

Let's talk about Golang's own HttpClient timeout mechanism

In the process of writing Go, I often compare the characteristics of these two languages. I have stepped on many pitfalls and found many interesting places. In this article, I will talk about the timeout mechanism of HttpClient that comes with Go. I hope Helpful to everyone.

The underlying principle of Java HttpClient timeout
Before introducing Go’s HttpClient timeout mechanism, let’s first take a look at Java’s How to implement timeout. [Related recommendations: Go Video Tutorial]
Write a Java native HttpClient, and set the connection timeout and read timeout corresponding to the underlying methods:
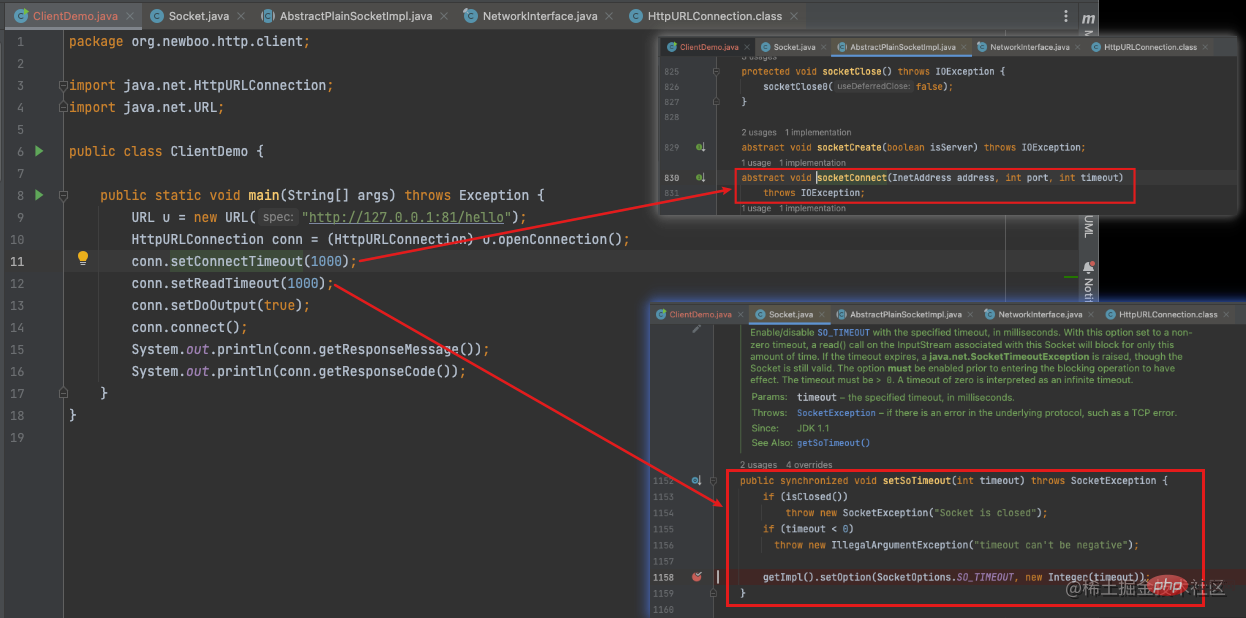
Going back to the JVM source code, I found that it is an encapsulation of system calls. In fact, not only Java, most programming languages make use of the timeout capability provided by the operating system.
However, Go's HttpClient provides another timeout mechanism, which is quite interesting. Let's take a look. But before we get started, let’s first understand Go’s Context.
Go Context Introduction
What is Context?
According to the comments in the Go source code:
// A Context carries a deadline, a cancellation signal, and other values across // API boundaries. // Context's methods may be called by multiple goroutines simultaneously.
Context is simply an interface that can carry timeouts, cancellation signals and other data. Context's methods will be called by multiple goroutines simultaneously. transfer.
Context is somewhat similar to Java's ThreadLocal. It can transfer data in threads, but it is not exactly the same. It is an explicit transfer, while ThreadLocal is an implicit transfer. In addition to passing data, Context can also carry timeout, Cancel signal.
