

In Linux, the Chinese meaning of pic means "position-independent code", which means that the code can be executed normally no matter which address it is loaded to. PIC is used to generate position-independent shared libraries. The so-called position-independent means that the code segments of the shared libraries are read-only and stored in the code segment. Multiple processes can share this code segment at the same time without copying.

#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
In Linux, the full name of pic is "Position Independent Code", which means "position independent code" in Chinese.
1. Overview of code related to program virtual address space and location
When the Linux process is loaded from disk to memory and runs, the kernel will Allocate a virtual address space to the process. The virtual address space is divided into blocks of areas (Segments). The most important areas are as follows:
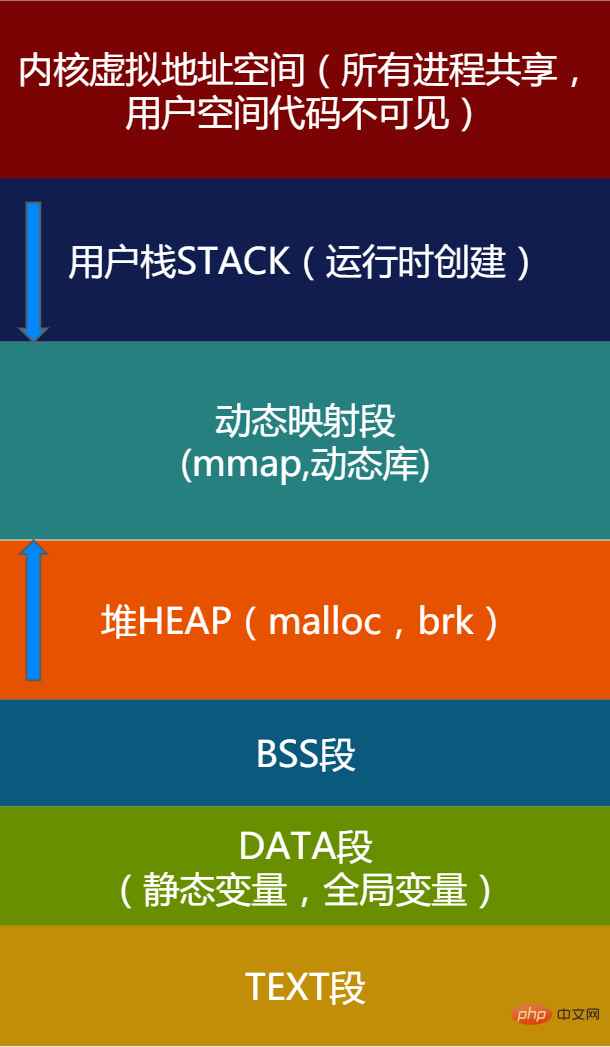
Figure 1 - Application Virtual address space description
The kernel address space is the same for all applications. This part of the address space cannot be directly accessed by applications. The kernel address space is not the focus of this article. We focus on some important SEGMENTs of the application.
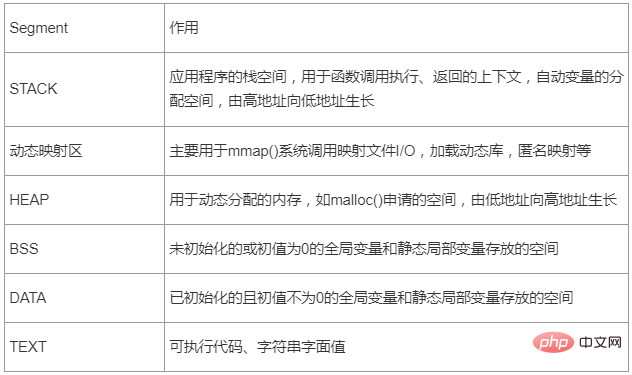
Table 1 - Application important segment description
If the system does not enable address randomization (ASLR - Address Space Layout Randomization, address randomization, later (will be introduced), Linux will place the address space of each segment in the above table at a fixed address.
