
 Java
javaTutorial
Example introduction to implement a complex relational expression filter based on Java
Java
javaTutorial
Example introduction to implement a complex relational expression filter based on Java
Example introduction to implement a complex relational expression filter based on Java

This article brings you relevant knowledge about java. It mainly introduces in detail how to implement a complex relational expression filter based on Java. The sample code in the article is explained in detail. Let’s take a look at it. I hope it will be helpful to everyone.

Recommended study: "java video tutorial"
Background
Recently, there is a new need, need Set up a complex relational expression in the background, and analyze whether the user meets the condition based on the user's specified ID. The background sets search conditions similar to ZenTao

but different Yes, there are only two groups in Zen Tao, and each group has at most three conditions
. However, the group and relationship here may be more complicated. There are groups within groups, and each condition is yes and or. Relationship. Due to confidentiality reasons, the prototype will not be released.
Seeing this requirement, as a backend, the first thing that comes to mind is an expression framework like QLEpress. As long as you build an expression, you can quickly filter the target users by parsing the expression. But it is a pity that the front-end classmate quit, because as a data-driven framework using Vue or React, it is too difficult to convert the expression into the above form, so I thought about it and decided to define a data structure by myself. , implement expression parsing. Convenient for front-end students to process.
Analysis preparation
Although the expression is implemented using a class, it is still an expression in essence. Let’s enumerate a simple expression: Let the conditions be a, b, c, d , we construct an expression at will:
boolean result=a>100 && b=10 || (c != 3 && d < 50)
We Analyzing the expression, we can find that the expressions all have common attributes:
Filter field (a, b, c, d), Judgment condition (greater than , less than, not equal to, etc.), Comparison value (a>100 in 100).
In addition, there are several attributes such as association relationship (and, or) and calculation priority.
So we simplify the expression:
Let a>100 =>A,b=10 =>B,c!=3=>C ,d<50= >D, so we get:
result=A && B || (C && D)
Now the question comes, how to deal with priority?
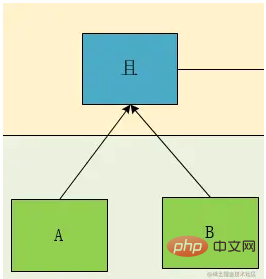
The above expression is obviously a standard inorder expression learned in college, so let’s draw its tree diagram:
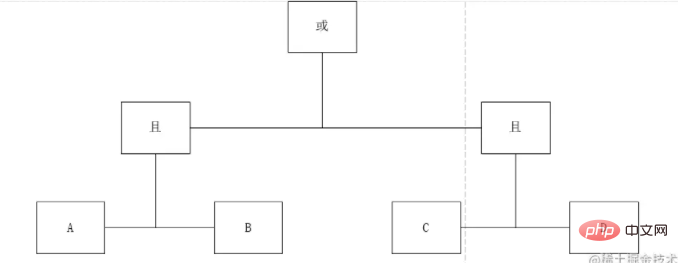
According to this picture, we can clearly see that A and B and C and D are at the same level. Therefore, we design a hierarchical concept Deep according to this theory. We mark it and then do the node type. After a distinction, we can get:
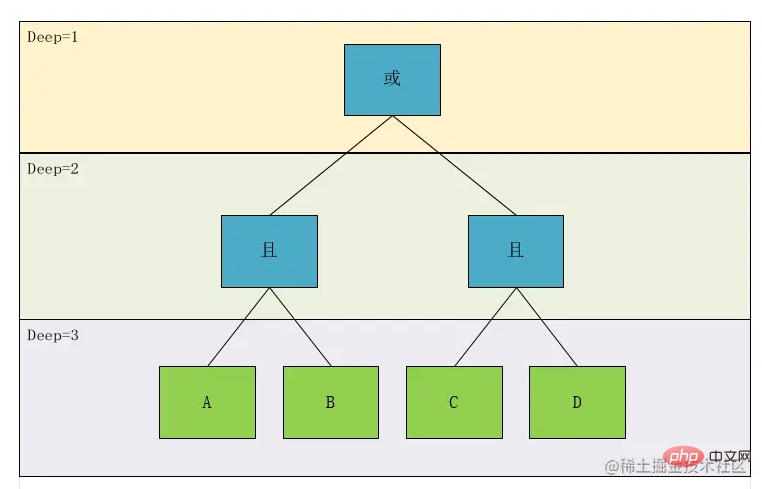
We can see that as a leaf node (the green part in the above figure), relative to its calculation calculation relationship, when it encounters it, it must be calculated first. So for depth priority, we only need to consider non-leaf nodes, that is, the blue node part in the above figure, so we get, the concept of calculating priority can be converted into an expression depth.
