

Let's talk about MySQL index structure


Recommended learning: mysql video tutorial
Introduction
In addition to data, the database system also maintains Data structures that satisfy specific search algorithms. These data structures reference (point to) data in some way so that advanced search algorithms can be implemented on these data structures. This data structure is an index.
Generally speaking, the index itself is also very large and cannot be stored entirely in memory, so the index is often stored on disk in the form of an index file.
Advantages:
1. Similar to building a bibliographic index in a university library, it improves the efficiency of data retrieval and reduces the IO cost of the database.
2. Sort data through index columns to reduce the cost of data sorting and reduce CPU consumption.
Disadvantages:
1. Although the index greatly improves the query speed, it will also reduce the speed of updating the table, such as INSERT, UPDATE and DELETE on the table. Because when updating the table, MySQL not only needs to save the data, but also save the index file. Every time a field that adds an index column is updated, the index information after the key value changes caused by the update will be adjusted.
2. In fact, the index is also a table. This table saves the primary key and index fields and points to the records of the entity table, so the index column also takes up space.
Index example: ( Use tree structure as index)
The left side is the data table, with a total of two columns and seven records. The leftmost one is the physical address of the data record.
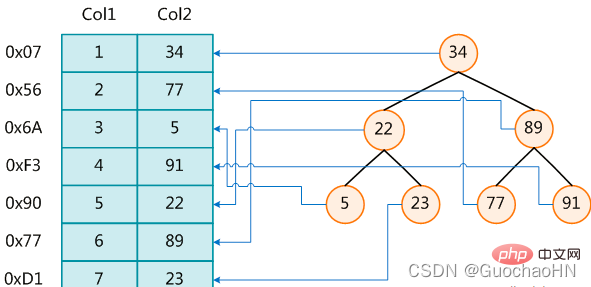
In order to speed up the search of Col2, you can maintain a binary search tree as shown on the right. Each node contains the index key value and a pointer to the physical address of the corresponding data record. Pointer, so that you can use binary search to obtain the corresponding data within a certain complexity, thereby quickly retrieving records that meet the conditions.
Index structure (tree)
How to speed up the query speed of database tables through indexes? For the convenience of explanation, we limit the database table to only include the following two query requirements:
1. select* from user where id=1234;
2. select *from user where id>1234 and id<2345; (by interval)
Why use a tree instead of a hash table
Ha The performance of Greek table query by value is very good, and the time complexity is O(1), but it cannot support fast search of data according to intervals, so it cannot meet the requirements. In the same way, although the query performance of the balanced binary search tree is very high, the time complexity is O(logn), and the in-order traversal of the tree can output an ordered data sequence, it cannot meet the need to quickly find data according to intervals. .
In order to support fast search of data according to intervals, we transform the binary search tree and string the leaf nodes of the binary search tree with a linked list. If you want to find data in a certain interval, you only need to use the interval The starting value is searched in the tree. After locating a node in the ordered linked list, it starts from this node and traverses along the ordered linked list until the node data value in the ordered linked list is greater than the interval end value. until.
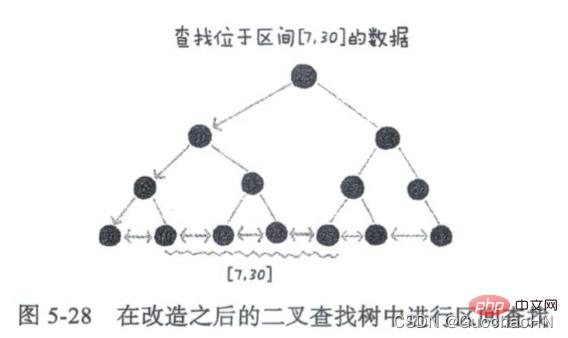
And because the time complexity of many operations on the tree is proportional to the height of the tree, reducing the height of the tree can reduce disk IO operations. Therefore, we build the index into an m-ary tree (m>2). Please see the following article for details.
BTree Index
Before introducing the B-tree, let’s first understand the B-tree.
