the IDistributedCache interface introduced later and the operation on the Redis server times out, a RedisConnectionException will be thrown. and RedisTimeoutException, so below we specify three timeouts when registering the Redis service:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
Among them, ConnectTimeout is the timeout to establish a connection to the Redis server, and SyncTimeout and ResponseTimeout are to perform data processing on the Redis server. The timeout period for the operation. Note that above we used the options.ConfigurationOptions attribute to set the IP address, port number and login password of the Redis server
IDistributedCache interface
Referenced in the project: using Microsoft. Extensions.Caching.Distributed; Using IDistributedCache
The IDistributedCache interface contains synchronous and asynchronous methods. Interface allows adding, retrieving, and deleting items in a distributed cache implementation. The IDistributedCache interface contains the following methods:
Get, GetAsync
takes a string key and retrieves the cache item as a byte[] if found in the cache.
Set, SetAsync
Use string keys to add or change items to the cache (byte[] form).
Refresh, RefreshAsync
Refreshes an item in the cache based on a key and resets its adjustable expiration timeout value (if any).
Remove, RemoveAsync
Remove cache items based on key. If the key passed into the Remove method does not exist in Redis, the Remove method will not report an error, but nothing will happen. However, if the parameter passed into the Remove method is null, an exception will be thrown.
As mentioned above, since the Set and Get methods of the IDistributedCache interface access data from Redis through byte[] byte arrays, it is not very convenient in a sense. I encapsulate it below. A RedisCache class can access any type of data from Redis.
The Json.NET Nuget package is used to serialize and deserialize Json format:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
|
Use test
Then we In the ASP.NET Core MVC project, create a new CacheController, and then test the related methods of the RedisCache class in its Index method:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
Previously we called services.AddDistributedRedisCache registration in the ConfigureServices method of the Startup class of the project When serving Redis, options.InstanceName = "DemoInstance" is set. So what is the use of this InstanceName?
When we call the following code of the Index method in the above CacheController:
1 2 3 4 5 6 7 |
|
We use redis-cli to log in to the Redis server, and use the Keys * command to view the information stored in the current Redis service When all keys are displayed, you can see the result as follows:
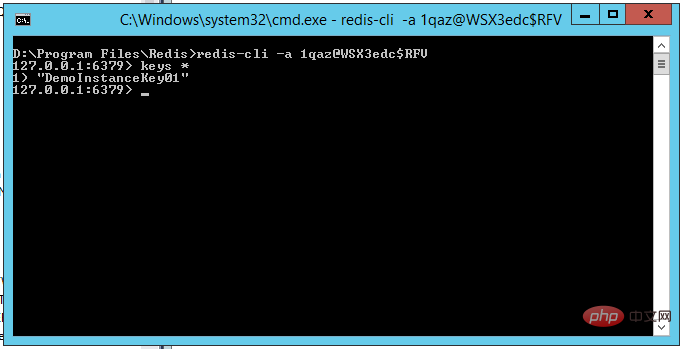
You can see that although the key stored in Redis in our code is "Key01", it is actually in the Redis service The stored key is "DemoInstanceKey01", so the key actually stored in the Redis service is the "InstanceName key" combination key, so we can do data isolation in Redis for different Applications by setting different InstanceNames. This That’s the role of InstanceName
Recommended learning: Redis video tutorial
The above is the detailed content of Let's talk about using redis to implement distributed caching. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1205
24
52
1205
24

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
