

This article will talk about the various I/O models in Node, and introduce the soul of Node—non-blocking asynchronous IO. I hope it will be helpful to everyone!

[Related tutorial recommendations: nodejs video tutorial, programming teaching】
We request IO through the network For example, first introduce the typical process of the server processing a complete network IO request:
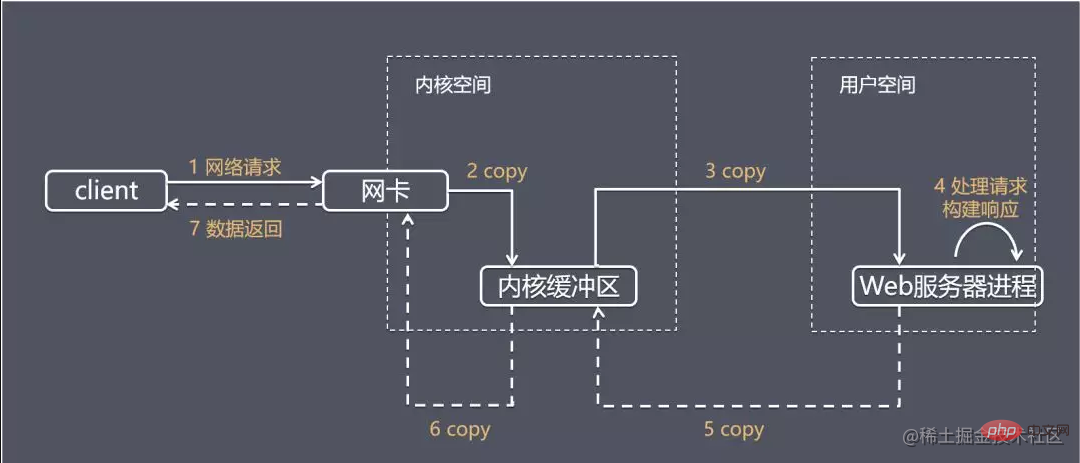
The application obtains an operation result, which usually includes two different stages:
Waiting for the data to be ready
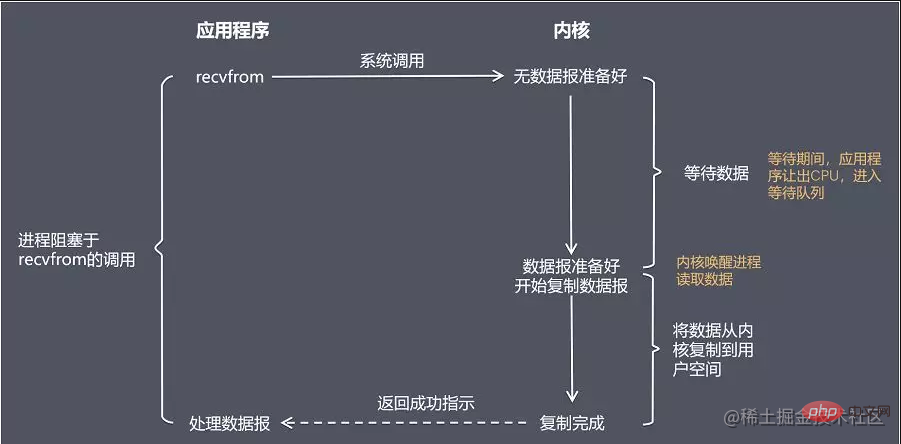
Below, we use the recvfrom function For example, explain various IO models
Blocking call means that before the call result is returned, the current thread will be suspended, and the calling thread will only end after waiting for the system kernel level all operations to be completed.
Blocking I/O causes the CPU to wait for I/O and wastes CPU time slices.
Compared with the former, non-blocking I/O Return directly without data. To obtain the data, you need to try to read the data again through the file descriptor

Non-Blocking callGet returned ( Not the actual expected data), the CPU time slice can be used to process other things, which can significantly improve performance.
But the problem that comes with it is that the previous operation was not a complete I/O, and the returned result was not the expected business data, but only the asynchronous call status.
In order to obtain complete data, the application needs to repeatedly call the IO operation to confirm whether the operation has been completed. This operation is called Polling. Several common polling strategies are as follows
This is the most primitive and lowest performance way. It checks the I/O status through repeated calls to obtain complete data

Advantages: Simple programming
Disadvantages: The CPU is always consumed in polling, which also affects server performance, because the server still needs to respond after you poll.

In the I/O multiplexing model, it will be used Select or Poll function or Epoll function (supported by the kernel after Linux 2.6), these two functions will also cause the process to block, but they are different from blocking I/O.
These three functions can block multiple I/O operations at the same time, and can detect the I/O functions of multiple read operations and multiple write operations at the same time until there is data that can be read or written. , the I/O operation function is actually called.
The differences between the three I/O multiplexing mechanisms are as follows
select
Due to select A 1024-length array is used to store file status, so up to 1024 file descriptors can be detected simultaneously
poll
Slightly improved compared to select. The use of linked lists avoids the length limit of 1024 and avoids unnecessary traversal checks. The performance is slightly improved compared to select.
##epoll/ kqueue
sleep, until the event occurs and the thread is awakened. It truly utilizes event notifications and executes callbacks instead of traversing (file descriptor) queries, so it does not waste CPU

Summary: In essence, Polling is still a synchronous operation, because the application is still waiting for the I/O to return completely. During the waiting period, it either traverses the file description state or sleeps to wait for the event to occur. .

In the signal-driven I/O model In , the application uses signals to drive I/O and installs a signal processing function. The process continues to run without blocking.
When the data is ready, the program will receive a SIGIO signal and can call the I/O operation function in the signal processing function to process the data.
Summary: So far, the signal-driven I/O model is more in line with our asynchronous needs. The program will execute other business logic asynchronously while waiting for data.
but! ! ! It is still blocked during the process of copying data from the kernel to user space, which is not a complete revolution (asynchronous).
Our ideal asynchronous I/O should be a non-blocking call initiated by the application, without the need to obtain data through polling , there is no need to wait needlessly during the data copy phase, but after the I/O is completed, it can be passed to the application through a signal or callback function, during which the application can execute other business logic.

In fact, the Linux platform natively supports asynchronous I/O (AIO), but currently AIO is not perfect. , so when implementing high-concurrency network programming under Linux, the I/O multiplexing model is mainly used.
Under Windows, true asynchronous I/O is implemented through IOCP.
Under the Linux platform, Node uses the thread pool to allow some threads to perform blocking I/O or non-blocking I/O rounds Data acquisition is completed by querying, allowing a separate thread to perform calculations, and passing the I/O results through communication between threads, thus realizing the simulation of asynchronous I/O.
In fact, the bottom layer of the IOCP asynchronous asynchronous solution under the Windows platform is also implemented using a thread pool. The difference is that the latter thread pool is hosted by the system kernel.
We often say that Node is single-threaded, but in fact it can only be said that JS is executed in a single thread, whether it is *nix or windows platform , the bottom layer uses the thread pool to complete I/O operations.
For more node-related knowledge, please visit: nodejs tutorial!
The above is the detailed content of Take you to understand non-blocking asynchronous IO in Nodejs. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



