

What are the basic characteristics of web2.0 technology

The basic characteristics of web2.0 technology: 1. "Multiple people participate"; in Web1.0, Internet content is customized by a few editors (or webmasters), while in Web2.0 everyone Is a contributor of content. 2. "Readable and writable Internet"; the Internet in Web1.0 is a "readable Internet", while Web2.0 is a "writable and readable Internet".

The operating environment of this tutorial: Windows 7 system, Dell G3 computer.
Web 2.0 is the collective name for a new type of Internet applications relative to Web 1.0 (the Internet model before 2003). It is a revolution from core content to external applications. The development from the Web 1.0 model of simply browsing html web pages through a web browser to the Web 2.0 Internet model with richer content, stronger connections, and stronger tools has become a new development trend of the Internet. Web 2.0 is a typical embodiment of the future-oriented, people-oriented Innovation 2.0 model in the Internet field brought about by the network revolution triggered by the development of information technology. It is a vivid annotation of the innovation and democratization process from professionals weaving the web to all users participating in weaving the web.
Basic characteristics of web2.0 technology
Compared with web1.0, web2.0 has the following characteristics:
1. Multi-person participation
In Web1.0, Internet content was customized by a few editors (or webmasters), such as Sohu; while in Web2.0, everyone Is a contributor of content. The content of Web2.0 is more diverse: tags, multimedia, online collaboration, etc. In the Web2.0 information acquisition channel, RSS subscription plays a very important role.
2. Readable and writable Internet
In Web1.0, the Internet is a "readable Internet", while Web2.0 is a "writable and readable Internet" ". Although everyone contributes to the information feed, on a grand scale it is a small number of people who contribute most of the content.
Seven Principles of Web2.0
1. The Internet as a platform
As many important The same concept as Web 2.0 does not have a clear boundary, but a gravity core. We might as well think of Web 2.0 as a set of principles and practices, whereby websites far or near the core are organized into a solar system-like network system. These websites more or less embody the principles of Web 2.0. It can be said that Web 2.0 is a typical embodiment of the future-oriented, people-oriented Innovation 2.0 model characterized by open innovation and joint innovation brought about by the development of the information revolution in the Internet field. It is a process where professionals weave the web and all users participate in weaving the web. A vivid commentary on the innovation democratization process.
At the first Web 2.0 conference in October 2004, John Battelle and I outlined a preliminary set of principles in our respective opening remarks. The first of these principles is "the Internet as a platform." This was also the battle cry of Netscape, the darling of Web 1.0, but Netscape fell in the war with Microsoft. Additionally, two of our early Web 1.0 role models, DoubleClick and Akamai, were pioneers in using the Web as a platform. People often don't think of this as a network service, but in fact, the advertising service was the first widely used network service, and it was also the first widely used mashup. If you use another recently popular words. Each banner ad is designed to work seamlessly between the two sites, delivering an integrated page to readers on another computer.
Akamai also regards the network as a platform, and at a deeper level, builds a transparent caching and content distribution network to reduce broadband congestion.
Nevertheless, these pioneers provide a useful comparison, because when latecomers encounter the same problems, they can further extend the solutions of the pioneers, and thus have a deeper understanding of the nature of the new platform. DoubleClick and Akamai are both pioneers of Web 2.0. At the same time, we can also see that more applications can be realized by introducing more Web 2.0 design patterns.
2. Leverage collective intelligence
Behind the success stories of those giants who were born in the Web 1.0 era, survived, and continue to lead the Web 2.0 era, There is a core principle that they use the power of the Internet to harness collective intelligence
-Hyperlinks are the foundation of the Internet. When users add new content and new websites, they will be limited to a specific network structure where other users discover the content and establish links. Like synapses in the brain, interconnected networks will grow organically as the connections to each other become stronger through replication and reinforcement, as a direct result of all the activities of all network users.
--Yahoo! was the first great success story, born out of a catalog, or link catalog, a compilation of the best work of tens of thousands or even millions of Internet users. Although Yahoo! later entered the business of creating a variety of content, its role as a portal to collect the collective works of Internet users remains the core of its value.
--Google's breakthrough in search lies in PageRank technology, which quickly made it the undisputed leader in the search market. PageRank is a method that utilizes the link structure of the network, rather than just using the attributes of the document, to achieve better search results.
