
 Database
Redis
Understand redis cache avalanche, cache breakdown and cache penetration in one article
Database
Redis
Understand redis cache avalanche, cache breakdown and cache penetration in one article
Understand redis cache avalanche, cache breakdown and cache penetration in one article

This article brings you relevant knowledge about Redis, which mainly introduces the relevant content about cache avalanche, cache breakdown and cache penetration. Let’s take a look at it together. I hope it will be helpful to you. Everyone is helpful.

Recommended learning: Redis video tutorial
About Redis’ high-frequency issues, cache avalanche, cache breakdown and cache penetration It must be indispensable. I believe everyone has been asked similar questions during interviews. Why are these questions so popular? Because when we use Redis cache, these problems are easy to encounter. Next, let’s take a look at how these problems arise and what the corresponding solutions are.
Cache avalanche
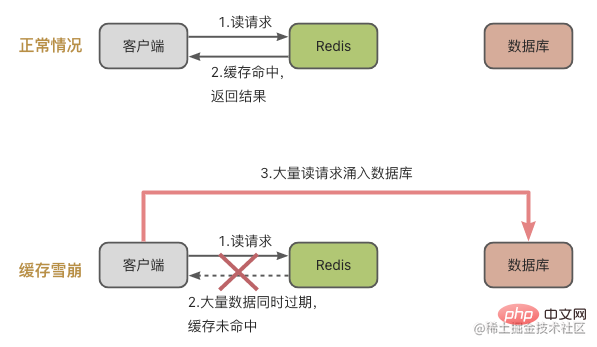
First let’s take a look at cache avalanche. The concept of cache avalanche is: a large number of requests are not processed in the Redis cache, resulting in requests flooding into the database. , and then the pressure on the database increases dramatically.
The reasons causing cache avalanche can be summarized as two:
- There is a large amount of data in the cache that expires at the same time, so a large number of requests are sent to the database at this time.
- The Redis cache instance fails and cannot handle a large number of requests, which also causes the requests to go to the database.
Let’s take a look at the first scenario: a large amount of data in the cache expires at the same time.
A large amount of data in the cache expires at the same time
Combined with the legend, it means that a large amount of data expires at the same time, and then there are many requests to read the data at this time. Of course, a cache avalanche will occur, causing a dramatic increase in database pressure.
Solutions for a large amount of data to expire at the same time
To deal with the problem of a large amount of data to expire at the same time, there are usually two solutions:
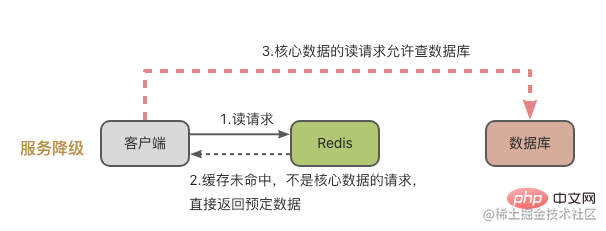
- Add a random time to the data expiration setting: that is, when you use the expire command to set the expiration time for the data, add a random time. For example, data a expires in 5 minutes, and 10-120 seconds are randomly added to the 5 minutes. This prevents large amounts of data from expiring at the same time.
- Service degradation: that is, when a cache avalanche occurs, (1) if the access is not core data, when there is no cache hit, the database will not go to the database, and preset information, such as null values or errors, will be returned directly. Information; (2) When accessing core data and the cache misses, database query is allowed. In this way, all requests that are not core data will be rejected and sent to the database.
#After looking at the situation where a large amount of data expires at the same time, let’s take a look at the situation where the Redis cache instance fails.
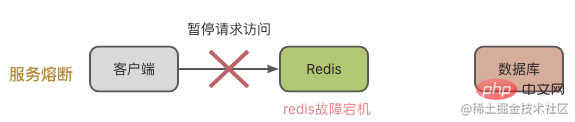
Cache avalanche caused by Redis cache instance failure
In this case, Redis cannot process the read request, and the request will naturally be sent to the database.
Generally speaking, we have two ways to deal with this situation:
- Do a good job of service circuit breaker/request current limiting in the business system.
- Precaution in advance: Build a Redis high-reliability cluster, such as master-slave cluster switching.
Service circuit breaker means that when Redis fails, requests for access to the cache system are suspended. Wait until Redis returns to normal before opening the request for access.
In this way we need to monitor the running status of Redis or the database, such as MySQL's load pressure, Redis's CPU usage, memory usage and QPS, etc. When it is discovered that the Redis instance cache has collapsed, the service will be suspended.
This situation can effectively place a large number of requests and put pressure on the database. However, access requests will be suspended, which will have a great impact on the business end.