We write an actual program to see how the addresses of each segment are arranged on a Linux X86_64 machine. The program is as follows, covering the segments we care about.

Figure 2 - Virtual address space demonstration program
Compilation
gcc -o addr_test addr_test.c -static
(Static linking is used here to demonstrate the location-related code Features)
When we run this program 3 times, we will find that all addresses are a fixed value. This is because when the ASLR feature is not turned on, the system does not randomly allocate the virtual address space of the program, and all addresses of the program are generated according to fixed rules.

Figure 3 - Fixed segment address distribution
After disassembling through the objdump command, we can see that for access to global variables and function calls, the assembly instructions follow The addresses are all fixed, so we call such code location-related.

Figure 4 - Example of position-related code assembly statement
This kind of code, because the address is hard-coded, can only be loaded to the specified address and run. Once the loading address changes, since the addresses of variables and functions accessed in the code are fixed, the program cannot execute normally after the loading address changes.
Although the fixed address method is simple, it cannot implement some advanced features such as dynamic library support. The code of the dynamic library will be mapped to the virtual address space of the process through the mmap() system call. In different processes, the virtual address mapped by the same dynamic library is uncertain. If position-related code is used in the implementation of a dynamic library, the purpose of running at any address cannot be achieved. In this case, we need to introduce the concept of position-independent code PIC.
In addition, we can see that on systems where the address randomization feature is not turned on, since the addresses of each segment of the program are fixed, it will be easier for hackers to attack (interested students can search for Ret2shellcode or Ret2libc attack), at this time the concept of PIE needs to be introduced together with ASLR for protection.
2. Implementation of position-independent code PIC and dynamic library
PIC position-independent code means that no matter which address the code is loaded at, Can be executed normally. Adding -fPIC to the gcc option will generate relevant code.
PIC is used to generate position-independent shared libraries. The so-called position-independent means that the code segments of the shared libraries are read-only and stored in the code segment. Multiple processes can share this code segment at the same time. A copy is required. Variables (global variables and static variables) in the library are accessed through the GOT table, and functions in the library are accessed through the PLT->GOT->function location. When compiling a shared library under Linux, you must add the -fPIC parameter, otherwise there will be an error message during linking (some information says that this error only occurs on AMD64 machines, but it also occurred on my Inter machine).
Key point #1 - Offset between code segment and data segment
The offset between code segment and data segment is given by the linker during linking Out, it is very important for PIC. When the linker combines all p's of each object file together, the linker fully knows the size of each p and the relative position between them.
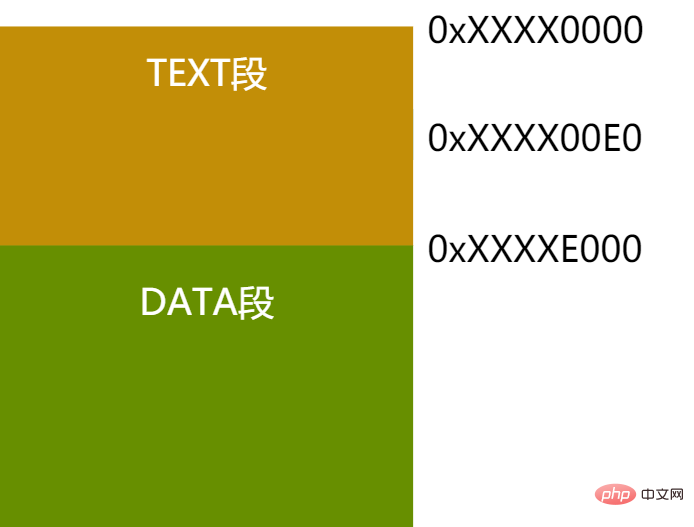
Figure 5 - Code segment and data segment offset example
As shown in the above figure, TEXT and DATA are closely next to each other in the example. In fact, regardless of DATA and TEXT are adjacent, the linker can know the offset of these two segments. Based on this offset, the relative offset of any instruction in the TEXT segment relative to the starting address of the DATA segment can be calculated. As shown in the figure above, no matter which virtual address the TEXT segment is placed on, assuming a mov instruction is at the 0xe0 offset inside TEXT, then we can know that the relative offset position of the DATA segment is: the size of the TEXT segment - the mov instruction is at the TEXT Internal offset = 0xXXXXE000 - 0xXXXX00E0 = 0xDF20
Key point #2 - Calculation of relative offset of instructions on X86
If you use relative position for processing, you can see The code can be made position independent. But on the X86 platform, the mov instruction requires an absolute address for data reference, so what should we do?