--eBay's product is the collective activity of all its users. Like the network itself, eBay grows organically with the activities of its users, and the company's role is as an enabler of a specific environment. The user's actions take place in this environment. What's more, eBay's competitive advantage comes almost entirely from its critical mass of buyers and sellers, which makes the products of many of its competitors significantly less attractive.
--Amazon sells the same products as competitors such as Barnesandnoble.com, and these companies receive the same product descriptions, cover images, and catalogs from sellers. The difference is that Amazon has created a science of stimulating user participation. Amazon has more than an order of magnitude higher user ratings than its competitors, more invitations to engage users in a variety of ways on nearly every page, and more importantly, they use user activity to Produce better search results. Search results for Barnesandnoble.com are likely to point to the company's own products, or to sponsored results, while Amazon always leads with what's called "most popular," a real-time calculation based not just on sales but a number of other What Amazon insiders call a factor surrounding product "flow." With user engagement an order of magnitude higher than its rivals, it's no surprise that Amazon outsells its competitors.
Now, innovative companies that possess this insight and potentially extend it are leaving their mark on the Internet.
Wikipedia is an online encyclopedia based on a seemingly impossible concept. The idea is that an entry can be added by any Internet user and edited by anyone else. Undoubtedly, this is an extreme experiment in trust, placing Eric Raymond's maxim (derived from the context of open source software): "With enough eyeballs, all program defects will be eliminated." "With enough eyeballs, all bugs are shallow" is applied to content creation. Wikipedia is already among the top 100 websites in the world, and many believe it will soon be among the top 10. This is a profound change in content creation.
Websites like del.icio.us (delicious bookmarks) and Flickr, whose companies have gained a lot of attention recently, have become popular in what has been called "folksonomy" (differentiation). Become a pioneer in the concept of traditional classification. "Focus classification" is a way of collaboratively classifying websites using keywords freely selected by users, and these keywords are generally called tags. Labeling uses multiple, overlapping associations like those used by the brain itself, rather than rigid categories. To give a classic example, on the Flickr website, a photo of a puppy may be tagged with "puppy" and "cute," allowing the system to search in a natural way that results from user behavior.
Collaborative spam filtering products, such as Cloudmark, aggregate the many independent decisions email users make about whether an email is or is not spam, rather than relying on analyzing the email itself. of those systems.
It is almost axiomatic that the great Internet successes do not actively promote their products everywhere. They use "viral marketing", which means that some referrals spread directly from one user to another. If a website or product relies on advertising for promotion, you can almost certainly conclude that it is not Web 2.0.
Even much of the Internet infrastructure itself, including the Linux, Apache, MySQL, and Perl, PHP, or Python code used in most web servers, relies on open source peer-production. )The way. It contains a collective, network-given wisdom. There are at least 100,000 open source software projects listed on the SourceForge.net website. Anyone can add a project, and anyone can download and use the project code.
At the same time, new projects migrate from the edge to the center as a result of user usage. An organic acceptance process for software relies almost entirely on viral marketing. At the same time, new projects migrate from the edge to the center as a result of user adoption, an organic software adoption process that relies almost entirely on viral marketing.
Experience is: the network effect derived from user contributions is the key to dominating the market in the Web 2.0 era.
3. Data is the next Intel Inside
Every important Internet application is now driven by a specialized database: Google's web crawler, Yahoo!'s directory (and web crawler), Amazon's product database, eBay's product database and sellers, MapQuest's maps Database, Napster's distributed song library. As Hal Varian said in a private conversation last year, "SQL is the new HTML." Database management is a core competency of Web 2.0 companies, and its importance is such that we sometimes call these programs "infoware" rather than just software.
This fact also raises a key question: Who owns the data?
In the Internet age, we may have seen cases where control of databases led to market dominance and huge financial returns. The monopoly on domain name registration originally granted by U.S. government decree to Network Solutions (later acquired by Verisign) was the Internet's first cash cow. While we argue that generating business advantage by controlling software's APIs will become much more difficult in the Internet age, the same cannot be said for controlling critical data resources, especially when those data resources are expensive to create or easily proliferated via network effects. When giving back.
