

How to view execution plan in Mysql


Recommended learning: mysql video tutorial
Use the explain keyword to simulate the optimizer executing SQL query statements, so as to know that MySQL is How to handle your SQL statements and analyze the performance bottlenecks of your query statements or table structures.
Explain the information contained in the execution plan
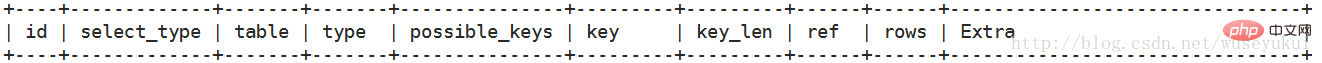
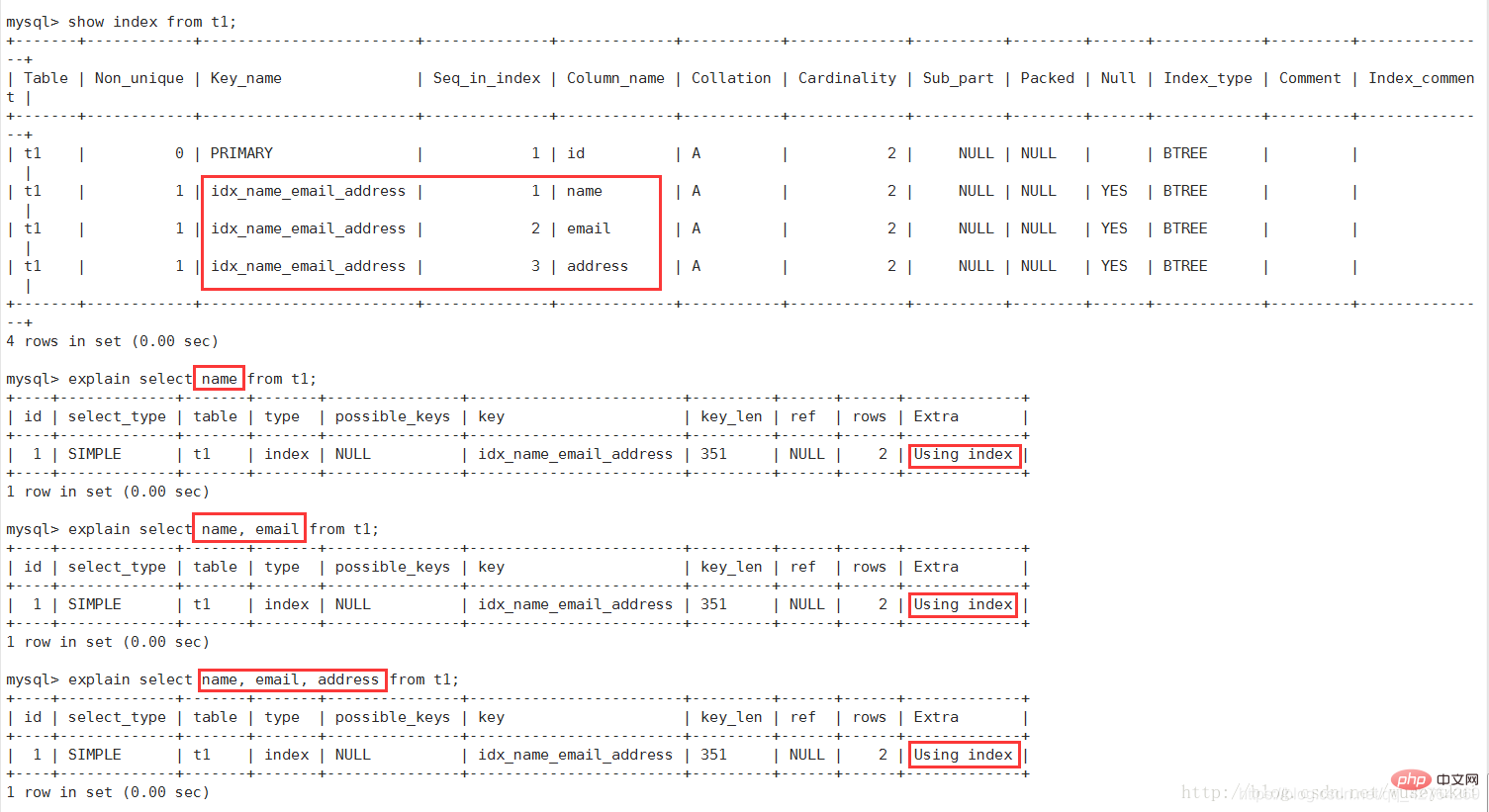
#The most important fields are: id, type, key, rows, Extra
each Detailed field explanation
id
Select query sequence number, including a set of numbers, indicating the order in which select clauses or operation tables are executed in the query
Three situations:
1. Same id: execution order from top to bottom