Judging from the description in "Key Point 1", if we know the address of the current instruction, we can calculate the address of the data segment. There is no instruction to obtain the value of the current instruction pointer register IP on the X86 platform (RIP can be accessed directly on X64), but it can be obtained through a little trick. Let’s look at a piece of pseudo code:

Figure 6 - X86 platform acquisition instruction address assembly
When this code is actually run, the following things will happen :
When the CPU executes call STUB, it will save the address of the next instruction to the stack, and then jump to the label STUB for execution.
The instruction at STUB is pop ebx, so the address of the "pop ebx" instruction is popped from the stack into the ebx register, so that the value of the IP register is obtained. .
1. Global offset table GOT
After understanding the previous points, let’s take a look at how to implement position on X86 Independent data reference, this feature is implemented through the global offset table (GOT).
GOT is a table saved in data p, which records many address fields (entry). Suppose an instruction wants to refer to a variable. It does not directly use the absolute address, but refers to an entry in the GOT. The address of the GOT table in data p is clear, and the entry of the GOT contains the absolute address of the variable.

Figure 7 - Relationship between code address and GOT table entry
As shown in the figure above, according to "Key Point 1" and "Key Point 2", we can first Obtain the value of the current IP, and then calculate the absolute address of the GOT table. Since the offset of the variable's address entry in the GOT table is also known, position-independent data access can be achieved.
Take the pseudocode of an absolute address mov instruction as an example (X86 platform):

Figure 8 - Example of a position-related mov instruction
If you want to turn it into position-independent code, you need a few more steps

Figure 9 - Example of position-independent mov instruction combined with GOT
Through the above steps, you can achieve address-independent code access to variables. But there is another question, how does the VAR_ADDR value stored in the GOT table become the actual absolute address?
Assume there is a libtest.so and a global variable g_var. After we pass readelf -r libtest.so, we will see the following output
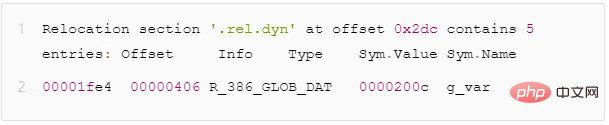
Figure 10 - rel.dyn segment global variable redirection description field
The dynamic loader will parse the rel.dyn segment. When it sees that the redirection type is R_386_GLOB_DAT, it will do the following: actualize the symbol g_var Replace the address value to offset 0x1fe4 (that is, replace the value of Sym.Value with the actual address value)
2. Position-independent implementation of function calls
Theoretically, the PIC implementation of the function can also be position independent in the same way as the data reference GOT table. Instead of using the address of the function directly, the actual absolute address of the function is found by looking up the GOT. But in fact, the PIC characteristics of the function do not do this, and the actual situation is more complicated. Why not follow the same method as data references and first look at a concept: delayed binding.
For dynamic library functions, the actual address of the function is unknown before it is loaded into the program's address space. The dynamic loader will handle these problems and resolve the actual address. This process Call it binding. The binding action will take some time because the loader has to go through special table lookup and replacement operations.
