
 Web Front-end
JS Tutorial
The basic concepts of asynchronous and callback in JavaScript and the phenomenon of callback hell
Web Front-end
JS Tutorial
The basic concepts of asynchronous and callback in JavaScript and the phenomenon of callback hell
The basic concepts of asynchronous and callback in JavaScript and the phenomenon of callback hell

This article brings you relevant knowledge about javascript. It mainly introduces the basic concepts of asynchronous and callbacks in JavaScript, as well as the phenomenon of callback hell. This article mainly introduces the basic concepts of asynchronous and callbacks. , the two are the core content of JavaScript. Let’s take a look at them together. I hope it will be helpful to everyone.

[Related recommendations: javascript video tutorial, web front-end】
JavaScript asynchronous and callback
1. Foreword
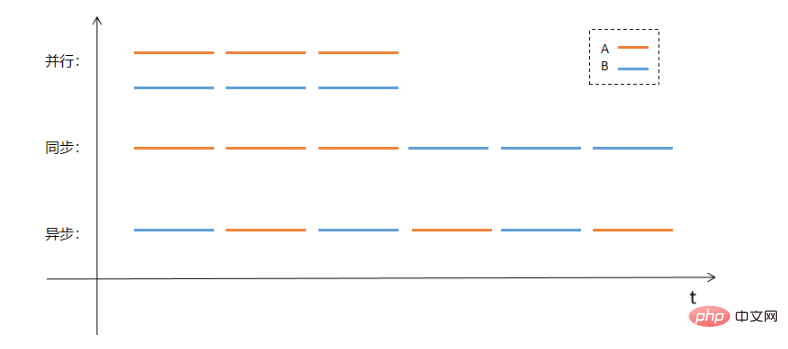
Before studying the content of this article, we must first understand the concept of asynchronous. The first thing to emphasize is that there is an essential difference between asynchronous and parallel.
- Parallel, generally refers to parallel computing, which means that multiple instructions are executed at the same time. These instructions may be executed on multiple cores of the same
CPU, or multipleCPU, or multiple physical hosts or even multiple networks. - Synchronization generally refers to executing tasks in a predetermined order. Only when the previous task is completed, the next task will be executed.
- Asynchronous, corresponding to synchronization, asynchronous means to let
CPUtemporarily put aside the current task, process the next task first, and then return to the previous task after receiving the callback notification of the previous task. The task continues to execute, No need for a second thread to participate in the entire process.
Perhaps it is more intuitive to use pictures to explain parallelism, synchronization and asynchronousness. Assume that there are two tasks A and B that need to be processed. The parallel, synchronous and asynchronous processing methods will be as follows: The execution method shown:
2. Asynchronous functions
JavaScript provides us with many asynchronous functions Functions, these functions allow us to conveniently execute asynchronous tasks, that is, we start to execute a task (function) now, but the task will be completed later, and the specific completion time is not clear.
For example, the setTimeout function is a very typical asynchronous function. In addition, fs.readFile and fs.writeFile are also asynchronous functions.
We can define an asynchronous task case ourselves, such as customizing a file copy function copyFile(from,to):
const fs = require('fs')
function copyFile(from, to) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
})
})
}FunctioncopyFileFirst read the file data from the parameter from, and then write the data to the file pointed to by the parameter to.
We can call copyFile like this:
copyFile('./from.txt','./to.txt')//复制文件
If at this time, there are other codes behind copyFile(...), then the program It does not wait for the execution of copyFile to end, but executes it directly. The program does not care when the file copy task ends.
copyFile('./from.txt','./to.txt') //下面的代码不会等待上面的代码执行结束 ...
After executing this point, everything seems to be normal, but if we directly access the file ./to.txt after the copyFile(...) function What happens to the content in ?
This will not read the copied content, just like this:
copyFile('./from.txt','./to.txt')
fs.readFile('./to.txt',(err,data)=>{
...
})If the ./to.txt file has not been created before executing the program, it will Got the following error:
PS E:\Code\Node\demos\03-callback> node .\index.js
finished
Copy finished
PS E:\Code \Node\demos\03-callback> node .\index.js
Error: ENOENT: no such file or directory, open 'E:\Code\Node\demos\03-callback\to.txt'
Copy finished
Even if ./to.txt exists, the copied content cannot be read.