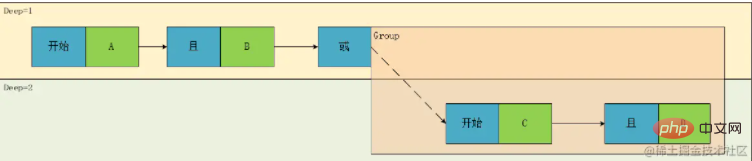
Let’s look at the picture above again. The relationship between Deep1 is the AND or relationship between the results calculated by the two expressions A and B and C and D in Deep2. We set A and B to be G1, C And D is G2, so we find that there are two types of relationship node associations, one is ConditionCondition, and the other is GroupGroup
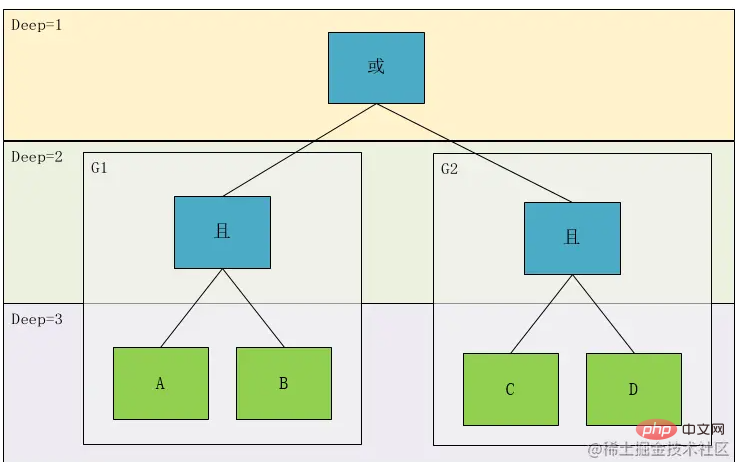
At this point, the prototype of this class is basically determined. This class contains Association relationship (Relation), Judgment field (Field), Operator (Operator), operation value (Values), Type(Type), Depth(Deep)
However, there is a problem. In the above analysis, we are converting the expression into a tree. Now we try to restore it, So we can get one of the expressions at a glance:
result=(A && B)||(C && D)
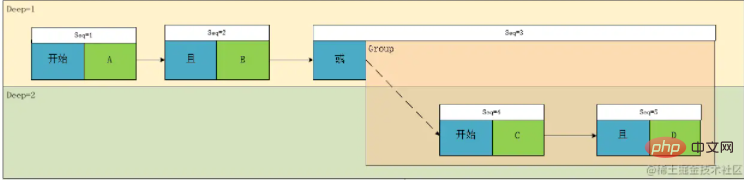
Obviously, it is not consistent with our original expression. This is because we can only record the calculation order of the expression above, but cannot completely accurately represent this expression. This is because in the process of parsing the expression In , there is not only depth, but also a timing relationship, that is, sequential expression from left to right. At this time, the content in G1 should actually have a depth of 1 instead of 2 in the original expression. Then we introduce the concept of sequence numbers. , turn the original tree into a directed graph:
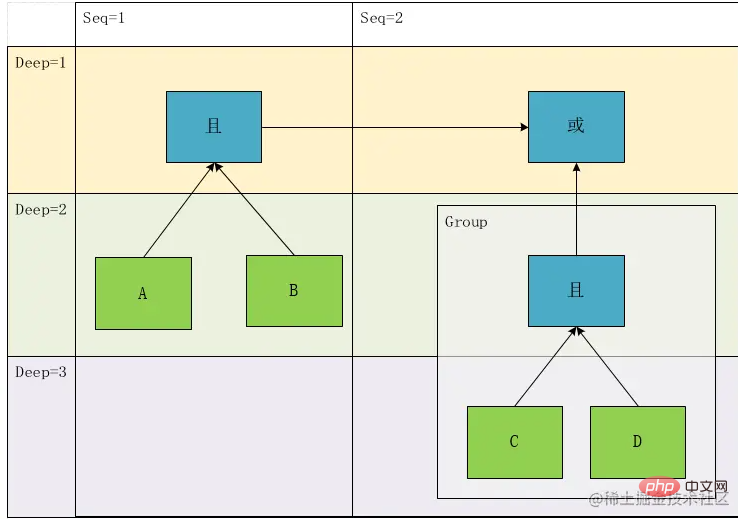
According to this graph, we can restore the only and only expression: result= A && B ||(C && D).