如果动态库有成百上千个函数接口,而实际的进程只用到了其中的几十个接口,如果全部都在加载的时候进行绑定操作,没有意义并且非常耗时。因此提出了延迟绑定的概念,程序只有在使用到对应接口时才实时地绑定接口地址。
因为有了延迟绑定的需求,所以函数的PIC实现和数据访问的PIC有所区别。为了实现延迟绑定,就额外增加了一个间接表PLT(过程链接表)。
PLT搭配GOT实现延迟绑定的过程如下:
第一次调用函数
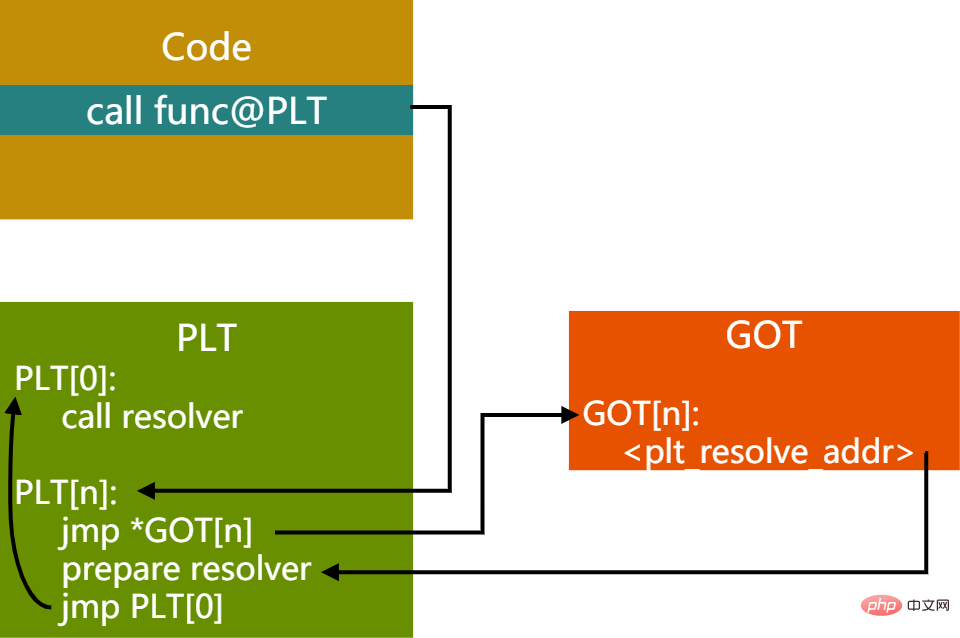
图11 - 首次调用PIC函数时PLT,GOT关系
首先跳到PLT表对应函数地址PLT[n],然后取出GOT中对应的entry。GOT[n]里保存了实际要跳转的函数的地址,首次执行时此值为PLT[n]的prepare resolver的地址,这里准备了要解析的函数的相关参数,然后到PLT[0]处调用resolver进行解析。
resolver函数会做几件事情:
(1)解析出代码想要调用的func函数的实际地址A
(2)用实际地址A覆盖GOT[n]保存的plt_resolve_addr的值
(3)调用func函数
首次调用后,上图的链接关系会变成下图所示:
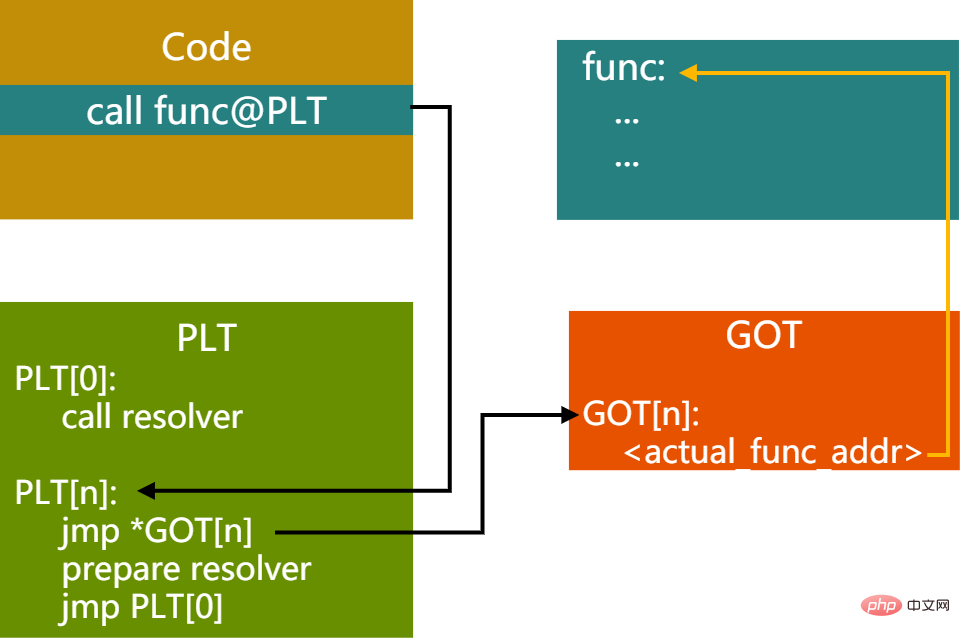
图12 - 首次调用PIC函数后PLT,GOT关系
随后的调用函数过程,就不需要再走resolver过程了
三、位置无关可执行程序PIE
PIE,全称Position Independent Executable。2000年早期及以前,PIC用于动态库。对于可执行程序来讲,仍然是使用绝对地址链接,它可以使用动态库,但程序本身的各个segment地址仍然是固定的。随着ASLR的出现,可执行程序运行时各个segment的虚拟地址能够随机分布,这样就让攻击者难以预测程序运行地址,让缓存溢出攻击变得更困难。OS在使能ASLR的时候,会检查可执行程序是否是PIE的可执行程序。gcc选项中添加-fPIE会产生相关代码。
