
This article brings you relevant knowledge about Oracle, which mainly organizes issues related to the architecture. Oracle's architecture is generally divided into two parts: Instance (instance) and Database (database), let’s take a look at it, I hope it will be helpful to everyone.

Recommended tutorial: "Oracle Video Tutorial"
Oracle's architecture is generally divided into two parts: Instance (Instance) and Database (Database) .
As shown in Figure 1:
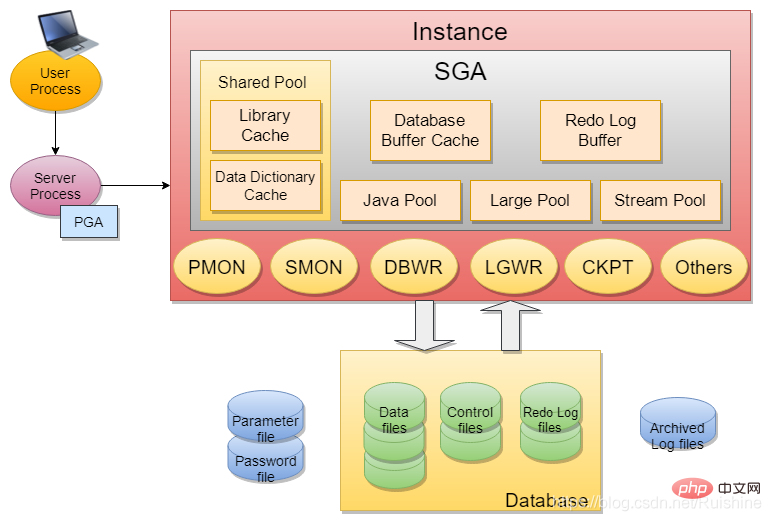
Figure 1 Oracle database architecture
What we usually callOracle Server(Oracle server) is composed of Oracle Instance and Oracle Database, as shown in Figure 2:
Figure 2 Oracle Server
Oracle InstanceInstance mainly contains SGA And some Backgroud Process (for example: PMON, SMON, DBWR, LGWR, CKPT, etc.).
SGA contains 6 basic components: Shared Pool (Library Cache, Data Dictionary Cache), Database Buffer Cache, Redo Log Buffer, Java Pool, Large Pool, stream pool .
The functions of these six basic components will be introduced below.
1) shared pool
What are their respective functions?
Library Cache: The parsing place for SQL and PL/SQL, which stores the contents of compiled and parsed SQL and PL/SQL statements for sharing by all users.
* If the same SQL statement is executed next time, there is no need to parse it and it will be executed immediately from the Library Cache.
* The SIZE of Library Cache will determine the frequency of compiling and parsing SQL statements, thereby determining performance.
* Library Cache contains two parts: Shared SQL Area and Shared PL/SQL Area.
Data Dictionary Cache: Stores important data dictionary information for database use.
* Data Dictionary is the most frequently used, and almost all operations require querying the data dictionary. In order to improve the speed of accessing Data Dictionary, a Cache is needed at this time, and the memory can be accessed when needed.
* The information in Data Dictionary Cache includes Database Files, Tables, Indexes, Columns, Users, Privileges and other database objects.
Server Result Cache: Stores the server-side SQL result set and PL/SQL function return value.
After reading the above explanation, you may feel it is a bit abstract, so I will explain it through an example below.
Suppose a command is submitted on the client, as follows:
SELECT ename,sal FROM emp WHERE empno=7788;
If this statement is submitted to the database for the first time, it needs to be parsed. The parsing process is divided into hard parsing and soft parsing.
Library Cache will load this sql statement and execution plan into it.
What is the purpose of loading these things?
The next time you type the exact same statement (the punctuation marks, capitalization, and spaces are exactly the same), there is no need for hard parsing.
Quick Q&A:
If the client submits another command at this time:
select ename,sal from emp where empno=7788;
Guess, this statement needs to be parsed ?
Answer: Yes.
Small note: Note that the statements must be exactly the same to avoid parsing. Punctuation, capitalization, spaces, etc. must be exactly the same! The benefits of regular writing are reflected here.