2. Different id: if it is a child For queries, the serial number of the id will increase. The larger the id value, the higher the priority and the earlier it will be executed

3. The id is the same but different (both cases are at the same time Exists) : If the id is the same, it can be considered as a group and executed sequentially from top to bottom; among all groups, the larger the id value, the higher the priority, and the earlier it is executed

select_type
The type of query is mainly used to distinguish complex queries such as ordinary queries, joint queries, subqueries, etc.
- 1, SIMPLE: Simple select query, the query does not contain subqueries or unions
- 2. PRIMARY: The query contains any complex subparts, and the outermost query is marked as primary
- 3. SUBQUERY: A subquery is included in the select or where list.
- 4. DERIVED: A subquery is included in the from list. Marked as derived, MySQL or recursively executes these subqueries and puts the results in the zero time table
- 5, UNION: If the second select appears after union, is marked as union; if union is included in the subquery of the from clause, the outer select will be marked as derived
- 6, UNION RESULT: Select to obtain results from the union table

type
Access type, a very important indicator in SQL query optimization, the result values from best to worst are:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
Generally speaking, a good sql query reaches at least the range level, and preferably reaches the ref
##1. system: The table has only one row of records (equal to System table), this is a special case of the const type, which does not usually appear and can be ignored
2. const: means it is found through the index once, const is used to compare the primary key or unique index. Because you only need to match one row of data, it's very fast. If the primary key is placed in the where list, mysql can convert the query into a const

: unique index scan, for For each index key, only one record in the table matches it. Commonly seen in primary key or unique index scans.
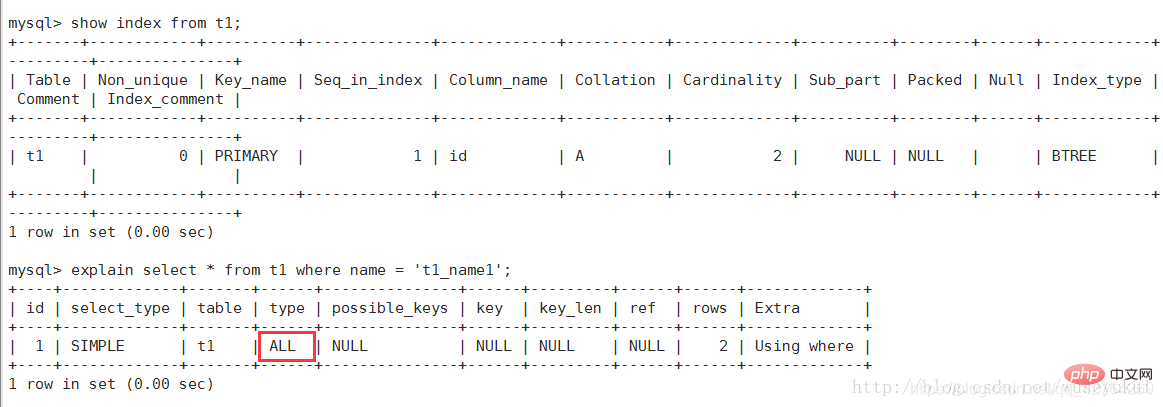
 Note: ALL full table scan of the table with the fewest records, such as the t1 table
Note: ALL full table scan of the table with the fewest records, such as the t1 table
: non-unique index Scan to return all rows matching a single value. Essentially, it is also an index access, which returns all rows that match a single value. However, it may find multiple rows that meet the criteria, so it should be a mixture of search and scan
5, range: Retrieve only rows in a given range, using an index to select rows. The key column shows which index is used. Generally, queries such as bettween, , in, etc. appear in the where statement. This range scan on index columns is better than a full index scan. It only needs to start at a certain point and end at another point, without scanning the entire index