四、Linux ASLR机制和PIE的关系
ASLR的全称为 Address Space Layout Randomization。在Linux 2.6.12 中被引入到 Linux 系统,它将进程的某些虚拟地址进行随机化,增大了入侵者预测目的地址的难度,降低应用程序被攻击成功的风险。
在Linux系统上,ASLR有三个级别
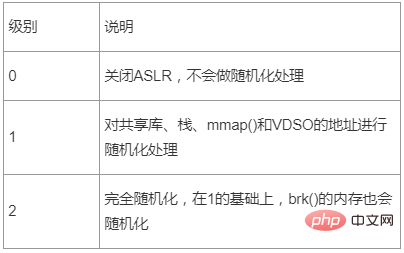
表2 - ASLR级别描述
ASLR的级别通过两种方式配置:
echo level > /proc/sys/kernel/randomize_va_space
或
sysctl -w kernel.randomize_va_space=level
例子:
echo 0 > /proc/sys/kernel/randomize_va_space 关闭地址随机化
或
sysctl -w kernel.randomize_va_space=2 最大级别的地址随机化
我们还是以文章开头的那个程序来说明ASLR在不同级别下时如何表现的,首先在ASLR关闭的情况下,相关地址不变,输出如下:

图13 - ASLR=0时虚拟地址空间分配情况
我们把ASLR级别设置为1,运行两次,看看结果:
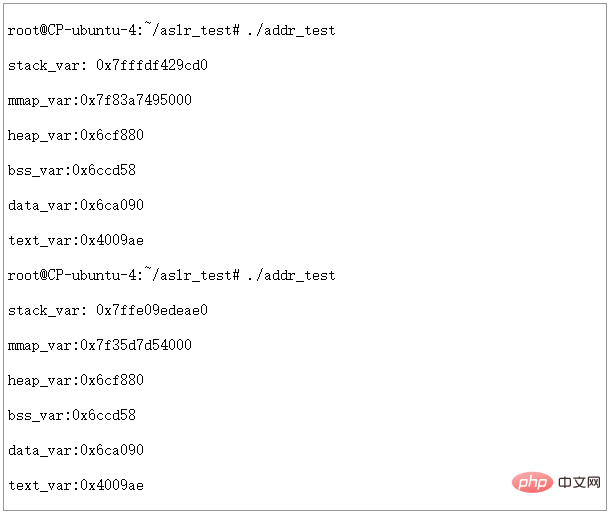
图14 - ASLR=1时虚拟地址空间分配情况
可以看到STACK和MMAP的地址发生了变化。堆、数据段、代码段仍然是固定地址。
接下来我们把ASLR级别设置为2,运行两次,看看结果:
