


Recommended learning: mysql video tutorial
REDO LOG is called a redo log. After the MySQL server unexpectedly crashes or goes down, it is guaranteed that submitted transactions are persisted to the disk (persistence).
InnoDB operates records in units of pages. Additions, deletions, modifications and queries will load the entire page into the buffer pool (disk -> memory). The modification operation in the transaction does not directly modify the data in the disk. Instead, the data in the buffer pool in memory is modified first, and the background thread asynchronously refreshes it to the disk every once in a while.
Buffer pool: It can store indexes and data, accelerate reading and writing, directly operate data pages in memory, and has a dedicated thread to write dirty pages in the buffer pool to disk.
Why not directly modify the data on the disk?
Because if you directly modify the disk data, it is random IO. The modified data is distributed in different locations on the disk and needs to be searched back and forth. Therefore, the hit rate is low and the consumption is high. Moreover, a small modification cannot The entire page is not refreshed to the disk, and the utilization rate is low;
In contrast, sequential IO, the disk data is distributed in one part of the disk, so the search process is omitted and the seek time is saved.
Using background threads to refresh the disk at a certain frequency can reduce the frequency of random IO and increase throughput. This is the fundamental reason for using the buffer pool.
The problem of modifying the memory and then asynchronously synchronizing it to the disk:
Because the buffer pool is an area in the memory, the data may be lost if the system crashes unexpectedly, and some dirty data may not be refreshed in time. Disk, transaction durability is not guaranteed. Therefore, redo log was introduced. When modifying data, an additional log is recorded, which shows that the xx offset of page xx has changed by xx. When the system crashes, it can be recovered based on the log content.
The difference between writing logs and directly refreshing the disk is: writing logs is append writing, sequential IO, faster, and the written content is relatively smaller
The redo log is composed of two parts :
The general process of the modification operation:
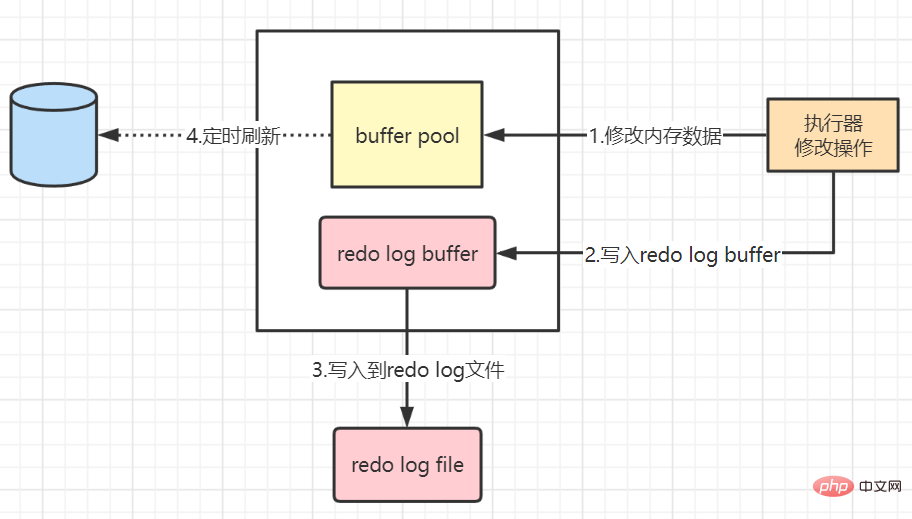
Step 1: First read the original data from the disk into the memory, modify the memory copy of the data, and generate dirty data
Step 2: Generate a redo log and write it into the redo log buffer. What is recorded is the modified value of the data.
Step 3: By default, after the transaction is committed, the redo log buffer will be The content is refreshed to the redo log file, and the redo log file is appended.
Step 4: Regularly refresh the modified data in the memory to the disk (here we are talking about those data that have not been refreshed by the background thread in time Dirty data on the disk)
The so-called Write-Ahead Log (pre-log persistence) refers to persisting the corresponding log page in the memory before persisting a data page.
Benefits of redo log:
Can redo log guarantee the durability of transactions?
