

How to download a large number of images using How to use How to use Python to download images concurrently with multiple threads to download images concurrently with multiple threads? The following article will introduce to you how to use How to use How to use Python to download images concurrently with multiple threads to download images concurrently with multiple threads to download images concurrently with multiple threads. I hope it will be helpful to you!

Sometimes it takes hours to download a large number of images - let's fix that
I get it - you're tired of waiting program to download images. Sometimes I have to download thousands of images that take hours, and you can't keep waiting for your program to finish downloading these stupid images. You have a lot of important things to do.
Let's build a simple image downloader script that will read a text file and download all the images listed in a folder super fast.
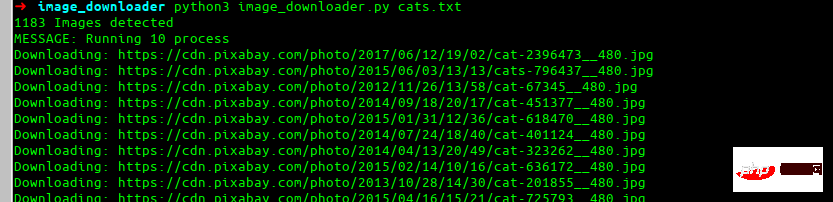
This is the final effect we want to build.

Let’s install everyone’s favorite requests library.
pip install requests
Now we will see some basic code for downloading a single URL and trying to automatically find the image name and how to use retries.
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1Here we retry downloading the image five times in case it fails. Now, let's try to automatically find the name of the image and save it.
import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]Suppose the URL we want to download is:
instagram.fktm7-1.fna.fbcdn. net/vp...
Okay, this is a mess. Let’s break down what the code does for the URL. We first use rfind to find the last forward slash (/) and then select everything after that. This is the result:
##65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
Now for our second part find a? and then just take whatever comes before it.
65872070_1200425330158967_6201268309743367902_n.jpg
This result is very good and suitable for most use cases. Now that we have downloaded the image name and image, we will save it.i = Image.open(io.BytesIO(res.content)) i.save(image_name)
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = 'cats'
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = get_download_location()
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'
def run_downloader(process:int, images_url:list):
"""
输入项:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)
try:
num_process = int(sys.argv[2])
except:
num_process = 10
images_url = get_urls()
run_downloader(num_process, images_url)
end = time.time()
print('Time taken to download {}'.format(len(get_urls())))
print(end - start)python3 image_downloader.py cats.txt
GitHub repository.
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process>
num_of_process is optional (by default it uses 10 processes).
Examples
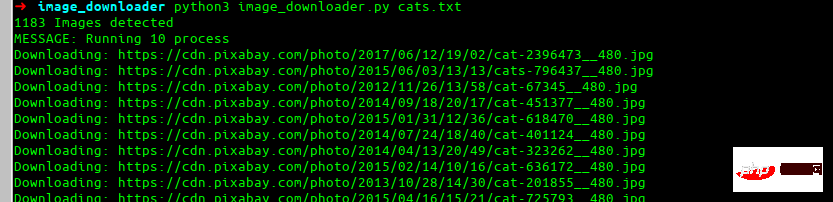
python3 image_downloader.py cats.txt

How to use How to use Python to download images concurrently with multiple threads to download images concurrently with multiple threads3 video tutorial】
The above is the detailed content of How to use Python to download images concurrently with multiple threads. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