Context only defines the interface, and several specific implementations are provided in Go:
- Background: empty implementation, does nothing
- TODO: I don’t know what Context to use yet, so I’ll use TODO instead, which is also an empty Context that does nothing.
- cancelCtx: Cancelable Context
- timerCtx: Active timeout Context
For the three characteristics of Context, you can learn more about the Context implementation provided by Go and the examples in the source code.
Context Three feature examples
The examples in this part come from the source code of Go, located at src/context/example_test.go
Carry data
Use context.WithValue to carry it, use Value to get the value, in the source code The example is as follows:
// 来自 src/context/example_test.go
func ExampleWithValue() {
type favContextKey string
f := func(ctx context.Context, k favContextKey) {
if v := ctx.Value(k); v != nil {
fmt.Println("found value:", v)
return
}
fmt.Println("key not found:", k)
}
k := favContextKey("language")
ctx := context.WithValue(context.Background(), k, "Go")
f(ctx, k)
f(ctx, favContextKey("color"))
// Output:
// found value: Go
// key not found: color
}Cancel
First, start a coroutine to execute an infinite loop, continuously write data to the channel, and listen to ctx at the same time. The event
// 来自 src/context/example_test.go
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
} then generates a cancelable Context through context.WithCancel and passes in the gen method until gen When 5 is returned, call cancel to cancel the execution of the gen method.
// 来自 src/context/example_test.go
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // cancel when we are finished consuming integers
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
break
}
}
// Output:
// 1
// 2
// 3
// 4
// 5It seems that it can be simply understood as burying the end flag in the loop of one coroutine, and another coroutine sets the end flag.
Timeout
With the foreshadowing of cancel, timeout is easy to understand. Cancel is manual cancellation, and timeout is automatic cancellation. As long as a scheduled coroutine is started, Just execute cancel after the time.
There are two ways to set the timeout: context.WithTimeout and context.WithDeadline. WithTimeout is to set a period of time, WithDeadline is to set a deadline, and WithTimeout It will also eventually be converted to WithDeadline.
// 来自 src/context/example_test.go
func ExampleWithTimeout() {
// Pass a context with a timeout to tell a blocking function that it
// should abandon its work after the timeout elapses.
ctx, cancel := context.WithTimeout(context.Background(), shortDuration)
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err()) // prints "context deadline exceeded"
}
// Output:
// context deadline exceeded
}Another timeout mechanism of Go HttpClient
Based on Context, you can set the timeout mechanism for the execution of any code segment, and you can design a request that is independent of the operating system's capabilities. Timeout capability.
Introduction to the timeout mechanism
Look at Go’s HttpClient timeout configuration instructions:
client := http.Client{
Timeout: 10 * time.Second,
}
// 来自 src/net/http/client.go
type Client struct {
// ... 省略其他字段
// Timeout specifies a time limit for requests made by this
// Client. The timeout includes connection time, any
// redirects, and reading the response body. The timer remains
// running after Get, Head, Post, or Do return and will
// interrupt reading of the Response.Body.
//
// A Timeout of zero means no timeout.
//
// The Client cancels requests to the underlying Transport
// as if the Request's Context ended.
//
// For compatibility, the Client will also use the deprecated
// CancelRequest method on Transport if found. New
// RoundTripper implementations should use the Request's Context
// for cancellation instead of implementing CancelRequest.
Timeout time.Duration
}Translate the comments: Timeout includes the time for connecting, redirecting, and reading data. The timer will interrupt the reading of data after the Timeout time. If it is set to 0, there will be no timeout limit.
That is to say, this timeout is the overall timeout period of a request, without having to set the connection timeout, read timeout, etc. separately.
This may be a better choice for users. In most scenarios, users do not need to care about which part causes the timeout, but just want to know when the HTTP request as a whole can be returned.
The underlying principle of the timeout mechanism
The simplest example is used to illustrate the underlying principle of the timeout mechanism.