Not necessarily, this depends on the redo log flushing strategy, because the redo log buffer is also in memory. If the transaction is submitted, the redo log buffer has not had time to refresh the data to the redo log file for persistence. ization, if a downtime occurs at this time, data will still be lost. How to solve? Sweep strategy.
InnoDB provides three strategies for the innodb_flush_log_at_trx_commit parameter to control when the redo log buffer is flushed to the redo log file:
The value is 0:
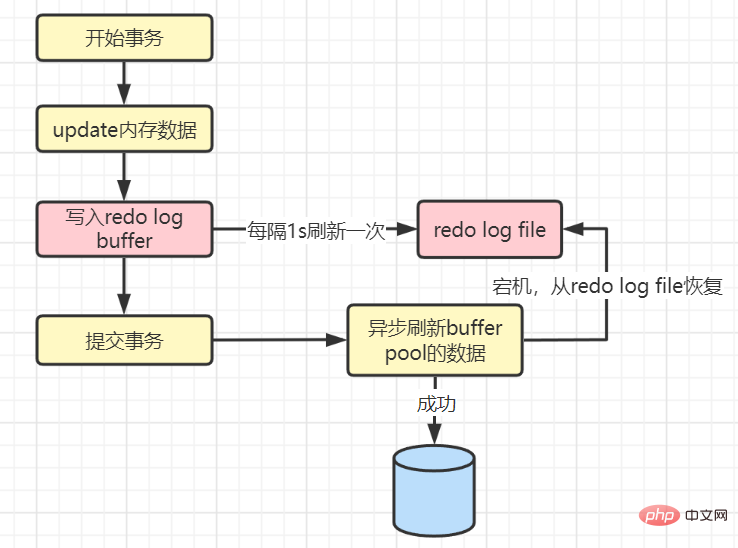
Because there is an interval of 1s, 1 second of data will be lost in the worst case.
When the value is 1:
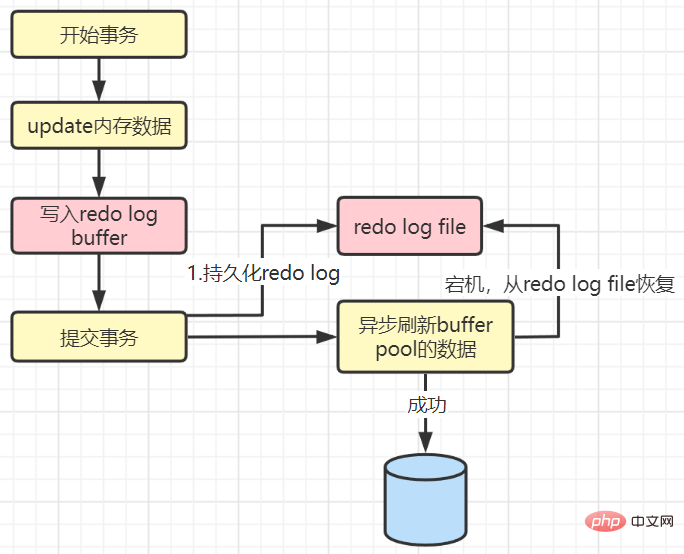
When committing, you need to actively refresh the redo log buffer to the redo log file. If it crashes in the middle, the transaction will fail without any loss, and the durability of the transaction can be truly guaranteed. But the efficiency is the worst.
If the value is 2: it is determined based on the os.
Can be adjusted to 0 or 2 to improve transaction performance, but the ACID feature is lost
undo log is used to ensure the atomicity and consistency of transactions. It has two functions: ① Provide rollback operation ② Multi-version control MVVC
Rollback operation
As mentioned in the redo log earlier, the background thread will refresh the data in the buffer pool from time to time. to the disk, but if various errors (downtime) occur during the execution of the transaction or a rollback statement is executed, then the previously brushed operations need to be rolled back to ensure atomicity. The undo log provides transaction rollback.
MVVC
When a read row is locked by other transactions, it can analyze the previous data version of the row record from the undo log, so that users can read it To the data before the current transaction operation - snapshot read.