6, index: Full Index Scan, index and ALL The difference is that the index type only traverses the index tree. This is usually ALL blocks, as index files are usually smaller than data files. (Although Index and ALL both read the entire table, index is read from the index, while ALL is read from the hard disk)

7, ALL: Full Table Scan, traverse the entire table to find matching rows
possible_keys
There is an index on the fields involved in the query, then the index will Listed, but not necessarily used by the query
key
The index actually used, if NULL, no index is used.
If a covering index is used in the query, the index will only appear in the key list
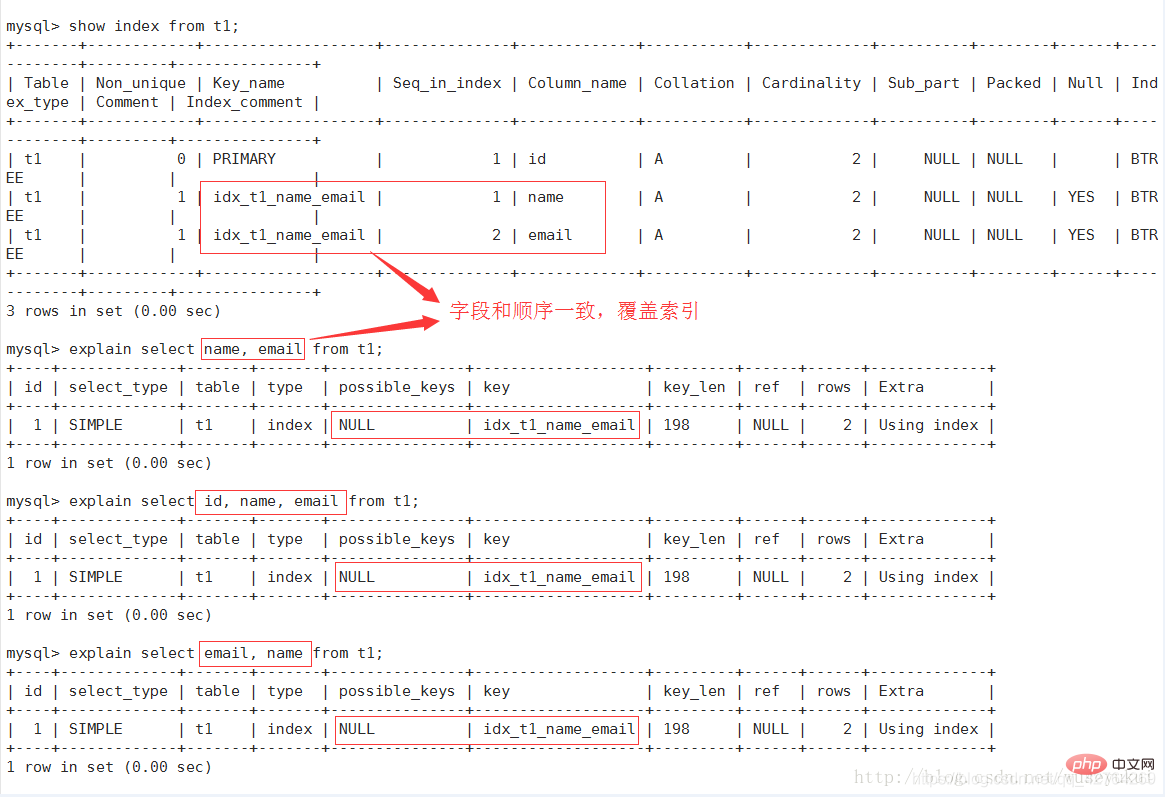