这里我起了一个本地服务,用 Go HttpClient 去请求,超时时间设置为 10 分钟,建议使 Debug 时设置长一点,否则可能超时导致无法走完全流程。
client := http.Client{
Timeout: 10 * time.Minute,
}
resp, err := client.Get("http://127.0.0.1:81/hello")1. 根据 timeout 计算出超时的时间点
// 来自 src/net/http/client.go deadline = c.deadline()
2. 设置请求的 cancel
// 来自 src/net/http/client.go stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
这里返回的 stopTimer 就是可以手动 cancel 的方法,didTimeout 是判断是否超时的方法。这两个可以理解为回调方法,调用 stopTimer() 可以手动 cancel,调用 didTimeout() 可以返回是否超时。
设置的主要代码其实就是将请求的 Context 替换为 cancelCtx,后续所有的操作都将携带这个 cancelCtx:
// 来自 src/net/http/client.go
var cancelCtx func()
if oldCtx := req.Context(); timeBeforeContextDeadline(deadline, oldCtx) {
req.ctx, cancelCtx = context.WithDeadline(oldCtx, deadline)
}同时,再起一个定时器,当超时时间到了之后,将 timedOut 设置为 true,再调用 doCancel(),doCancel() 是调用真正 RoundTripper (代表一个 HTTP 请求事务)的 CancelRequest,也就是取消请求,这个跟实现有关。
// 来自 src/net/http/client.go
timer := time.NewTimer(time.Until(deadline))
var timedOut atomicBool
go func() {
select {
case <-initialReqCancel:
doCancel()
timer.Stop()
case <-timer.C:
timedOut.setTrue()
doCancel()
case <-stopTimerCh:
timer.Stop()
}
}()Go 默认 RoundTripper CancelRequest 实现是关闭这个连接
// 位于 src/net/http/transport.go
// CancelRequest cancels an in-flight request by closing its connection.
// CancelRequest should only be called after RoundTrip has returned.
func (t *Transport) CancelRequest(req *Request) {
t.cancelRequest(cancelKey{req}, errRequestCanceled)
}3. 获取连接
// 位于 src/net/http/transport.go
for {
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// ...
pconn, err := t.getConn(treq, cm)
// ...
}代码的开头监听 ctx.Done,如果超时则直接返回,使用 for 循环主要是为了请求的重试。
后续的 getConn 是阻塞的,代码比较长,挑重点说,先看看有没有空闲连接,如果有则直接返回
// 位于 src/net/http/transport.go
// Queue for idle connection.
if delivered := t.queueForIdleConn(w); delivered {
// ...
return pc, nil
}如果没有空闲连接,起个协程去异步建立,建立成功再通知主协程
// 位于 src/net/http/transport.go // Queue for permission to dial. t.queueForDial(w)
再接着是一个 select 等待连接建立成功、超时或者主动取消,这就实现了在连接过程中的超时
// 位于 src/net/http/transport.go
// Wait for completion or cancellation.
select {
case <-w.ready:
// ...
return w.pc, w.err
case <-req.Cancel:
return nil, errRequestCanceledConn
case <-req.Context().Done():
return nil, req.Context().Err()
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}4. 读写数据
在上一条连接建立的时候,每个链接还偷偷起了两个协程,一个负责往连接中写入数据,另一个负责读数据,他们都监听了相应的 channel。
// 位于 src/net/http/transport.go go pconn.readLoop() go pconn.writeLoop()
其中 wirteLoop 监听来自主协程的数据,并往连接中写入
// 位于 src/net/http/transport.go
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
// ...