Pay attention to the copyright statement below each map provided by MapQuest, maps.yahoo.com, maps.msn.com, or maps.google.com. You will find a line like "Map Copyright" NavTeq, TeleAtlas", or if you are using a new satellite imagery service, you will see the words "Image copyright Digital Globe". These companies have made significant investments in their databases. (NavTeq alone has announced a $750 million investment to create its street address and route database. Digital Globe is investing $500 million to launch its own satellites to improve government-provided imagery.) NavTeq has actually done There's a lot of imitation of Intel's familiar Intel Inside logo: cars with navigation systems, for example, are stamped "NavTeq Onboard." Data is the de facto Intel Inside for many such programs, and is the only information source component for some systems whose software systems are mostly open source or commercial.
The current fierce competition in the field of web mapping shows that neglect of the importance of owning the core data of the software will ultimately weaken its competitive position. MapQuest was the first to enter the map field in 1995, followed by Yahoo!, then Microsoft, and more recently Google decided to enter the market. They can easily provide a competitive program by licensing the same data.
However, in contrast is Amazon.com’s competitive position. Like competitors like Barnesandnoble.com, its original database comes from ISBN registrar R. Bowker. But unlike MapQuest, Amazon has greatly enhanced its data, adding data provided by publishers, such as cover images, tables of contents, indexes, and sample materials. More importantly, they leveraged their users to annotate the data, so that a decade later, Amazon, not Bowker, became the primary source of bibliographic information, a reference source for scholars, librarians, and consumers. Amazon also introduced its proprietary identifier, the ASIN, which corresponds to an ISBN when it exists, and creates an equivalent namespace when a product does not have an ISBN. Amazon thus effectively "absorbs and expands" its data providers.
Imagine if MapQuest had done the same thing, using their users to annotate maps and routes, adding a new layer of value. Then it will cause far greater difficulties for other competitors who only enter this market by licensing the basic data.
The recent introduction of Google Maps has provided a living laboratory for competition between app sellers and their data providers. Google's lightweight programming model has led to the emergence of countless value-added services that use data hybridization to combine Google's maps with other data sources accessible through the Internet. A great example of this hybrid is Paul Rademacher's housingmaps.com, which combines Google maps with Craigslist apartment rental and home purchase data to create an interactive home tour. Search Tools.
Currently, these hybrids are mostly innovative experimental products implemented by programmers. But corporate action will follow. And, one can already spot this in at least one category of developers. Google has taken the role of data source provider away from Navteq and positioned itself as an endearing intermediary. In the next few years, we will see a battle between data providers and application vendors, as both camps realize how important certain data categories are as building blocks for building Web 2.0 applications.
The race has involved having specific categories of core data: location, identity, public event calendar, product identity, namespace, etc. In many cases, where there is a huge cost to create the data, there may be an opportunity to do it all with a single source of data the way Intel Inside does. In other cases, the winners will be those companies that achieve critical mass through user aggregation and integrate the aggregated data into system services.
For example, in the field of identity, PayPal, Amazon’s One-Click, and communication systems with millions of users may become legitimate competitors in creating a network-wide identity database. (For that matter, Google’s recent attempt to use mobile phone numbers as Gmail account identifiers may be a step toward borrowing and extending the phone system.) Meanwhile, startups like Sxip are exploring the possibility of federated identities to Seeking a "distributed one-click" approach to provide a seamless Web 2.0 identity subsystem. In the calendar field, EVDB is an attempt to build the world's largest shared calendar through a wiki-style participation system. While the jury is still out on the success of any particular startup or approach, it's clear that standards and solutions in these areas are effectively turning some data into reliable, reliable "internet operating systems." subsystems and will enable next-generation applications.
Regarding data, a further aspect that must be noted is that users are concerned about their privacy and permissions over their data. In many early web programs, copyright was only loosely enforced. Amazon, for example, claims ownership of any review submitted to its site, but lacks enforcement and people can repost the same review anywhere else. However, as many companies begin to realize that control of data has the potential to become their primary source of competitive advantage, we will see more intense attempts at such controls.
Just as the growth of proprietary software led to the free software movement, over the next decade we will see the growth of proprietary databases lead to the free data movement. We can see precursors to this countermovement in open data projects like Wikipedia, Creative Commons, and software projects like Greasemonkey (which lets users decide how data is displayed on their computers).
4. The end of the software release cycle
As mentioned above in the comparison between Google and Netscape, the representative feature of software in the Internet era is that it should be Delivered as a service. This fact leads to many fundamental changes in the business models of such companies.