As mentioned earlier, if it is a select statement, the result set will be returned after execution. Where is the result set stored?
select ename,sal from emp where empno=7788;
The result set returned by the execution of this statement will be stored in Server Result Cache.
2) Database Buffer Cache
小说明:逻辑读(从内存读)的速度是物理读(从磁盘读)的1万倍呦,所以还是想办法尽量多从内存读哦。
所以,数据缓冲区的大小对数据库的读取速度有直接的影响。
例如用户访问一个表里面的记录时,数据库接收到这个请求后,首先会在Database Buffer Cache中查找是否存在该数据库表的记录,如果有所需的记录就直接从内存中读取该记录返回给用户(有效提升了访问的速度),否则只能去磁盘上去读取。
继续看上面的例子:
select ename,sal from emp where empno=7788;
该条语句以及它的执行计划被放在Library Cache里,但语句涉及到的数据,会放在 Database Buffer Cache 里。
小问答:
Database Buffer Cache是怎么工作的呢?
这就要说一说Database Buffer Cache的设计思想了。
磁盘上存储的是块(block),文件都有文件号,块也有块号。
若要访问磁盘上的块,并不是CPU拿到指令后直接访问磁盘,而是先把块读到内存中的Database Buffer cache里,生成副本,查询或增删改都是对内存中的副本进行操作。如图3所示。
另外,如果是增删操作,操作后会形成脏块,脏块会在恰当时机再写回磁盘原位置,注意哦,可不是立刻写回呦。
也许你会问,为什么不立刻写回呢?
因为:
(1)减少物理IO;
(2)可共享,若后面又有对该块的访问,可直接在内存中进行逻辑读。
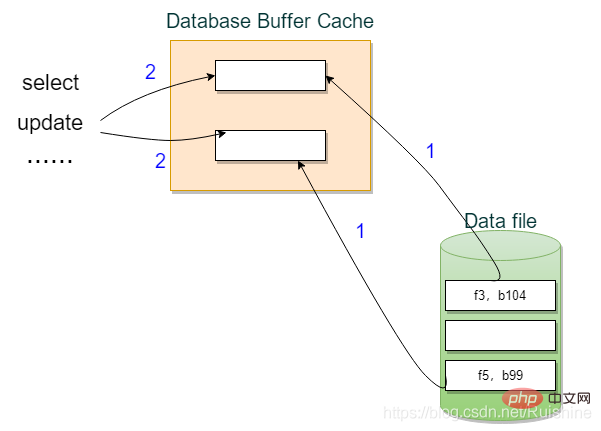
图3 访问数据块
小问答:
为什么要通过内存访问数据块,而不是CPU直接访问磁盘呢?
答:因为相较于CPU,IO的速度实在是太慢了,CPU的速度是IO 的100万倍呢?如果CPU直接访问磁盘的话,会造成大量的IO等待,CPU的利用率会很低。所以,利用速度相当的内存(CPU速度为内存的100倍)做中间缓存,可以有效减少物理IO,提高CPU利用率。
但是,这里会有一个问题。前面说到查询或增删改都是对内存中的副本进行操作,当增删改操作产生脏块时不会立刻写回磁盘。
小问答:
我们设想一下,如果在 Database Buffer Cache 中存放大量未来得及写回磁盘的脏块时,突然出现系统故障(比如断电),导致内存中的数据丢失。而此时磁盘中的块存放的依然是修改前的旧数据,这样岂不是导致前面的修改无效?
要怎样保持事务的一致性呢?
答:如果我们能够保存住提交的记录,在 Database Buffer Cache 中一旦有数据更改,马上写入一个地方记录下来,不就可以保证事务一致性了嘛。
小说明:Instance在断电时会消失,Instance在内存中存放的数据将丢失。这就需要 Redo Log Buffer 发挥它的作用啦。
3)Redo Log Buffer
4)Large Pool(可选)
为了进行大的后台进程操作而分配的内存空间,与 shared pool 管理不同,主要用于共享服
务器的 session memory,RMAN 备份恢复以及并行查询等。
5)Java Pool(可选)
为了 java 虚拟机及应用而分配的内存空间,包含所有 session 指定的 JAVA 代码和数据。
6)Stream Pool(可选)
为了 stream process 而分配的内存空间。stream 技术是为了在不同数据库之间共享数据,
因此,它只对使用了 stream 数据库特性的系统是重要的。
Background process
在正式介绍 Background Process 之前,先简单介绍 Oracle 的 Process 类型。
Oracle Process 有三种类型:
客户端要与服务器连接,在客户端启动起来的进程就是 User Process,一般分为三种形式(sql*plus, 应用程序,web 方式(OEM))。
User Process cannot directly access Oracle. It must access the instance through the corresponding Server Process and then access the database.