The reason for this phenomenon is: copyFile(...) is executed asynchronously. After the program executes the copyFile(...) function, and It does not wait for the copy to be completed, but executes it directly, resulting in an error that the file ./to.txt does not exist, or an error that the file content is empty (if the file is created in advance).
3. Callback function
The specific execution end time of the asynchronous function cannot be determined, for example, the readFile(from,to) function The execution end time most likely depends on the size of the file from.
So, the question is how can we accurately locate the end of copyFile execution and read the contents of the to file?
This requires the use of a callback function. We can modify the copyFile function as follows:
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
callback()//当复制操作完成后调用回调函数
})
})
}In this way, if we need to perform some operations immediately after the file copy is completed, just You can write these operations into the callback function:
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
callback()//当复制操作完成后调用回调函数
})
})
}
copyFile('./from.txt', './to.txt', function () {
//传入一个回调函数,读取“to.txt”文件中的内容并输出
fs.readFile('./to.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log(data.toString())
})
})If you have prepared the ./from.txt file, then the above code can be run directly:
PS E:\Code\Node\demos\03-callback> node .\index.js
Copy finished
加入社区“仙宗”,和我一起修仙吧
社区地址:http://t.csdn.cn/EKf1h
这种编程方式被称为“基于回调”的异步编程风格,异步执行的函数应当提供一个回调参数用于在任务结束后调用。
这种风格在JavaScript编程中普遍存在,例如文件读取函数fs.readFile、fs.writeFile都是异步函数。
四、回调的回调
回调函数可以准确的在异步工作完成后处理后继事宜,如果我们需要依次执行多个异步操作,就需要嵌套回调函数。
案例场景:依次读取文件A和文件B
代码实现:
fs.readFile('./A.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log('读取文件A:' + data.toString())
fs.readFile('./B.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log("读取文件B:" + data.toString())
})
})执行效果:
PS E:\Code\Node\demos\03-callback> node .\index.js
读取文件A:仙宗无限好,只是缺了佬读取文件B:要想入仙宗,链接不能少
http://t.csdn.cn/H1faI
通过回调的方式,就可以在读取文件A之后,紧接着读取文件B。
如果我们还想在文件B之后,继续读取文件C呢?这就需要继续嵌套回调:
fs.readFile('./A.txt', (err, data) => {//第一次回调
if (err) {
console.log(err.message)
return
}
console.log('读取文件A:' + data.toString())
fs.readFile('./B.txt', (err, data) => {//第二次回调
if (err) {
console.log(err.message)
return
}
console.log("读取文件B:" + data.toString())
fs.readFile('./C.txt',(err,data)=>{//第三次回调
...
})
})
})也就是说,如果我们想要依次执行多个异步操作,需要多层嵌套回调,这在层数较少时是行之有效的,但是当嵌套次数过多时,会出现一些问题。
回调的约定
实际上,fs.readFile中的回调函数的样式并非个例,而是JavaScript中的普遍约定。我们日后会自定义大量的回调函数,也需要遵守这种约定,形成良好的编码习惯。
约定是:
callback的第一个参数是为 error 而保留的。一旦出现 error,callback(err)就会被调用。- 第二个以及后面的参数用于接收异步操作的成功结果。此时
callback(null, result1, result2,...)就会被调用。
基于以上约定,一个回调函数拥有错误处理和结果接收两个功能,例如fs.readFile('...',(err,data)=>{})的回调函数就遵循了这种约定。
五、回调地狱
如果我们不深究的话,基于回调的异步方法处理似乎是相当完美的处理方式。问题在于,如果我们有一个接一个 的异步行为,那么代码就会变成这样:
fs.readFile('./a.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./b.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./c.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//读取结果操作
fs.readFile('./d.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
...
})
})
})
})以上代码的执行内容是:
- 读取文件a.txt,如果没有发生错误的话;
- 读取文件b.txt,如果没有发生错误的话;
- 读取文件c.txt,如果没有发生错误的话;
- 读取文件d.txt,…
随着调用的增加,代码嵌套层级越来越深,包含越来越多的条件语句,从而形成不断向右缩进的混乱代码,难以阅读和维护。
我们称这种不断向右增长(向右缩进)的现象为“回调地狱”或者“末日金字塔”!
fs.readFile('a.txt',(err,data)=>{
fs.readFile('b.txt',(err,data)=>{
fs.readFile('c.txt',(err,data)=>{
fs.readFile('d.txt',(err,data)=>{
fs.readFile('e.txt',(err,data)=>{
fs.readFile('f.txt',(err,data)=>{
fs.readFile('g.txt',(err,data)=>{
fs.readFile('h.txt',(err,data)=>{
...
