

Threads and processes are the basic concepts of computer operating systems and are high-frequency words among programmers. How to understand them? What about processes and threads in Node.js? The following article will give you an in-depth understanding of the processes and threads in Node. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.

The above description is relatively difficult. You may not understand it after reading it, and it is not conducive to understanding and memory. So let’s take a simple example:
Suppose you are a guy at a certain express delivery site. At first, the area that this site is responsible for does not have many residents, and you are the only one who collects the packages. After delivering the package to Zhang San's house, and then going to Li Si's house to pick it up, things have to be done one by one. This is called single thread, and all the work must be performed in order .
Later, there were more residents in this area, and the site assigned multiple brothers and a team leader to this area. You can serve more residents. This is called multi-threading, team leader It's the main thread, and every guy is a thread.
The tools such as trolleys used by express delivery sites are provided by the site and can be used by everyone, not just for one person. This is called multi-threaded resource sharing.
There is currently only one site cart and everyone needs to use it. This is called conflict. There are many ways to solve it, such as waiting in line or waiting for notifications after other guys are finished. This is called thread synchronization.
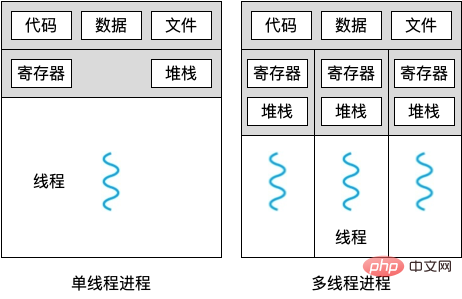
The head office has many sites, and the operating models of each site are almost exactly the same. This is called multi-process. The head office is called main process, and each site is called subprocess.
Between the head office and the site, as well as between each site, the carts are independent of each other and cannot be mixed. This is called No resource sharing between processes. Each site can communicate with each other through telephone and other methods, which is called pipeline. There are other means of collaboration between sites to facilitate the completion of larger computing tasks, which is called inter-process synchronization.
You can also take a look at Ruan Yifeng's A simple explanation of processes and threads.
Node.js is a single-threaded service, event-driven and non-blocking I/O model language features, making Node.js is efficient and lightweight. The advantage is that it avoids frequent thread switching and resource conflicts; it is good at I/O-intensive operations (the underlying module libuv calls the asynchronous I/O capabilities provided by the operating system through multi-threads to perform multi-tasking), but for Node.js on the server side , there may be hundreds of requests that need to be processed per second. When facing CPU-intensive requests, because it is a single-threaded mode, it will inevitably cause blocking.
We use Koa to simply build a Web service and use the Fibonacci sequence method to simulate the CPU-intensive processing of Node.js Type calculation tasks:
Fibonacci sequence, also known as the golden section sequence, this sequence starts from the third item, each item is equal to the sum of the previous two items: 0, 1, 1 , 2, 3, 5, 8, 13, 21,...
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})Execute node app.js Start the service, use Postman to send the request, you can see It turns out that 38 calculations took 617ms. In other words, because a CPU-intensive calculation task was performed, the Node.js main thread was blocked for more than 600 milliseconds. If more requests are processed at the same time, or the calculation task is more complex, then all requests after these requests will be delayed.