1. Operations must become a core competitiveness. Google or Yahoo!'s expertise in product development must be matched by expertise in day-to-day operations. The change from software as a manufactured product to software as a service is so fundamental that the software will no longer be able to do its job unless it is maintained on a daily basis. Google must continuously crawl the Internet and update its index, continuously filter out link spam and other things that affect its results, continuously and dynamically respond to tens of millions of asynchronous user queries, and synchronously match these queries with contextually relevant ads. .
So it’s not surprising that Google’s system management, networking, and load balancing technology may be more tightly guarded than its search algorithms. Google's success in automating these steps is a key aspect of its cost advantage over its competitors.
It’s also no surprise that scripting languages like Perl, Python, PHP, and now Ruby play a major role in Web 2.0 companies. Sun's first network administrator, Hassan Schroeder, once famously described Perl as "the duct tape of the internet." In fact, dynamic languages (often referred to as scripting languages and disparaged by software engineers in the software artifact era) are the favored tools of system and network administrators, as well as program developers who create dynamic systems that can be frequently updated.
2. Users must be treated as co-developers, which comes from a reflection on open source development practices (even if the software involved is unlikely to be released under an open source license) ). The open source motto "release early and release often" has actually evolved into a more extreme positioning: "the perpetual beta." The product is developed in an open state, and new features are added at a monthly, weekly, or even daily rate. Gmail, Google Maps, Flickr, del.icio.us, and other similar services will likely remain in beta at some stage for years.
Therefore, monitoring user behavior in real time to examine which new features are used and how they are used will become another necessary core competitiveness. A developer working for a major online services network commented: "We deliver two or three new features every day in certain parts of the site, and if users don't adopt them, we remove them. If users If we like them, we'll roll them out across the site." Cal Henderson, Flickr's chief developer, recently revealed how they deploy one in as little as every half hour New version. Obviously, this is a very different development model from the traditional method. While not all web programs are developed in an extreme manner like Flickr, almost all web programs have a development cycle that is very different from any PC or client-server era. Because of this, ZDnet magazine concluded that Microsoft will not defeat Google: "Microsoft's business model relies on everyone upgrading their computing environment every two to three years. Google's model relies on anyone doing their own work in their computing environment every day. Explore new things."
Although Microsoft has demonstrated a strong ability to learn from the competition and ultimately do the best, there is no doubt that this time the competition requires Microsoft (and by extension any existing software company) To become a company that is significantly different on a deeper level. Companies that are born Web 2.0 enjoy a natural advantage because they don't have to break away from legacy models (and their accompanying business models and revenue streams).
5. Lightweight Programming ModelOnce the concept of network services takes root, large companies will join the fray with complex network service stacks. This network services stack is designed to establish a more reliable programming environment for distributed programs.
However, just as the Internet succeeded precisely because it overturned many hypertext theories, RSS replaced simple pragmatism with perfect design and has become probably the most widely used network because of its simplicity. Services, while those complex enterprise network services have not yet been widely used.
Similarly, Amazon.com's network services come in two forms: one adheres to the formalism of the SOAP (Simple Object Access Protocol, Simple Object Access Protocol) network service stack; the other simply uses HTTP Providing XML data outside of the protocol is sometimes called REST (Representational State Transfer) in a lightweight manner. While higher business value B2B connections (such as those between Amazon and some retail partners like ToysRUs) use the SOAP stack, Amazon reports that 95% of usage comes from lightweight REST services.
The same demand for simplicity can be seen in other "plain" network services. Google's recent launch of Google Maps is one example. Google Maps' simple AJAX (Javascript and XML) interface was quickly deciphered by programmers, who then further mixed its data into new services.
Map-related web services have been around for a while, such as GIS (geographic information systems) like ESRI, and MapPoint from MapQuest and Microsoft. But Google Maps has excited the world with its simplicity. While vendor-supported web services previously required formal agreements between the parties, Google Maps was implemented in a way that allowed data to be captured, and programmers quickly discovered ways to creatively reuse the data.
There are several important lessons here:
1. Support a lightweight programming model that allows loosely coupled systems. The complex design of web services stacks developed by enterprises is designed to enable tight integration. While this is necessary in many cases, many of the most important applications can in fact remain loosely coupled, or even tenuously coupled. The concept of Web 2.0 is completely different from the concept of traditional IT.