Okay, we have analyzed it for a long time, and now that we have finished explaining the principles, let’s go back to the original question: How to implement the front-end and back-end? Imagine looking at the picture above. It seems that it is still impossible to handle because the structure is still too complicated. For the front-end, the data should be easy to traverse, and for the back-end, the data should be easy to process, so at this time we need to convert the above picture into an array.
Implementation method
As mentioned above, we need an array structure. Let’s analyze this part in detail
We found that as a leaf node, can always be evaluated first, so we can condense it and place the relationship in one of the expressions to form ^A -> &&B or A&& -> B$ , here I use regular start(^) and end($) to express the concepts of start and end. In order to be consistent with the product prototype, we use the first method. That is, the relationship symbol represents the relationship with the previous element, so we analyze it again:
and then transform the sequence number:
So we get the final data structure:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}Now the data structure is finally completed, which is both convenient for storage and (relatively) convenient for front-end display. Now we construct a slightly more complex expression
A &&(( B || C )|| (D && E)) && F
Change to an array object, start with BEGIN, the expression type is represented by CONDITION, and the group is represented by GROUP express.
[
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]Now the last question is left: how to filter the data through this json
Since the essence of the array object is still an infix expression, its essence is still an infix Parsing of expressions. Regarding the parsing principle, I won’t introduce much here. Simply put, it traverses through the data stack and symbol stack according to the brackets (called groups in our case). If you want to know more, you can review it through the following article.
So we define three variables:
//关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;
By traversing the array, the relationship and the result are pushed into the stack. When it is found that priority calculation is needed, two values are taken from the result stack and the relationship is Take out the relational operator from the stack, push it into the stack again after calculation, and wait for the next calculation
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
}Let’s talk about the boundary matters to pay attention to:
1. First of all, the association relationship in our same level only exists and Or both, and the calculation priorities of the two are the same. Therefore, under the same Deep, just traverse and calculate from left to right.
2. When encountering the GROUP type, it is equivalent to encountering "(", we can find that the elements behind it are Deep 1 until Deep -1 and end with ")", and the elements in brackets need to take precedence. Calculation, that is to say, the priority generated by "()" is jointly controlled by Deep and Type=GROUP
3. When Deep decreases, it means that ")" is encountered, and the number of ended Groups is equal to The number reduced by Deep, for the end of ")", each time a ")" is encountered, the level of brackets needs to be checked to see whether the elements of the same level have been calculated.
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}4. When the traversal ends and it is found that the last element Deep is not equal to 1, it means that there is an end of parentheses. At this time, the end of parentheses also needs to be processed
Finally, the complete code:
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} I simply wrote a few test cases:
/**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}Test results:
Write at the end
At this point, one Expression parsing is complete, let’s go back and look at this picture again:
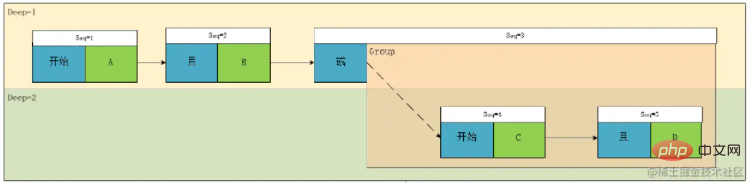
We can find that in fact, the function of Seq3 is only to identify the beginning of a group and record the association between the group and other elements of the same level. In fact, an optimization can be performed here: we find that whenever a group The pre-association relationship of the first node must be Begin, Deep 1. In fact, we can consider placing the Group's association on this node, and then only control the group's relationship through the increase or decrease of Deep. In this way, we This field of type expression or group is no longer needed, and the length of the array will be reduced as a result, but I personally think it will be a little more troublesome to understand. Here is a general idea of the transformation, and the code will not be released:
- Change the judgment about Type="GROUP" in the code to the difference of deep = 1
- Depth judgment push logic modification
- When storing relationship symbols, the depth corresponding to this relationship symbol must also be stored.
- When processing legacy elements with the same depth, that is:
computeBeforeEndGroup( )In the method, the original method is to use the Begin element to distinguish whether the Group has been processed. Now it needs to be changed to determine whether the depth of the next symbol is the same as the current depth, and delete the pop-up logic of the BEGIN element
Recommended study: "java video tutorial"
The above is the detailed content of Example introduction to implement a complex relational expression filter based on Java. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