if err != nil {
pc.close(err)
return
}
case <-pc.closech:
return
}
}
}同理,readLoop 读取响应数据,并写回主协程。读与写的过程中如果超时了,连接将被关闭,报错退出。
超时机制小结
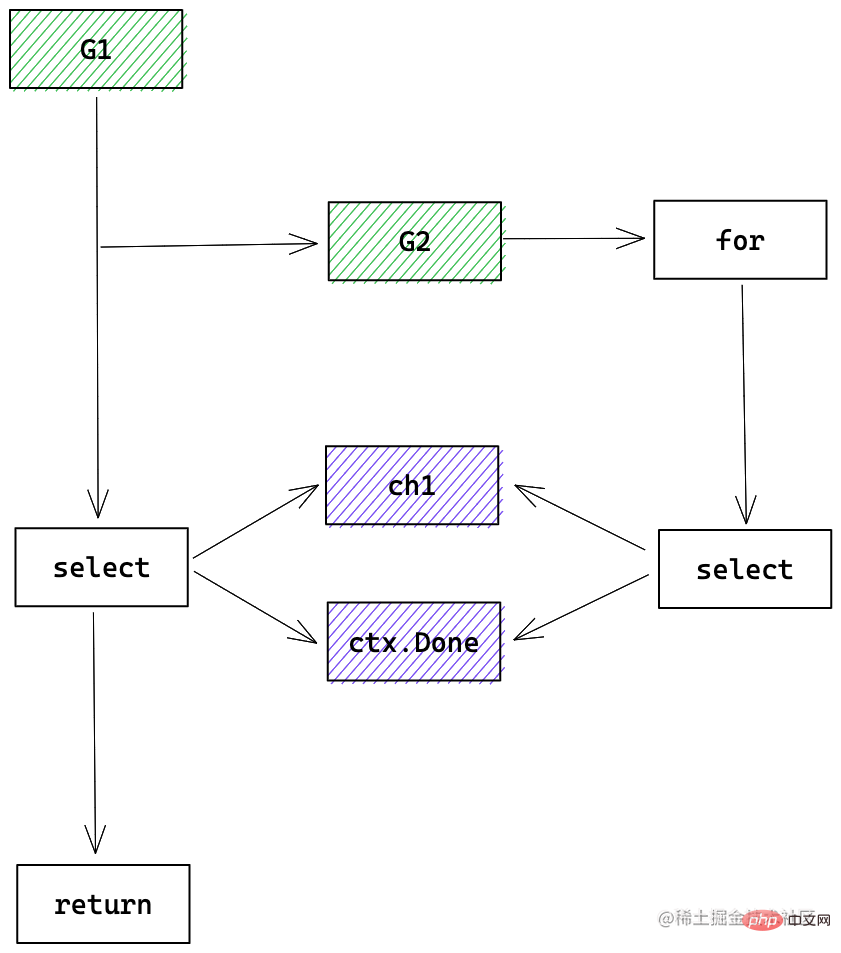
Go 的这种请求超时机制,可随时终止请求,可设置整个请求的超时时间。其实现主要依赖协程、channel、select 机制的配合。总结出套路是:
- 主协程生成 cancelCtx,传递给子协程,主协程与子协程之间用 channel 通信
- 主协程 select channel 和 cancelCtx.Done,子协程完成或取消则 return
- 循环任务:子协程起一个循环处理,每次循环开始都 select cancelCtx.Done,如果完成或取消则退出
- 阻塞任务:子协程 select 阻塞任务与 cancelCtx.Done,阻塞任务处理完或取消则退出
以循环任务为例
Java 能实现这种超时机制吗
直接说结论:暂时不行。
首先 Java 的线程太重,像 Go 这样一次请求开了这么多协程,换成线程性能会大打折扣。
其次 Go 的 channel 虽然和 Java 的阻塞队列类似,但 Go 的 select 是多路复用机制,Java 暂时无法实现,即无法监听多个队列是否有数据到达。所以综合来看 Java 暂时无法实现类似机制。
总结
本文介绍了 Go 另类且有趣的 HTTP 超时机制,并且分析了底层实现原理,归纳出了这种机制的套路,如果我们写 Go 代码,也可以如此模仿,让代码更 Go。
原文地址:https://juejin.cn/post/7166201276198289445
更多编程相关知识,请访问:编程视频!!