key_len
indicates the number of bytes used in the index and the length of the index used in the query (the maximum possible length), not the actual length used. In theory, the shorter the length, the better. key_len is calculated based on the table definition, not retrieved from the table.
ref
The column showing the index is used. If possible, it is a constant const.
rows
Based on table statistics and index selection, roughly estimate the number of rows that need to be read to find the required records
Extra
Not suitable for display in other fields, but very important additional information
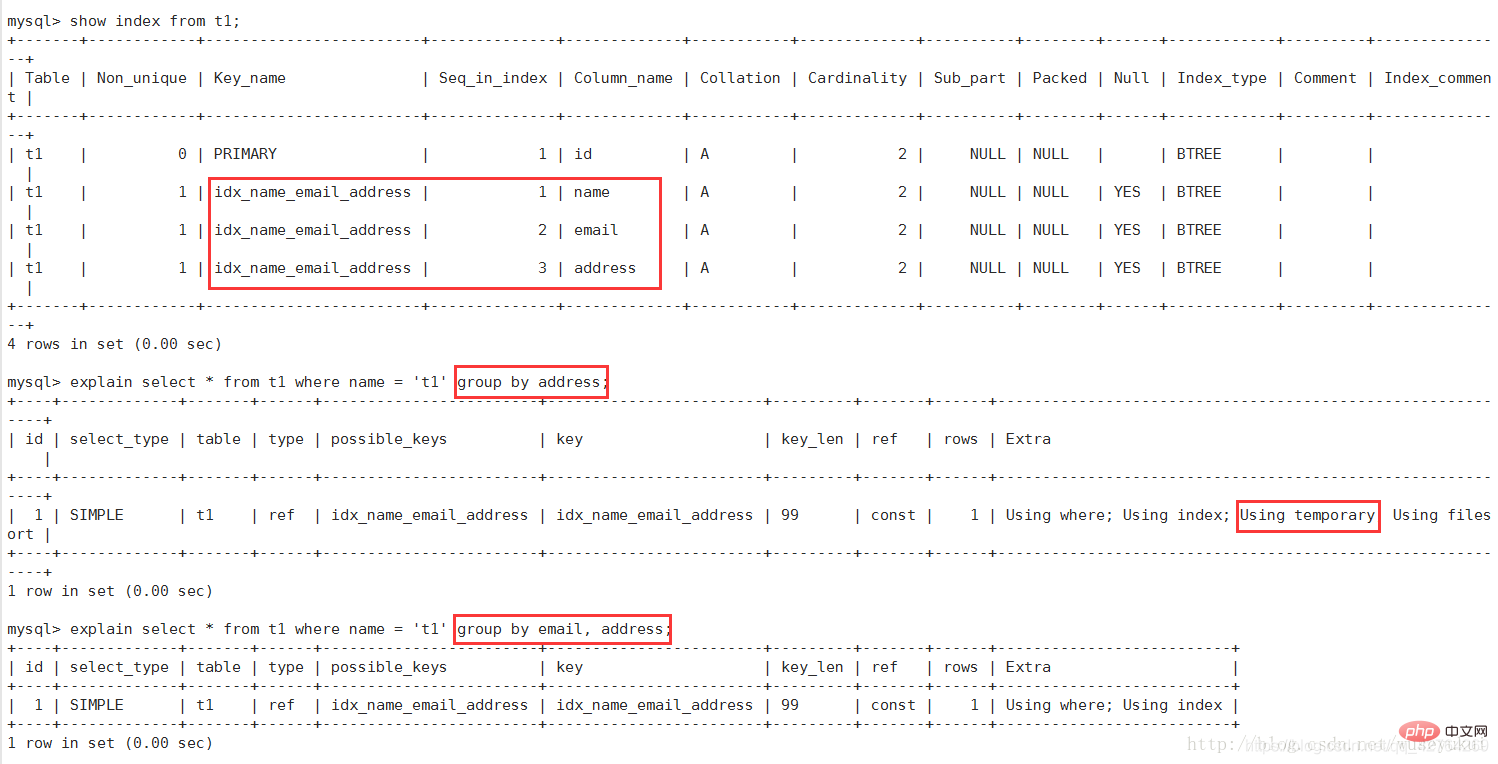
1. Using filesort:
mysql uses an external index to sort the data, rather than sorting by The index within the table performs sorted reads. That is to say, mysql cannot use the index to complete the sorting operation to become "file sorting"