Snapshot reading: The data read by SQL is the historical version, no locking is required, ordinary SELECT is snapshot reading.
Components of undo log:
The select operation will not generate undo log
In the InnoDB storage engine, undo log uses rollback segment rollback segment for storage , every rollback segment contains 1024 undo log segments. After MySQL5.5, there are a total of 128 rollback segments. That is, a total of 128 * 1024 undo operations can be recorded.
Each transaction will only use one rollback segment, and one rollback segment may serve multiple transactions at the same time.
The undo log cannot be deleted immediately after the transaction is submitted. Some transactions may want to read the previous data version (snapshot read). Therefore, when a transaction is committed, the undo log is put into a linked list, called a version chain. Whether the undo log is deleted or not is judged by a thread called purge.
undo log is divided into:
insert undo log
Because the record of insert operation is only visible to the transaction itself, not to other transactions It can be seen (this is a requirement of transaction isolation), so the undo log can be deleted directly after the transaction is committed. No purge operation is required.
update undo log
update undo log records the undo log generated by delete and update operations. The undo log may need to provide an MVCC mechanism, so it cannot be deleted when the transaction is committed. When submitting, put it into the undo log list and wait for the purge thread to perform the final deletion.
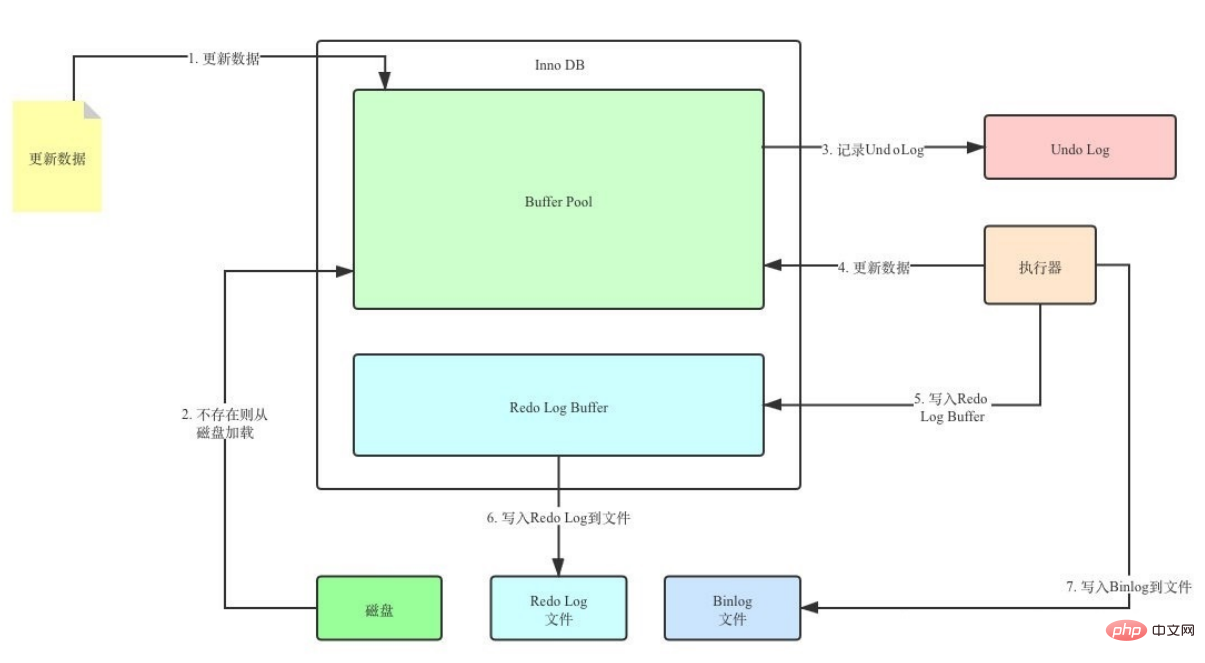
Suppose there are 2 values, A=1 and B=2, and then a transaction modifies A to 3 and B to 4. The modification process Can be simplified to:
1.begin
2. Record A=1 to undo log
3.update A=3
4. Record A=3 to redo log
5. Record B=2 to undo log