2. Think syndication rather than coordination. Simple web services, such as RSS and REST-based web services, are used to aggregate data outbound but do not control what happens when it reaches the other end of the connection. This idea is fundamental to the Internet itself, a reflection of the so-called end-to-end principle.
3. Programmability and mixability design. Like the original Internet, systems like RSS and AJAX all have this in common: the barriers to reuse are very low. Much useful software is in fact open source, and even if it isn't, there isn't much in place to protect its intellectual property. The "view source" option of Internet browsers allows many users to copy any other user's web page; RSS is designed to enable users to view the content they need when they need it, rather than at the request of the information provider; most successful Web services are those most susceptible to adopting new directions not thought of by the service's creators. The term "Some Rights Reserved", popularized by the Creative Commons agreement, serves as a useful guidepost compared to the more common "all rights reserved".
6. Software goes beyond a single device Another Web 2.0 feature worth mentioning is the fact that Web 2.0 is no longer limited to the PC platform. In his farewell advice to Microsoft, long-time Microsoft developer Dave Stutz noted that "useful software written that goes beyond a single device will be more profitable for a long time to come". Of course, any network program can be considered software that goes beyond a single device. After all, even the simplest Internet programs involve at least two computers: one is responsible for the web server, and the other is responsible for the browser. And, as we've already discussed, developing the network as a platform extends this concept to composite applications composed of services provided by multiple computers. But like many areas of Web 2.0, in those areas "2.0-ness" is not entirely new, but a more perfect realization of the true potential of the Internet platform. The idea that software transcends a single device gives us critical insights into designing programs and services for new platforms. By far, iTunes is the best example of this principle. The program extends seamlessly from the handheld device into the vast Internet backend, where the PC plays the role of a local cache and control site. There have been many previous attempts to bring content from the Internet to portable devices, but the iPod/iTunes combo was the first of its kind designed from the ground up to work across multiple devices. TiVo is another good example. iTunes and TiVo also embody some other core principles of Web 2.0. None of them are network programs themselves, but they all leverage the power of the Internet platform to make the network a seamless and almost imperceptible part of their system. Data management is clearly at the heart of the value they provide. They are also services, not packaged programs (although in the case of iTunes, it can be used as a packaged program to only manage the user's local data). Not only that, both TiVo and iTunes demonstrate some emerging applications of collective intelligence. Although for each case, the experiment is to deal with the same network IP entrance. There is only a limited participation system in iTunes, although the recent addition of podcasting has made this rule more regular. This is one area of Web 2.0 where we hope to see great changes, as more and more devices are connected to this new platform. What programs might emerge when our phones and cars report data even though they don't consume it? Real-time traffic monitoring, flash mobs, and citizen media are just a few early warning signs of what the new platforms are capable of. 7. Rich user experience It can be traced back to the Viola browser developed by Pei Wei in 1992. The Internet has been used to browse web pages. transfer "applets" and other active content to the server. The introduction of Java in 1995 revolved around the delivery of such small programs. JavaScript and later DHTML were introduced as lightweight ways to provide programmability and rich user experiences to the client. A few years ago, Macromedia coined the term "Rich Internet Applications" (a term also used by Flash competitor open source Laszlo Systems) to highlight that Flash could not only deliver multimedia content, but also GUI (Graphical User Interface) style application experience. However, the potential of the Internet to deliver entire applications did not become mainstream until Google introduced Gmail, followed closely by the Google Maps program, some Internet-based programs with rich user interfaces and the interactivity of PC programs. app. The set of technologies used by Google was named AJAX in a seminar paper by Jesse James Garrett of the web design company Adaptive Path. He wrote: Ajax is not a technology. It is actually several technologies, each thriving in its own right, combined in powerful new ways. Ajax covers: --Use XHTML and CSS to achieve display based on various standards. --Use the Document