When a user logs in to Oracle Server, the User Process and Server Process establish a Connection.
An important part of Oracle Instance. This will be explained in detail next.
Small addition:
Connection & Session
Connection refers to the TCP connection established by an Oracle client and the background and background process (Server Process). As shown in Figure 4:
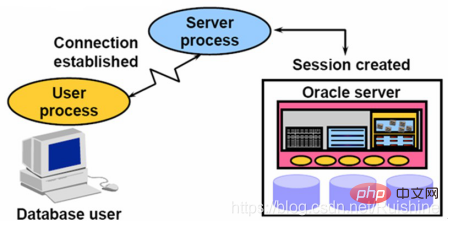
Figure 4 Connection
The connection establishment process can be briefly described as follows:
1. First establish a TCP connection, Oracle authenticates the user's identity, conducts security audits, etc.;
2. When these are passed, Oracle's Server Process will allow the client to use the services provided by Oracle;
3. When the Oracle connection is established, it means that a Session is started. When the connection is disconnected, the session disappears.
Session and Connection complement each other. Session information will be stored in Oracle's Data Dictionary.
You can visually see the difference between Connection and Session through Figure 5.
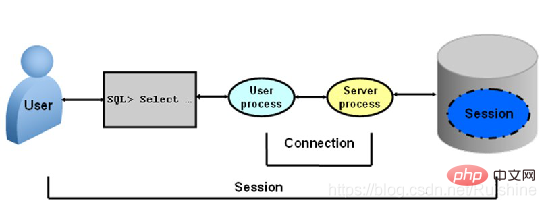
Figure 5 Connection & Session
Background Process (background process) mainly includes: SMON (system monitor process), PMON (process monitoring process) server process), DBWR (database writer process), LGWR (log writer process), CKPT (checkpoint process).
1) PMON (Process Monitor)
The main functions of PMON are as follows:
2) SMON (System Monitor)
The main functions of SMON are as follows:
3) DBWR (Database Writer)
DBWn is the heaviest working process in Oracle. The main functions are as follows:
Small note:
If the database load is relatively large, there are many requests from the client, and there are a large number of IO operations, the buffer contents need to be written to disk frequently. file, then multiple DBWn can be configured at this time (Oracle supports a total of 20 DBWn, DBW0-DBW9, DBWa-DBWg). Usually a small and medium-sized Oracle only needs one DBW0 Process.
Note: When the following situations occur, the DBWR Process will be triggered to write the contents of the Database Buffer Cache to Data Files:
Small addition:
The server process executes the data file Read operations, while DBWR is responsible for performing write operations on the data files.
Quick Q&A:
What does DBWR do when committing?
Answer: Do nothing!
4) LGWR ((LOG Writer))
There is only one LGWR Process in Oracle Instance, and the work of this Process is similar to the DBWR Process. The main functions are as follows:
Write the contents of the Redo Log Buffer to Redo Log Files (the log must be written before DBWR writes dirty blocks).
(Redo Log Buffer is a cyclic Buffer, and the corresponding Redo Log Files is also a cyclic file group. It starts writing from the file head. When the file is full, it will start writing from the file head again, and it will The previous content is overwritten. In order to avoid overwriting the Redo Log Files, you can choose to write it to the Archived Redo Log Files.)
Note: When the following situations occur, the LGWR Process will be triggered to save the Redo Log files. The contents in the Buffer are written to Redo Log Files:
How to ensure that submitted transactions are retained permanently?
Answer: The update operation has been performed as an example.
1. When writing the commit statement, the modification has been written to the Redo Log Buffer;
2. When you see that the submission is successful, it means that the modification has been written to the disk Redo Logfile;
3 . So after the submission is successful, the changes have been synchronized to the disk and will not be lost.