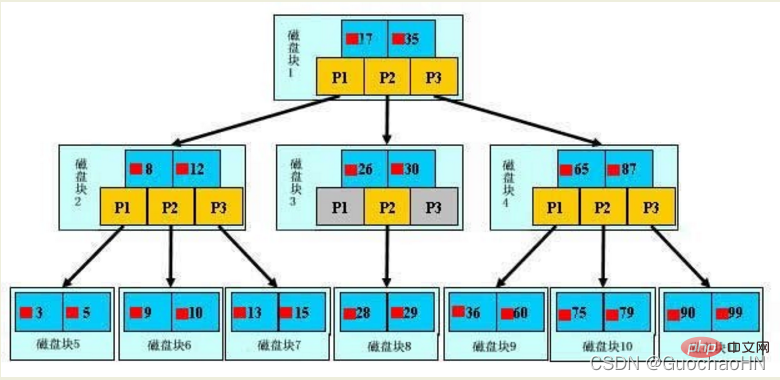
1. Initialization introduction
A b-tree, the light blue block is called a disk block, you can see each disk block Contains several data items (shown in dark blue) and pointers (shown in yellow). For example, disk block 1 contains data items 17 and 35, and contains pointers P1, P2, and P3. P1 represents disk blocks less than 17, P2 represents disk blocks between 17 and 35, and P3 represents disk blocks greater than 35.
Note:
Real data only exists in leaf nodes, namely 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. (And it is a data interval composed of multiple pieces of data: 3~5,...,90~99)
Non-leaf nodes do not store real data, but only store data items that guide the search direction, such as 17, 35 does not actually exist in the data sheet.
2. Search process
If you want to find data item 29, you will first load disk block 1 from the disk to the memory. At this time, an IO occurs. Use a binary search in the memory to determine that 29 is between 17 and 35, and lock P2 of disk block 1. Pointer, memory time can be ignored because it is very short (compared to disk IO). Disk block 3 is loaded from the disk to the memory through the disk address of the P2 pointer of disk block 1. The second IO occurs, 29 between 26 and 30. During the period, the P2 pointer of disk block 3 is locked, and disk block 8 is loaded into the memory through the pointer. The third IO occurs. At the same time, a binary search is performed in the memory to find 29, and the query is ended. A total of three IOs.
B Tree Index
B tree is similar to B tree, and B tree is an improved version of B tree. That is: the tree constructed by the m-fork search tree and the ordered linked list is the B-tree, which is the tree index to be stored
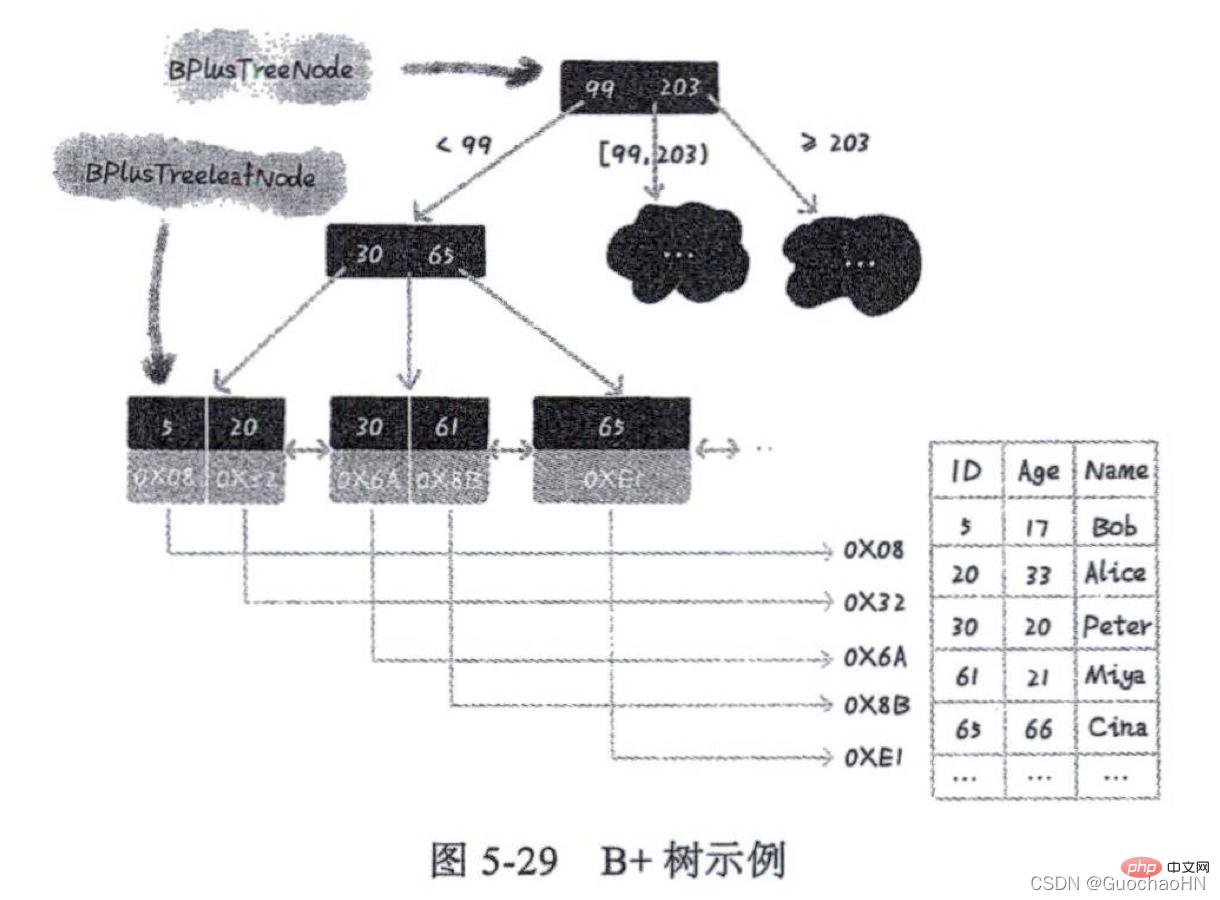
As shown in the figure: B-tree and the main features of the B-tree The differences are as follows:
1. The leaf nodes of the B-tree are connected in series using a linked list. To find data in a certain interval, you only need to use the starting value of the interval to search in the tree. After locating a node in the ordered linked list, start from this node and traverse backward along the ordered linked list until Until the node data value in the ordered linked list is greater than the interval end value.