We will create a new axios.js to simulate sending multiple requests. At this time, change the number of fibo calculations in app.js to 43 to simulate more complex Computational tasks:
// axios.js
const axios = require('axios')
const start = Date.now()
const fn = (url) => {
axios.get(`http://127.0.0.1:9000/${ url }`).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
fn('test')
fn('fibo?num=43')
fn('test')
可以看到,当请求需要执行 CPU 密集型的计算任务时,后续的请求都被阻塞等待,这类请求一多,服务基本就阻塞卡死了。对于这种不足,Node.js 一直在弥补。
master-worker 模式是一种并行模式,核心思想是:系统有两个及以上的进程或线程协同工作时,master 负责接收和分配并整合任务,worker 负责处理任务。
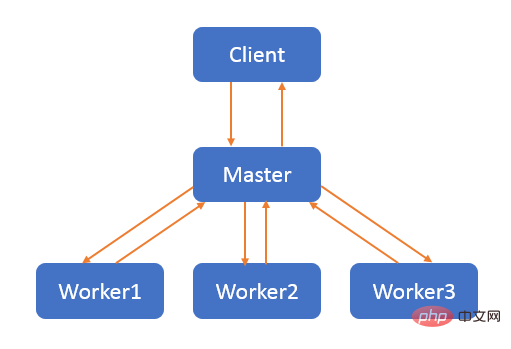
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。如果使用的是多核 CPU,那么将无法充分利用 CPU 的性能。
多线程带给我们灵活的编程方式,但是需要学习更多的 Api 知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会增加系统资源的开销。
worker_threads 是 Node.js 提供的一种多线程 Api。对于执行 CPU 密集型的计算任务很有用,对 I/O 密集型的操作帮助不大,因为 Node.js 内置的异步 I/O 操作比 worker_threads 更高效。worker_threads 中的 Worker,parentPort 主要用于子线程和主线程的消息交互。
将 app.js 稍微改动下,将 CPU 密集型的计算任务交给子线程计算:
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const { Worker } = require('worker_threads')
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', async (ctx) => {
const { num = 38 } = ctx.query
ctx.body = await asyncFibo(num)
})
const asyncFibo = (num) => {
return new Promise((resolve, reject) => {
// 创建 worker 线程并传递数据
const worker = new Worker('./fibo.js', { workerData: { num } })
// 主线程监听子线程发送的消息
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`))
})
})
}
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})新增 fibo.js 文件,用来处理复杂计算任务:
const { workerData, parentPort } = require('worker_threads')
const { num } = workerData
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