Object Model to achieve dynamic display and interaction. --Use XML and XSLT to realize data exchange and operation. --Use XMLHttpRequest to implement asynchronous data retrieval. --JavaScript binds all of this together. AJAX is also a key component of Web 2.0 programs such as Flickr, now owned by Yahoo!, 37signals programs basecamp and backpack, and other Google programs such as Gmail and Orkut. We are entering an unprecedented period of user interface innovation, because Internet developers can finally create web applications that are as rich as native PC-based applications. Interestingly, many of the features being explored now have been around for many years. In the late 1990s, both Microsoft and Netscape had an idea of what was now finally being recognized, but their battles over the standards to be adopted made it difficult to implement cross-browser applications. Writing this kind of program was only possible when Microsoft was definitely winning the browser wars, and when there was really only one browser standard to target. At the same time, while Firefox has reintroduced competition into the browser market, at least for now we haven't seen such a destructive fight over Internet standards that we'd be thrown back to the '90s. Over the next few years, we will see many new network programs that are not only truly novel programs, but also rich network renditions of PC programs. Each platform change so far has also created an opportunity to change the leadership of those programs that were dominant in the old platform. Gmail has provided some interesting innovations in email, combining the power of the Internet (anywhere access, deep database capabilities, searchability) with a user interface that is close to the PC interface in terms of ease of use. Combine. Meanwhile, other mail programs on the PC platform were encroaching on the field from the other side by adding IM and presence capabilities. How far are we from integrated communications clients? These integrated communications clients should integrate email, instant messaging, and mobile phones, and should use VoIP to add voice capabilities to the rich functionality of web applications. The race has already begun. We can also easily see how Web 2.0 can reinvent the address book. A Web 2.0 style address book would treat the local address book on your PC or phone as nothing more than a cache of contacts that you explicitly asked the system to remember. Meanwhile, a Gmail-style asynchronous proxy based on the Internet will save every message sent or received, every email address and every phone number used, and create social network-inspired algorithms to decide when a Which should be provided as an alternative when the answer cannot be found in the local cache. In the absence of an answer, the system queries the wider social network. A Web 2.0 word processor will support wiki-style collaborative editing, rather than just working on individual documents. But the program will also support the kind of rich formatting we've come to expect in PC-based word processors. Writely is an excellent example of such a program, although it has yet to gain widespread attention. Furthermore, the Web 2.0 revolution will not be limited to PC programs. For example, in enterprise applications like CRM, Salesforce.com demonstrates how the Internet can be used to deliver software as a service. For new entrants, the competitive opportunity lies in fully developing the potential of Web 2.0. Successful companies will create programs that learn from their users, leveraging systems for participation to build a decisive advantage not only in the interface of the software but also in the richness of the data being shared. For more related knowledge, please visit the FAQ column!
The above is the detailed content of What are the basic characteristics of web2.0 technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

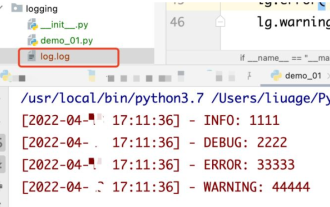 How to use python+Flask to realize real-time update and display of logs on web pages
May 17, 2023 am 11:07 AM
How to use python+Flask to realize real-time update and display of logs on web pages
May 17, 2023 am 11:07 AM
1. Log output to file using module: logging can generate a custom level log, and can output the log to a specified path. Log level: debug (debug log) = 5) {clearTimeout (time) // If all results obtained 10 consecutive times are empty Log clearing scheduled task}return}if(data.log_type==2){//If a new log is obtained for(i=0;i
 How to use Nginx web server caddy
May 30, 2023 pm 12:19 PM
How to use Nginx web server caddy
May 30, 2023 pm 12:19 PM
Introduction to Caddy Caddy is a powerful and highly scalable web server that currently has 38K+ stars on Github. Caddy is written in Go language and can be used for static resource hosting and reverse proxy. Caddy has the following main features: Compared with the complex configuration of Nginx, its original Caddyfile configuration is very simple; it can dynamically modify the configuration through the AdminAPI it provides; it supports automated HTTPS configuration by default, and can automatically apply for HTTPS certificates and configure it; it can be expanded to data Tens of thousands of sites; can be executed anywhere with no additional dependencies; written in Go language, memory safety is more guaranteed. First of all, we install it directly in CentO
