
 Backend Development
Python Tutorial
How to download pictures concurrently with multiple threads in Python
Backend Development
Python Tutorial
How to download pictures concurrently with multiple threads in Python
How to download pictures concurrently with multiple threads in Python


Sometimes it takes hours to download a large number of images - let's fix that
I get it - you're tired of waiting for your program to download image. Sometimes I have to download thousands of images that take hours, and you can't keep waiting for your program to finish downloading these stupid images. You have a lot of important things to do.
Let's build a simple image downloader script that will read a text file and download all the images listed in a folder super fast.
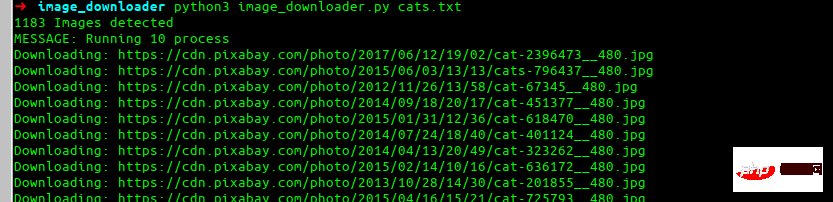
Final effect
This is the final effect we want to build.

Installing dependencies
Let’s install everyone’s favorite requests library.
pip install requests
Now we will see some basic code for downloading a single URL and trying to automatically find the image name and how to use retries.
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>Here we retry downloading the image five times in case it fails. Now, let's try to automatically find the name of the image and save it. </p><pre class="brush:php;toolbar:false">import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]Explanation
Assume that the URL we want to download is:
instagram.fktm7-1.fna.fbcdn.net/vp ...
Okay, this is a mess. Let’s break down what the code does for the URL. We first use rfind to find the last forward slash (/) and then select everything after that. This is the result:
##65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
Now for our second part find a? and then just take whatever comes before it.
65872070_1200425330158967_6201268309743367902_n.jpg
This result is very good and suitable for most use cases. Now that we have downloaded the image name and image, we will save it.i = Image.open(io.BytesIO(res.content)) i.save(image_name)
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count Now, you may ask: "Where is the multiprocessing this person is talking about?". <p></p>this is very simple. We will simply define our pool and pass it our function and image URL. <p></p><pre class="brush:php;toolbar:false">results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)- Takes as input an image list text file and a process number
- Downloads them at the speed you want
- Print the total time to download the file
- There are also some nice functions that can help us read the file name and handle errors and other stuff
Full script# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count Copy after login
Save it to a How to download pictures concurrently with multiple threads in How to download pictures concurrently with multiple threads in Python file and run it.
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count python3 image_downloader.py cats.txt
Usagepython3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process></num_of_process></filename_with_urls_seperated_by_newline.txt>
Copy after login
This will read all the URLs in the text file and download them to a folder with the same name as the file name.
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process></num_of_process></filename_with_urls_seperated_by_newline.txt>
num_of_process is optional (by default it uses 10 processes).
Examplepython3 image_downloader.py cats.txt
Copy after loginCopy after login
python3 image_downloader.py cats.txt
 ##I would be happy to contribute any advice on how to improve this further respond.
##I would be happy to contribute any advice on how to improve this further respond.
[Related recommendations:How to download pictures concurrently with multiple threads in How to download pictures concurrently with multiple threads in Python3 video tutorial
The above is the detailed content of How to download pictures concurrently with multiple threads in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python is widely used in the fields of web development, data science, machine learning, automation and scripting. 1) In web development, Django and Flask frameworks simplify the development process. 2) In the fields of data science and machine learning, NumPy, Pandas, Scikit-learn and TensorFlow libraries provide strong support. 3) In terms of automation and scripting, Python is suitable for tasks such as automated testing and system management.
 The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
You can learn basic programming concepts and skills of Python within 2 hours. 1. Learn variables and data types, 2. Master control flow (conditional statements and loops), 3. Understand the definition and use of functions, 4. Quickly get started with Python programming through simple examples and code snippets.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
As a data professional, you need to process large amounts of data from various sources. This can pose challenges to data management and analysis. Fortunately, two AWS services can help: AWS Glue and Amazon Athena.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
Question: How to view the Redis server version? Use the command line tool redis-cli --version to view the version of the connected server. Use the INFO server command to view the server's internal version and need to parse and return information. In a cluster environment, check the version consistency of each node and can be automatically checked using scripts. Use scripts to automate viewing versions, such as connecting with Python scripts and printing version information.
 How secure is Navicat's password?
Apr 08, 2025 pm 09:24 PM
How secure is Navicat's password?
Apr 08, 2025 pm 09:24 PM
Navicat's password security relies on the combination of symmetric encryption, password strength and security measures. Specific measures include: using SSL connections (provided that the database server supports and correctly configures the certificate), regularly updating Navicat, using more secure methods (such as SSH tunnels), restricting access rights, and most importantly, never record passwords.