/*
通往地狱的大门
===>
*/
})
})
})
})
})
})
})
})虽然以上代码看起来相当规整,但是这只是用于举例的理想场面,通常业务逻辑中会有大量的条件语句、数据处理操作等代码,从而打乱当前美好的秩序,让代码变的难以维护。
幸运的是,JavaScript为我们提供了多种解决途径,Promise就是其中的最优解。
【相关推荐:javascript视频教程、web前端】
The above is the detailed content of The basic concepts of asynchronous and callback in JavaScript and the phenomenon of callback hell. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to use WebSocket and JavaScript to implement an online speech recognition system Introduction: With the continuous development of technology, speech recognition technology has become an important part of the field of artificial intelligence. The online speech recognition system based on WebSocket and JavaScript has the characteristics of low latency, real-time and cross-platform, and has become a widely used solution. This article will introduce how to use WebSocket and JavaScript to implement an online speech recognition system.
 WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: Key technologies for realizing real-time monitoring systems Introduction: With the rapid development of Internet technology, real-time monitoring systems have been widely used in various fields. One of the key technologies to achieve real-time monitoring is the combination of WebSocket and JavaScript. This article will introduce the application of WebSocket and JavaScript in real-time monitoring systems, give code examples, and explain their implementation principles in detail. 1. WebSocket technology
 How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
Introduction to how to use JavaScript and WebSocket to implement a real-time online ordering system: With the popularity of the Internet and the advancement of technology, more and more restaurants have begun to provide online ordering services. In order to implement a real-time online ordering system, we can use JavaScript and WebSocket technology. WebSocket is a full-duplex communication protocol based on the TCP protocol, which can realize real-time two-way communication between the client and the server. In the real-time online ordering system, when the user selects dishes and places an order
 How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to use WebSocket and JavaScript to implement an online reservation system. In today's digital era, more and more businesses and services need to provide online reservation functions. It is crucial to implement an efficient and real-time online reservation system. This article will introduce how to use WebSocket and JavaScript to implement an online reservation system, and provide specific code examples. 1. What is WebSocket? WebSocket is a full-duplex method on a single TCP connection.
 JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecast system Introduction: Today, the accuracy of weather forecasts is of great significance to daily life and decision-making. As technology develops, we can provide more accurate and reliable weather forecasts by obtaining weather data in real time. In this article, we will learn how to use JavaScript and WebSocket technology to build an efficient real-time weather forecast system. This article will demonstrate the implementation process through specific code examples. We
 Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
JavaScript tutorial: How to get HTTP status code, specific code examples are required. Preface: In web development, data interaction with the server is often involved. When communicating with the server, we often need to obtain the returned HTTP status code to determine whether the operation is successful, and perform corresponding processing based on different status codes. This article will teach you how to use JavaScript to obtain HTTP status codes and provide some practical code examples. Using XMLHttpRequest
 How to use insertBefore in javascript
Nov 24, 2023 am 11:56 AM
How to use insertBefore in javascript
Nov 24, 2023 am 11:56 AM
Usage: In JavaScript, the insertBefore() method is used to insert a new node in the DOM tree. This method requires two parameters: the new node to be inserted and the reference node (that is, the node where the new node will be inserted).
 JavaScript and WebSocket: Building an efficient real-time image processing system
Dec 17, 2023 am 08:41 AM
JavaScript and WebSocket: Building an efficient real-time image processing system
Dec 17, 2023 am 08:41 AM
JavaScript is a programming language widely used in web development, while WebSocket is a network protocol used for real-time communication. Combining the powerful functions of the two, we can create an efficient real-time image processing system. This article will introduce how to implement this system using JavaScript and WebSocket, and provide specific code examples. First, we need to clarify the requirements and goals of the real-time image processing system. Suppose we have a camera device that can collect real-time image data