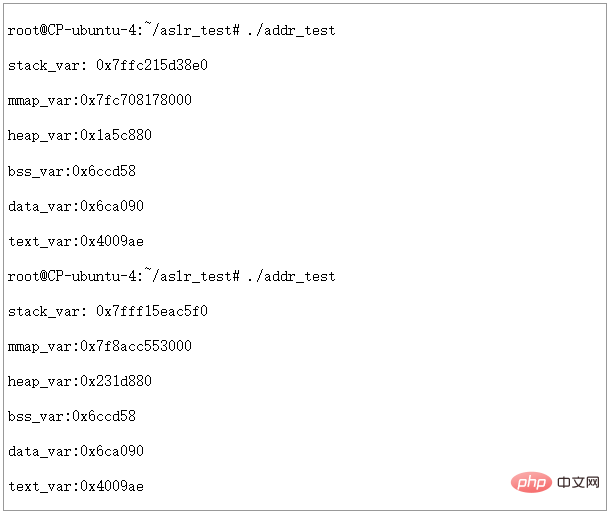
图15 - ASLR=2,PIE不启用时虚拟地址空间分配情况
可以看到此时堆的地址也发生了变化,但是我们发现BSS,DATA,TEXT段的地址仍然是固定的,不是说ASLR=2的时候,是完全随机化吗?
这里就引出了PIE和ASLR的关系了。从上面的实验可以看出,如果不对可执行文件做一些特殊处理,ASLR即使在设置为完全随机化的时候,也仅能对STACK,HEAP,MMAP等运行时才分配的地址空间进行随机化,而可执行文件本身的BSS,DATA,TEXT等没有办法随机化。结合文章前面讲到的PIE相关知识,我们也很容易理解这一点,因为编译和链接过程中,如果没有PIE的选项,生成的可执行文件里都是位置相关的代码。如果OS不管这一点,ASLR=2时也将BSS,DATA,TEXT等随意排布,可想而知程序根本不能正常运行起来。
明白了原因,我们在编译时加入PIE选项,然后在ASLR=2时重新运行一下看看结果如何
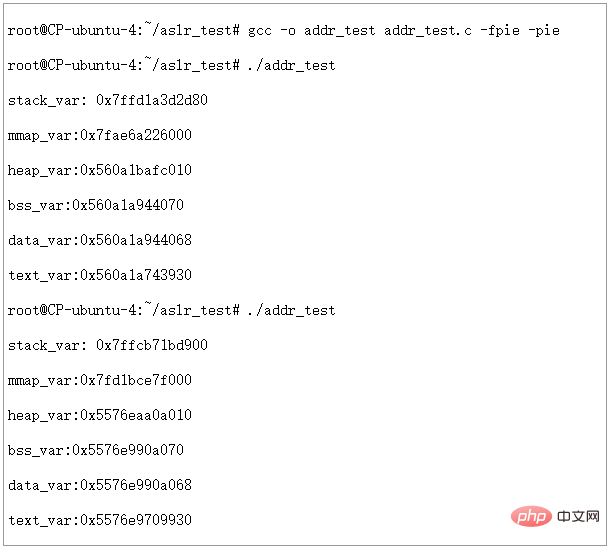
图16 - ASLR=2,PIE启用时虚拟地址空间分配情况
It can be seen that when PIE is turned on, with ASLR=2, the virtual address of each segment can be completely randomized.
Related recommendations: "Linux Video Tutorial"
The above is the detailed content of what is linux pic. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