 Using Jetty7 for Web server processing in Java API development
Jun 18, 2023 am 10:42 AM
Using Jetty7 for Web server processing in Java API development
Jun 18, 2023 am 10:42 AM
Using Jetty7 for Web Server Processing in JavaAPI Development With the development of the Internet, the Web server has become the core part of application development and is also the focus of many enterprises. In order to meet the growing business needs, many developers choose to use Jetty for web server development, and its flexibility and scalability are widely recognized. This article will introduce how to use Jetty7 in JavaAPI development for We
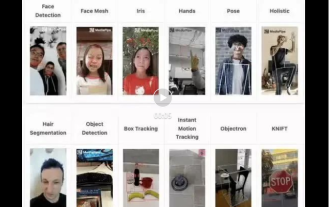 Real-time protection against face-blocking barrages on the web (based on machine learning)
Jun 10, 2023 pm 01:03 PM
Real-time protection against face-blocking barrages on the web (based on machine learning)
Jun 10, 2023 pm 01:03 PM
Face-blocking barrage means that a large number of barrages float by without blocking the person in the video, making it look like they are floating from behind the person. Machine learning has been popular for several years, but many people don’t know that these capabilities can also be run in browsers. This article introduces the practical optimization process in video barrages. At the end of the article, it lists some applicable scenarios for this solution, hoping to open it up. Some ideas. mediapipeDemo (https://google.github.io/mediapipe/) demonstrates the mainstream implementation principle of face-blocking barrage on-demand up upload. The server background calculation extracts the portrait area in the video screen, and converts it into svg storage while the client plays the video. Download svg from the server and combine it with barrage, portrait
 How to implement form validation for web applications using Golang
Jun 24, 2023 am 09:08 AM
How to implement form validation for web applications using Golang
Jun 24, 2023 am 09:08 AM
Form validation is a very important link in web application development. It can check the validity of the data before submitting the form data to avoid security vulnerabilities and data errors in the application. Form validation for web applications can be easily implemented using Golang. This article will introduce how to use Golang to implement form validation for web applications. 1. Basic elements of form validation Before introducing how to implement form validation, we need to know what the basic elements of form validation are. Form elements: form elements are
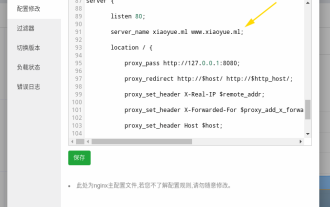 How to configure nginx to ensure that the frps server and web share port 80
Jun 03, 2023 am 08:19 AM
How to configure nginx to ensure that the frps server and web share port 80
Jun 03, 2023 am 08:19 AM
First of all, you will have a doubt, what is frp? Simply put, frp is an intranet penetration tool. After configuring the client, you can access the intranet through the server. Now my server has used nginx as the website, and there is only one port 80. So what should I do if the FRP server also wants to use port 80? After querying, this can be achieved by using nginx's reverse proxy. To add: frps is the server, frpc is the client. Step 1: Modify the nginx.conf configuration file in the server and add the following parameters to http{} in nginx.conf, server{listen80
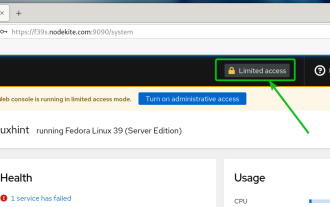 How to enable administrative access from the cockpit web UI
Mar 20, 2024 pm 06:56 PM
How to enable administrative access from the cockpit web UI
Mar 20, 2024 pm 06:56 PM
Cockpit is a web-based graphical interface for Linux servers. It is mainly intended to make managing Linux servers easier for new/expert users. In this article, we will discuss Cockpit access modes and how to switch administrative access to Cockpit from CockpitWebUI. Content Topics: Cockpit Entry Modes Finding the Current Cockpit Access Mode Enable Administrative Access for Cockpit from CockpitWebUI Disabling Administrative Access for Cockpit from CockpitWebUI Conclusion Cockpit Entry Modes The cockpit has two access modes: Restricted Access: This is the default for the cockpit access mode. In this access mode you cannot access the web user from the cockpit
 What are web standards?
Oct 18, 2023 pm 05:24 PM
What are web standards?
Oct 18, 2023 pm 05:24 PM
Web standards are a set of specifications and guidelines developed by W3C and other related organizations. It includes standardization of HTML, CSS, JavaScript, DOM, Web accessibility and performance optimization. By following these standards, the compatibility of pages can be improved. , accessibility, maintainability and performance. The goal of web standards is to enable web content to be displayed and interacted consistently on different platforms, browsers and devices, providing better user experience and development efficiency.