6.update B=4
7. Record B=4 to redo log
8. Refresh redo log to disk
9.commit
For the InnoDB engine, in addition to the data of the record itself, each row record also has several hidden Column:

When we execute INSERT:
begin; INSERT INTO user (name) VALUES ('tom');
插入的数据都会生成一条insert undo log,并且数据的回滚指针会指向它。undo log会记录undo log的序号、插入主键的列和值...,那么在进行rollback的时候,通过主键直接把对应的数据删除即可。
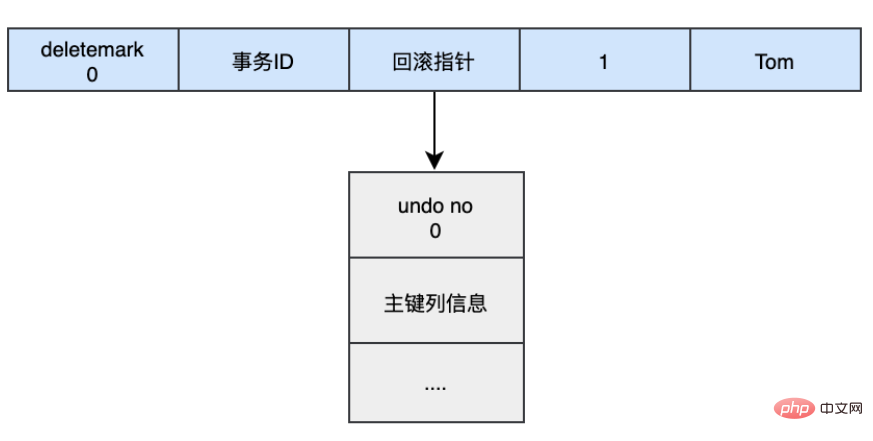
当我们执行UPDATE时:
对于更新的操作会产生update undo log,并且会分更新主键的和不更新主键的,假设现在执行:
UPDATE user SET name='Sun' WHERE id=1;
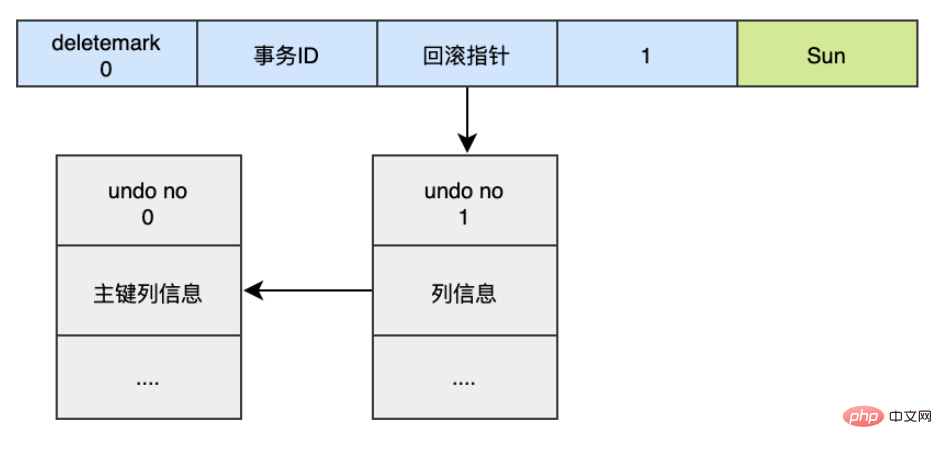
这时会把新的undo log记录加入到版本链中,它的undo no是1,并且新的undo log的回滚指针会指向老的undo log (undo no=0)。
假设现在执行:
UPDATE user SET id=2 WHERE id=1;
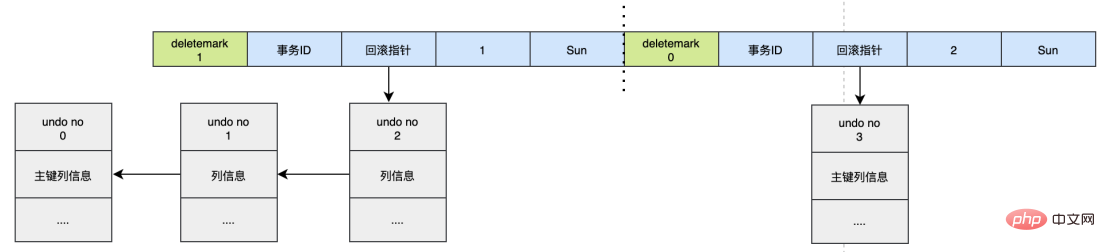
对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undo log,并且undo log的序号会递增。
可以发现每次对数据的变更都会产生一个undo log,当一条记录被变更多次时,那么就会产生多条undo log,undo log记录的是变更前的日志,并且每个undo log的序号是递增的,那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了。