Since the index is sorted by email first and then by address, if you query directly by Address sorting, the index cannot meet the requirements, and mysql must implement "file sorting" again
2. Using temporary:
Use temporary tables to save intermediate results. That is to say, mysql uses temporary tables when sorting query results, which is common in order by and group by
3. Using index:
Indicates that Covering Index (Covering Index) is used in the corresponding select operation, which avoids accessing the data rows of the table and is highly efficient.
If Using where appears at the same time, it indicates that the index has been Used to perform search of index key values (refer to the picture above)
If it is not used and "Using where" appears at the same time, it indicates that the index is used to read data rather than perform search actions
Covering Index (Covering Index): Also called index coverage. It is the fields in the select list that can be obtained only from the index. There is no need to read the data file again according to the index. In other words, the query column must be covered by the built index .
Note:
- a. If you need to use a covering index, only take out the required columns from the fields in the select list. Do not use select *
- b. If you use Indexing all fields will cause the index file to be too large, which will reduce crud performance
4. Using where:
Using where filtering
5. Using join buffer:
Using link cache
6. Impossible WHERE:
where clause The value is always false and cannot be used to obtain any ancestor

7. Select tables optimized away:
without group by In the case of clauses, optimizing the MIN/MAX operation based on the index or optimizing the COUNT(*) operation for the MyISAM storage engine does not have to wait until the execution phase to perform calculations. The optimization can be completed during the query execution plan generation phase
8. distinct:
Optimize distinct operation, stop looking for equally worthy actions after finding the first matching ancestor
Comprehensive Case

Execution sequence
1 (id = 4), [select id, name from t2]: select_type is union, specify id The selection of =4 is the second selection in the union.
2 (id = 3), [select id, name from t1 where address = '11']: Because it is a subquery included in the from statement, it is marked as DERIVED (derived), where address = '11' can be retrieved through the composite index idx_name_email_address, so the type is index.
3 (id = 2), [select id from t3]: Because it is a subquery included in select, it is marked as SUBQUERY.
4 (id = 1), [select d1.name, … d2 from … d1]: select_type is PRIMARY, which means that the query is the outermost query, and the table column is marked as "derived3", which means that the query results come from In a derived table (select result of id = 3).
5 (id = NULL), [... union...]: Represents the stage of reading rows from the union's temporary table. "Union 1, 4" in the table column means id=1 and id=4 Perform union operation on the select results.
Recommended learning: mysql video tutorial
The above is the detailed content of How to view execution plan in Mysql. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
Recovering deleted rows directly from the database is usually impossible unless there is a backup or transaction rollback mechanism. Key point: Transaction rollback: Execute ROLLBACK before the transaction is committed to recover data. Backup: Regular backup of the database can be used to quickly restore data. Database snapshot: You can create a read-only copy of the database and restore the data after the data is deleted accidentally. Use DELETE statement with caution: Check the conditions carefully to avoid accidentally deleting data. Use the WHERE clause: explicitly specify the data to be deleted. Use the test environment: Test before performing a DELETE operation.
 How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
Steps to perform SQL in Navicat: Connect to the database. Create a SQL Editor window. Write SQL queries or scripts. Click the Run button to execute a query or script. View the results (if the query is executed).