The above is the detailed content of Let's talk about Golang's own HttpClient timeout mechanism. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to safely read and write files using Golang?
Jun 06, 2024 pm 05:14 PM
How to safely read and write files using Golang?
Jun 06, 2024 pm 05:14 PM
Reading and writing files safely in Go is crucial. Guidelines include: Checking file permissions Closing files using defer Validating file paths Using context timeouts Following these guidelines ensures the security of your data and the robustness of your application.
 How to configure connection pool for Golang database connection?
Jun 06, 2024 am 11:21 AM
How to configure connection pool for Golang database connection?
Jun 06, 2024 am 11:21 AM
How to configure connection pooling for Go database connections? Use the DB type in the database/sql package to create a database connection; set MaxOpenConns to control the maximum number of concurrent connections; set MaxIdleConns to set the maximum number of idle connections; set ConnMaxLifetime to control the maximum life cycle of the connection.
 How to use gomega for assertions in Golang unit tests?
Jun 05, 2024 pm 10:48 PM
How to use gomega for assertions in Golang unit tests?
Jun 05, 2024 pm 10:48 PM
How to use Gomega for assertions in Golang unit testing In Golang unit testing, Gomega is a popular and powerful assertion library that provides rich assertion methods so that developers can easily verify test results. Install Gomegagoget-ugithub.com/onsi/gomega Using Gomega for assertions Here are some common examples of using Gomega for assertions: 1. Equality assertion import "github.com/onsi/gomega" funcTest_MyFunction(t*testing.T){
 Golang framework vs. Go framework: Comparison of internal architecture and external features
Jun 06, 2024 pm 12:37 PM
Golang framework vs. Go framework: Comparison of internal architecture and external features
Jun 06, 2024 pm 12:37 PM
The difference between the GoLang framework and the Go framework is reflected in the internal architecture and external features. The GoLang framework is based on the Go standard library and extends its functionality, while the Go framework consists of independent libraries to achieve specific purposes. The GoLang framework is more flexible and the Go framework is easier to use. The GoLang framework has a slight advantage in performance, and the Go framework is more scalable. Case: gin-gonic (Go framework) is used to build REST API, while Echo (GoLang framework) is used to build web applications.
 How to save JSON data to database in Golang?
Jun 06, 2024 am 11:24 AM
How to save JSON data to database in Golang?
Jun 06, 2024 am 11:24 AM
JSON data can be saved into a MySQL database by using the gjson library or the json.Unmarshal function. The gjson library provides convenience methods to parse JSON fields, and the json.Unmarshal function requires a target type pointer to unmarshal JSON data. Both methods require preparing SQL statements and performing insert operations to persist the data into the database.
 What are the best practices for error handling in Golang framework?
Jun 05, 2024 pm 10:39 PM
What are the best practices for error handling in Golang framework?
Jun 05, 2024 pm 10:39 PM
Best practices: Create custom errors using well-defined error types (errors package) Provide more details Log errors appropriately Propagate errors correctly and avoid hiding or suppressing Wrap errors as needed to add context
 How to find the first substring matched by a Golang regular expression?
Jun 06, 2024 am 10:51 AM
How to find the first substring matched by a Golang regular expression?
Jun 06, 2024 am 10:51 AM
The FindStringSubmatch function finds the first substring matched by a regular expression: the function returns a slice containing the matching substring, with the first element being the entire matched string and subsequent elements being individual substrings. Code example: regexp.FindStringSubmatch(text,pattern) returns a slice of matching substrings. Practical case: It can be used to match the domain name in the email address, for example: email:="user@example.com", pattern:=@([^\s]+)$ to get the domain name match[1].
 Transforming from front-end to back-end development, is it more promising to learn Java or Golang?
Apr 02, 2025 am 09:12 AM
Transforming from front-end to back-end development, is it more promising to learn Java or Golang?
Apr 02, 2025 am 09:12 AM
Backend learning path: The exploration journey from front-end to back-end As a back-end beginner who transforms from front-end development, you already have the foundation of nodejs,...