以上面的例子来说,假设执行rollback,那么对应的流程应该是这样:
1. 通过undo no=3的日志把id=2的数据删除
2. 通过undo no=2的日志把id=1的数据的deletemark还原成0
3. 通过undo no=1的日志把id=1的数据的name还原成Tom
4. 通过undo no=0的日志把id=1的数据删除
MySQL MVVC多版本并发控制
binlog即binary log,二进制日志文件,也叫作变更日志(update log)。它记录了数据库所有执行的更新语句。
binlog主要应用场景:
show variables like '%log_bin%';
查看bin log日志:
mysqlbinlog -v "/var/lib/mysql/binlog/xxx.000002"
使用日志恢复数据:
mysqlbinlog [option] filename|mysql –uuser -ppass;
删除二进制日志:
PURGE {MASTER | BINARY} LOGS TO ‘指定日志文件名'
PURGE {MASTER | BINARY} LOGS BEFORE ‘指定日期'事务执行过程中,先把日志写到bin log cache ,事务提交的时候,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为binlog cache。
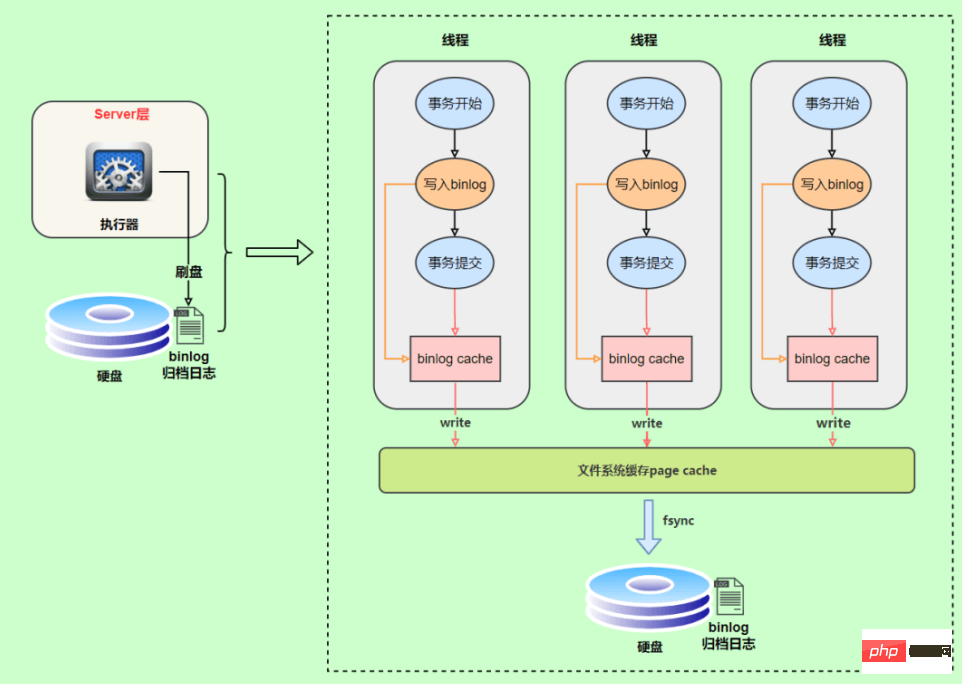
两个侧重点也不同, redo log让InnoDB有了崩溃恢复的能力,binlog保证了MySQL集群架构的数据一致性。
在执行更新语句过程,会记录redo log与binlog两块日志,以基本的事务为单位,redo log在事务执行过程中可以不断写入,而binlog只有在提交事务时才写入,所以redo log与binlog的写入时机不一样。
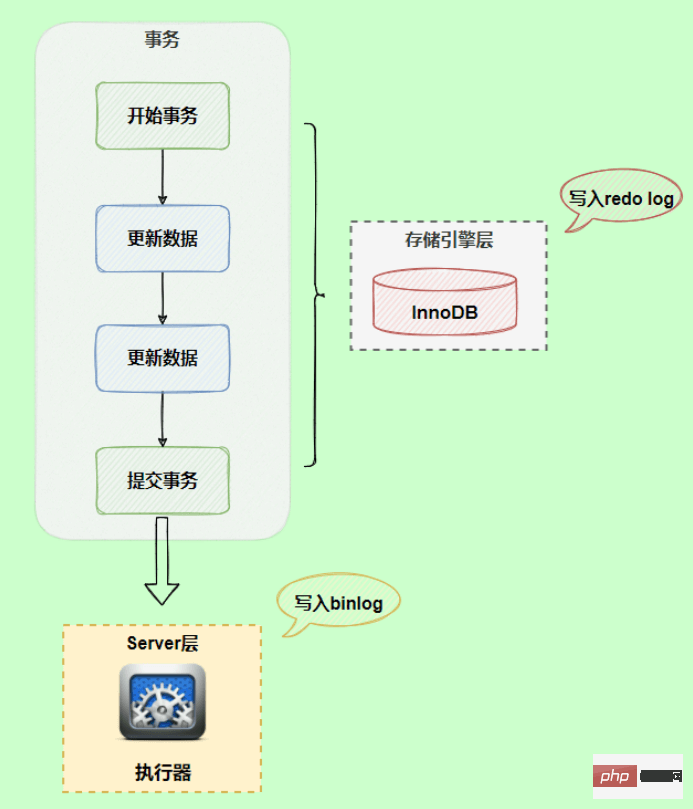