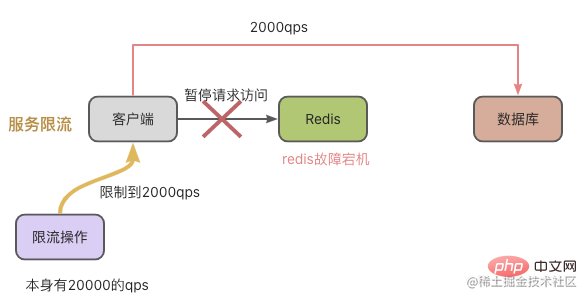
Therefore, in order to reduce the impact on the business end, we can use the request current limiting method to control QPS and avoid too many requests to the database. For example, in the illustration below, there are 20,000 requests per second, but it was down due to a Redis failure. Our current limiting operation reduced the qps to 2,000 per second, and the database still had no problem processing 2,000 qps.
Cache breakdown
Cache breakdown means that individual frequently accessed hotspot data cannot be cached, and then requests are poured into the database. It often happens when hotspot data expires.
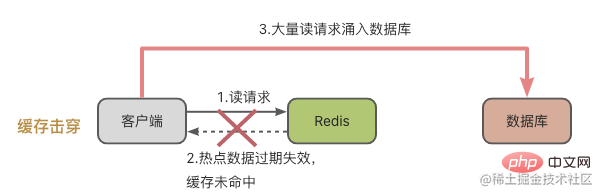
Regarding the cache breakdown problem, we know that these are hot data that are accessed very frequently, so the processing method is simple and crude, and the expiration time is not set directly. Just wait until the hotspot data is not accessed frequently and then handle it manually.
Cache Penetration
Cache avalanche is something special. It means that the data to be accessed is neither in the Redis cache nor in the database. When a large number of requests enter the system, Redis and the database will be under tremendous pressure.
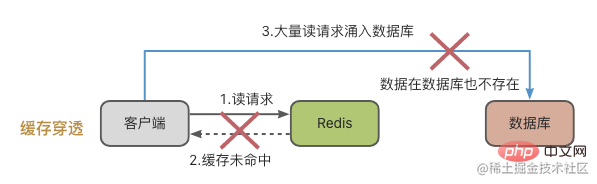
There are usually two reasons for cache penetration:
- The data is accidentally deleted, resulting in no data in the cache and database. However, the client doesn't know this and is still requesting frantically.
- In the case of malicious attacks: that is, someone is targeting you to check for data that is not available.
For cache penetration, you can refer to the following solutions:
- is to set a null value or default value for the cache value. For example, when cache penetration occurs, set a null value/default value in the Redis cache. Subsequent queries for this value will directly return this default value.
- Use Bloom filter to determine whether the data exists and avoid querying from the database.
- Perform request detection on the front end. For example, filter some illegal requests directly on the front end instead of sending them to the back end for processing.
The first and third points are easier to understand and will not be described here. Let’s focus on the second point: Bloom filters.
Bloom filter
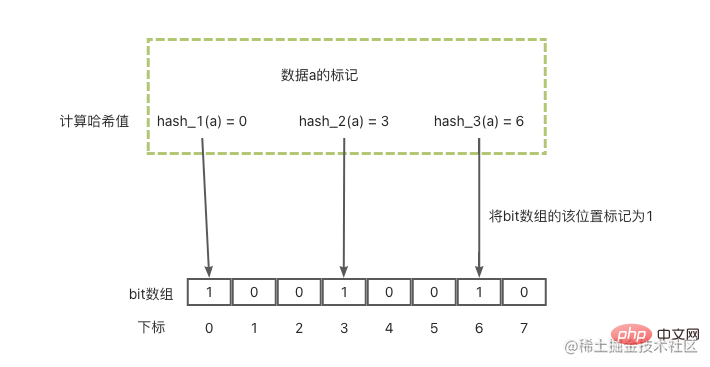
The Bloom filter is mainly used to determine whether an element is in a set. It consists of a fixed-size binary vector (can be understood as a bit array with a default value of 0) and a series of mapping functions.
Let’s first take a look at how the Bloom filter marks a data a:
- In the first step, multiple mapping functions (hash functions) will be used. Each Each function will calculate the hash value of this data a;
- In the second step, these calculated hash values will be modulo the length of the bit array respectively, so that each hash value on the array is obtained position;
- The third step is to set the positions obtained in the second step to 1 on the bit array respectively.
After these 3 steps, data labeling is completed. Then you need to query the data when it is not there:
- First calculate the multiple positions of this data in the bit array;
- Then check these positions of the bit array respectively bit value. Only if the bit value of each position is 1, it means that the data may exist, otherwise the data must not exist.
Combined with the picture below, the basic principle is like this.
Recommended learning: Redis video tutorial
The above is the detailed content of Understand redis cache avalanche, cache breakdown and cache penetration in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
Redis, as a message middleware, supports production-consumption models, can persist messages and ensure reliable delivery. Using Redis as the message middleware enables low latency, reliable and scalable messaging.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