2. Any node in the B-tree does not store real data, but is only used for indexing. B-tree obtains data directly through leaf nodes; and each leaf node of B-tree stores the key value and address information of the data row. When a certain leaf node is queried, the real data information is found through the address of the leaf node.
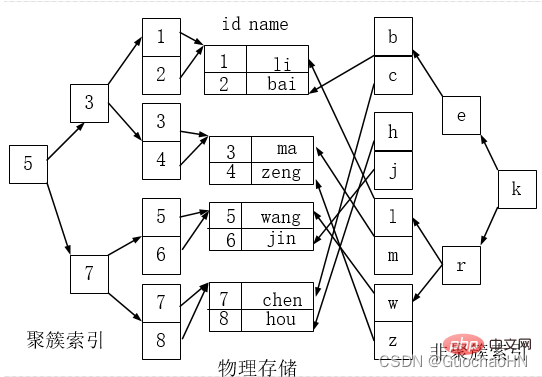
Clustered index and non-clustered index
Clustered index is not a separate index type, but a data storage method. The term 'clustered' refers to the storage of data rows and adjacent key-value clusters together.
Benefits of clustered index:
According to the clustered index arrangement order, when the query displays a certain range of data, because the data are closely connected, the database does not have to extract from multiple data blocks data, so it saves a lot of io operations.
Limitations of clustered indexes:
1. For the mysql database, currently only the innodb data engine supports clustered indexes, while Myisam does not support clustered indexes.
2. Since there can only be one physical storage sorting method for data, each Mysql table can only have one clustered index. Usually it is the primary key of the table.
3. In order to make full use of the clustering characteristics of the clustered index, the primary key column of the innodb table should try to use ordered sequential IDs, and it is not recommended to use unordered IDs, such as uuid.
As shown below, the index on the left is a clustered index, because the arrangement of data rows on the disk is consistent with the index sorting.
Index classification
Single value index
That is, an index only contains a single column, and a table can have multiple single-column indexes
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name); 删除索引: DROP INDEX idx_customer_name on customer;
Unique index
The value of the index column must be unique, but null values are allowed
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); 删除索引: DROP INDEX idx_customer_no on customer ;
Primary key index
After setting the primary key, the database will automatically create an index , innodb is a clustered index
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引
Compound index
That is, an index contains multiple columns
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name); 删除索引: DROP INDEX idx_no_name on customer ;
Performance analysis
Index creation scenario
In which cases it is necessary to create an index
1. The primary key automatically creates a unique index
2. Fields that are frequently used as query conditions should create indexes
3 , Fields associated with other tables in the query, foreign key relationships to establish indexes
4. Single key/combined index selection problem, the combined index is more cost-effective
5. Sorted fields in the query , if the sorting field is accessed through the index, the sorting speed will be greatly improved
6. Statistics or grouping fields in the query
Under what circumstances should not create an index
1. There are too few table records
2. Reasons for tables or fields that are frequently added, deleted or modified: It improves the query speed, but at the same time reduces the speed of updating the table, such as INSERT, UPDATE and DELETE on the table. Because when updating the table, MySQL not only needs to save the data, but also save the index file
3. No index will be created for fields that are not used in the Where condition
4. If the filtering is not good, no index will be created. Suitable for index building
Recommended learning:mysql video tutorial
The above is the detailed content of Let's talk about MySQL index structure. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