5) CKPT (Checkpoint)
The main functions of CKPT are as follows:
6) ARCn (Archiver)
The main functions of ARCn are as follows:
When Oracle is running in archive mode
This way, even if the disk drive is damaged, the database can be restored to the point of failure.
Through the above learning, first update Figure 1 as follows:
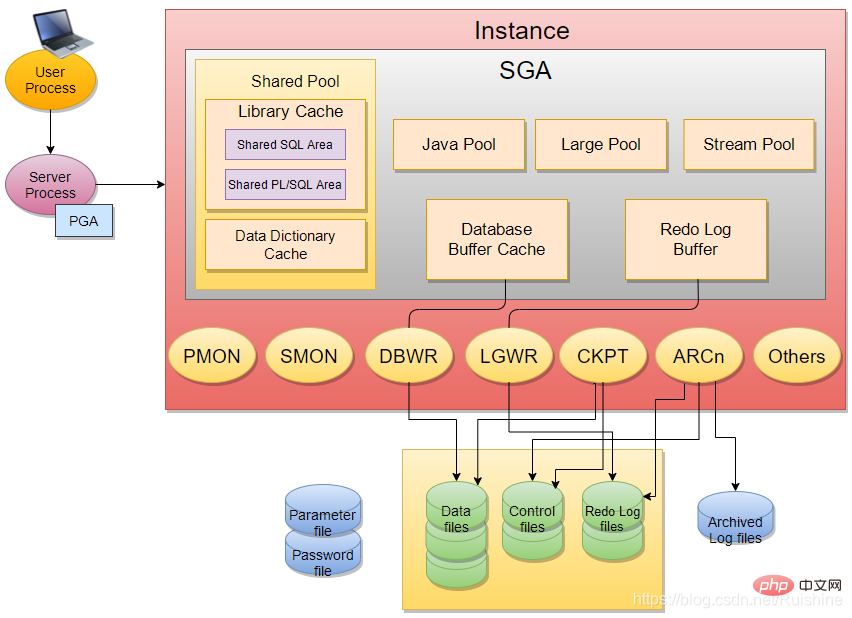
Figure 6 Oracle database architecture
Database is actually composed of a bunch of physical files, mainly used to store data. Database mainly contains three types of files: Data Files, Control Files, and Redo Log Files.
In addition, there are Parameter File, Password File, Achieved Log Files, etc.
1) Data Files
Data Files are used to store data, and the data in Table are stored in Data Files.
2) Control Files
In order to operate the Data File, Oracle provides some Control Files. These Control Files mainly record some control information of the database.
3) Redo Log Files (redo log files)
Redo Log Files record changes in the database. If you put data into the database or modify the data inside, you only need to perform operations on the database. If the modification is made, then the status before modification and the status after modification must be recorded in Redo Log Files, whose function is to restore the Data File.
* For example: there is a transaction in the database that needs to be submitted, but the submission fails, the transaction will be rolled back, then the basis for transaction rollback comes from the Redo Log Files. Redo Log Files record database changes. Regarding this transaction change, if you need to roll back, you need to take out the data in Redo Log Files and restore the Data Files to the state before modification according to the data in Redo Log Files.
4) Parameter File
Any database must have a parameter file. This parameter file specifies the values of some basic parameters and initialization parameters in Oracle.
5) Archived Log Files
Archived Log Files and Redo Log Files complement each other. Redo Log Files is actually a process of repeated use. There will be several (generally (3) fixed files. These fixed files will be used in sequence. After they are full, Oracle will write the file header again and flush out the previous stuff. In order to further enhance the backup and recovery capabilities of the database, these modified information are archived in Archived Log Files before overwriting.
6) Password File
Stores passwords when the user client connects to the backend database system.
Quick Question and Answer:
What is the corresponding relationship between Instance and Database?
Answer: Instance: Database = n: 1
1 Instance can only belong to one database, and multiple Instances can access one database at the same time.
Small supplement:
Oracle’s Memory Structure
Oracle’s Memory Structure actually contains two parts: SGA and PGA
SGA(System Global Area)
PGA (Program Global Area)
Recommended tutorial: "Oracle Video Tutorial"
The above is the detailed content of A brief analysis of Oracle architecture. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