redo log与binlog两份日志之间的逻辑不一致,会出现什么问题?
以update语句为例,假设id=2的记录,字段c值是0,把字段c值更新成1,SQL语句为update T set c=1 where id=2。
假设执行过程中写完redo log日志后,binlog日志写期间发生了异常,会出现什么情况呢?
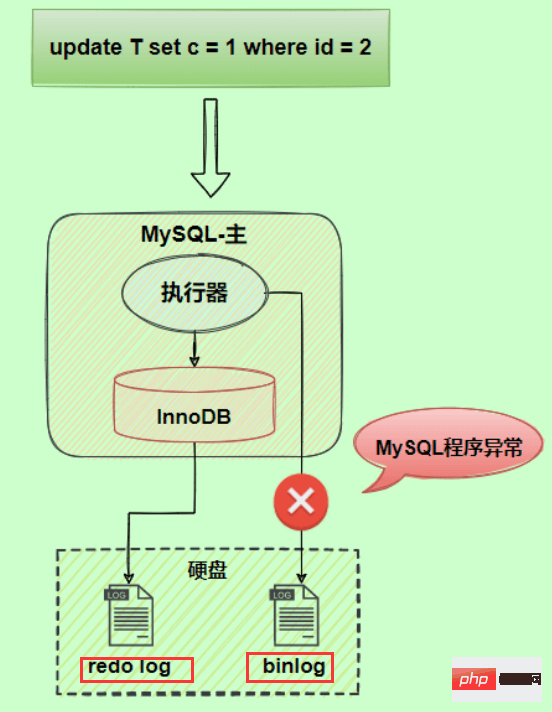
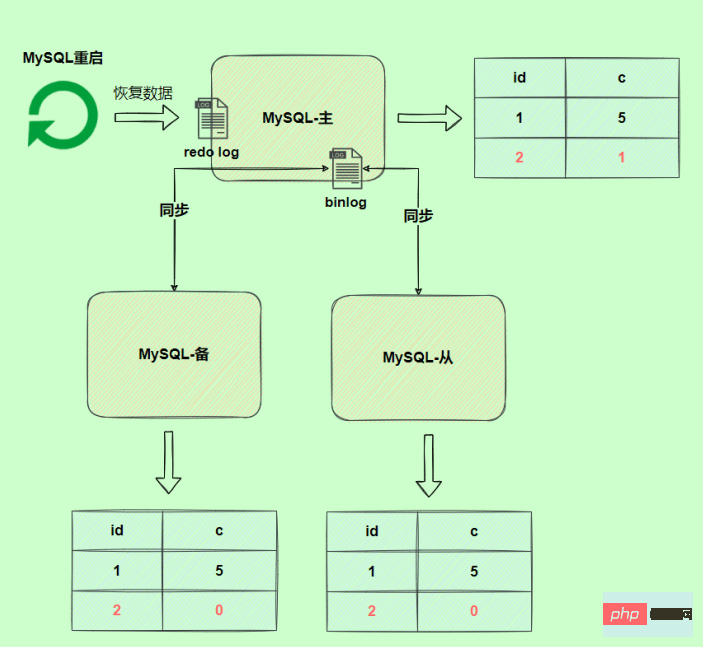
由于binlog没写完就异常,这时候binlog里面没有对应的修改记录。因此,之后用binlog日志恢复数据或者slave读取master的binlog时,就会少这一次更新,恢复出来的这一行c值是0,而原库因为redo log日志恢复,这一行c值是1,最终数据不一致。
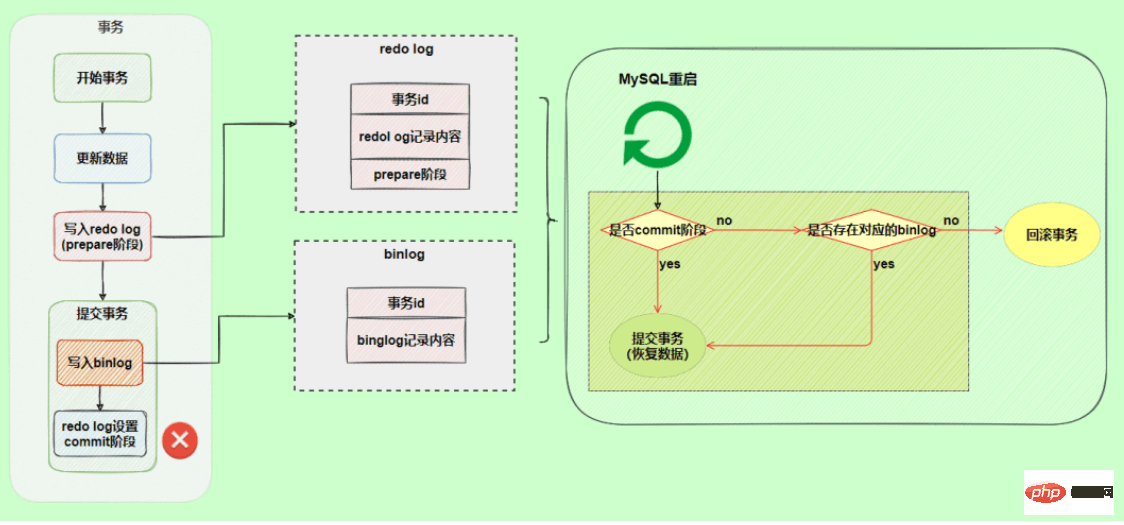
In order to solve the logical consistency problem between the two logs, the InnoDB storage engine uses a two-phase commit scheme. Split the redo log into two steps, prepare and commit, which is a two-stage commit.
Let the final commits of redo log and bin log be bound together. As mentioned before, when a transaction is committed, by default, the redo log needs to be synchronized before the commit is successful, so if they are bound together, bin Log also has this feature, which ensures that data will not be lost.
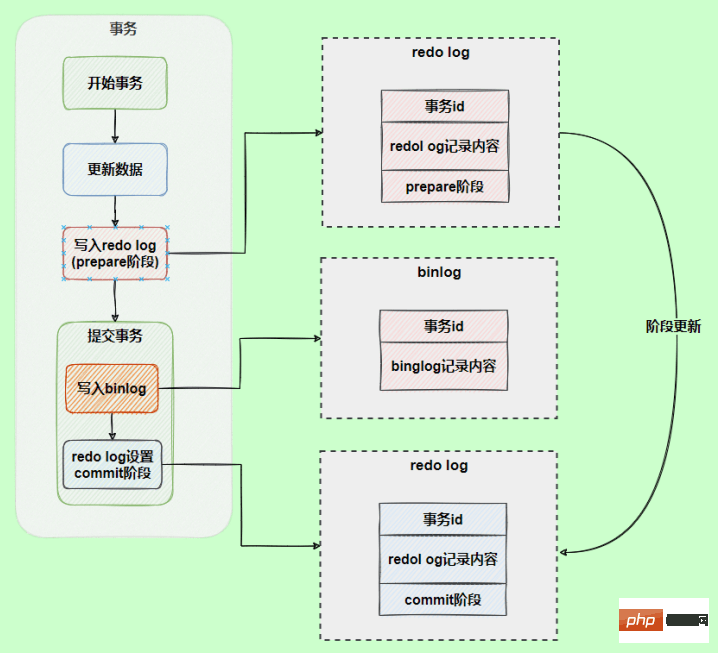
After using two-phase commit, there will be no impact if an exception occurs when writing the binlog, because when MySQL restores data based on the redo log log, it finds that the redo log is still in the prepare stage. And if there is no corresponding binlog log, the submission will fail and the data will be rolled back.
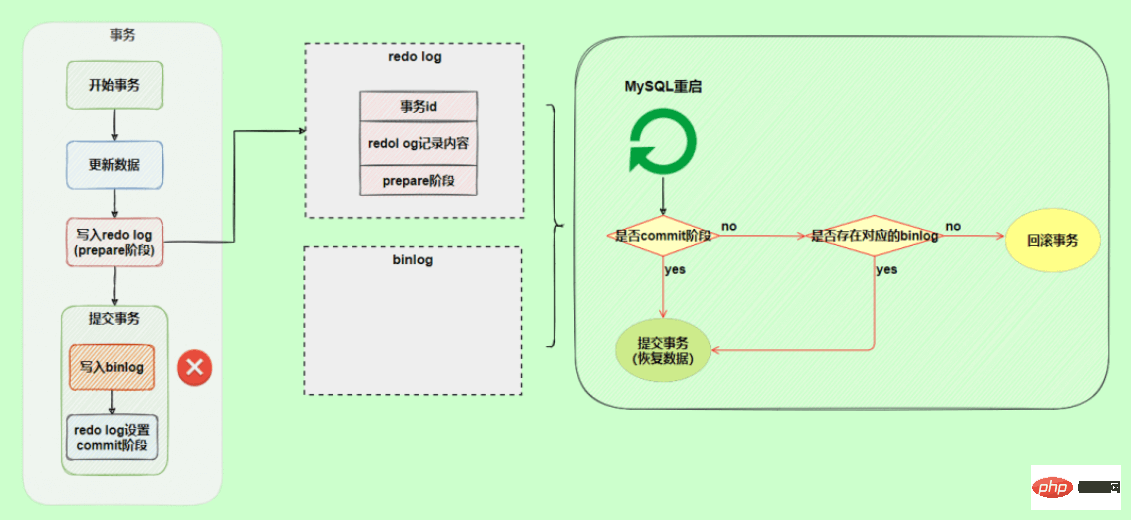
In another scenario, an exception occurs during the commit phase of the redo log. Will the transaction be rolled back?
will not roll back the transaction, it will execute the logic framed in the above figure. Although the redo log is in the prepare stage, the corresponding binlog log can be found through the transaction ID. , so MySQL thinks it is complete and will submit the transaction to restore the data.
Recommended learning: mysql video tutorial
The above is the detailed content of Special arrangement of MySQL logs: redo log and undo log. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