parentPort.postMessage({
pid: process.pid,
duration: Date.now() - start
})执行上文的 axios.js,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:

可以看到,将 CPU 密集型的计算任务交给子线程处理时,主线程不再被阻塞,只需等待子线程处理完成后,主线程接收子线程返回的结果即可,其他请求不再受影响。
上述代码是演示创建 worker 线程的过程和效果,实际开发中,请使用线程池来代替上述操作,因为频繁创建线程也会有资源的开销。
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。
我们再回味下,本小节开头提到的线程和 CPU 的描述,此时由于是新的线程,可以在其他 CPU 核心上执行,可以更充分的利用多核 CPU。
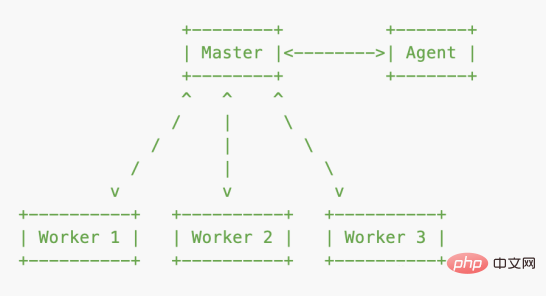
Node.js 为了能充分利用 CPU 的多核能力,提供了 cluster 模块,cluster 可以通过一个父进程管理多个子进程的方式来实现集群的功能。
cluster 底层就是 child_process,master 进程做总控,启动 1 个 agent 进程和 n 个 worker 进程,agent 进程处理一些公共事务,比如日志等;worker 进程使用建立的 IPC(Inter-Process Communication)通信通道和 master 进程通信,和 master 进程共享服务端口。
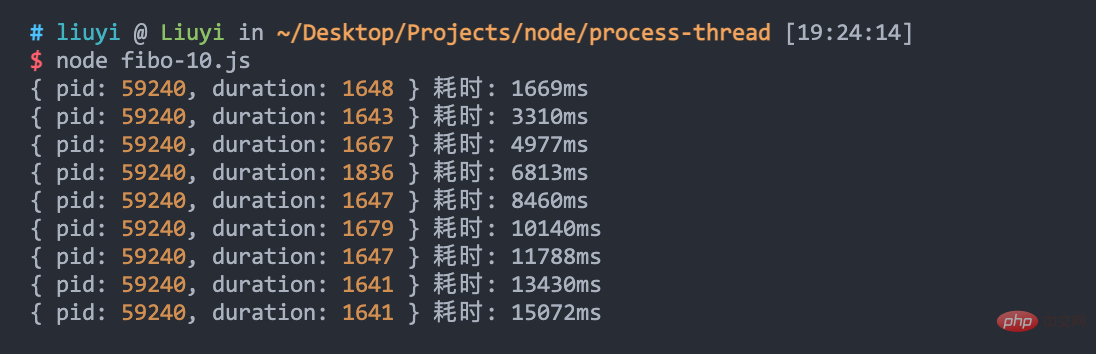
新增 fibo-10.js,模拟发送 10 次请求:
// fibo-10.js
const axios = require('axios')
const url = `http://127.0.0.1:9000/fibo?num=38`
const start = Date.now()
for (let i = 0; i {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}可以看到,只使用了一个进程,10 个请求慢慢阻塞,累计耗时 15 秒:
接下来,将 app.js 稍微改动下,引入 cluster 模块:
// app.js
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
// const numCPUs = 10 // worker 进程的数量一般和 CPU 核心数相同
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`)
// 衍生 worker 进程
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`)
})
} else {
app.listen(9000)
console.log(`Worker ${process.pid} started`)
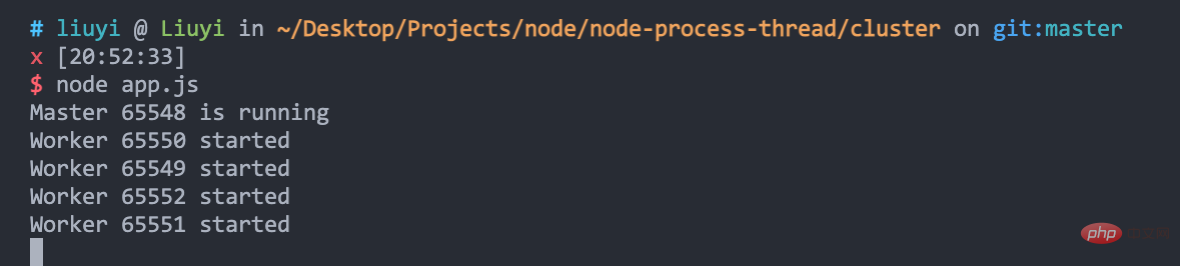
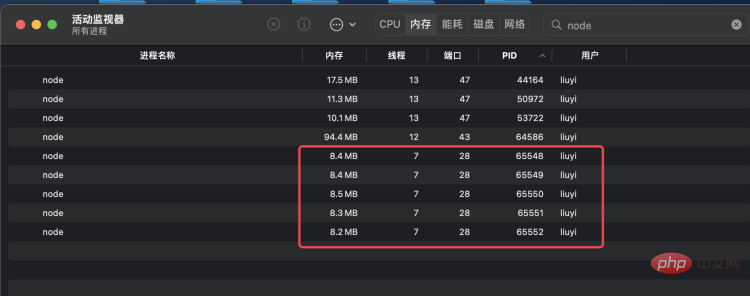
}执行 node app.js 启动服务,可以看到,cluster 帮我们创建了 1 个 master 进程和 4 个 worker 进程:
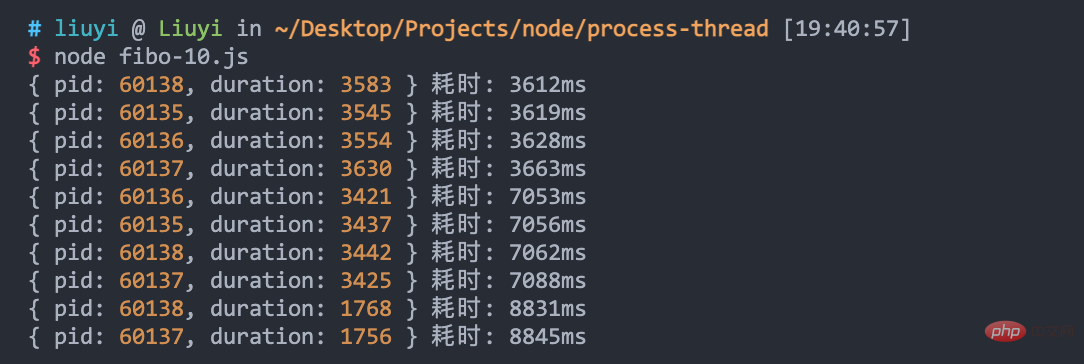
通过 fibo-10.js 模拟发送 10 次请求,可以看到,四个进程处理 10 个请求耗时近 9 秒:
When 10 worker processes are started, look at the effect:
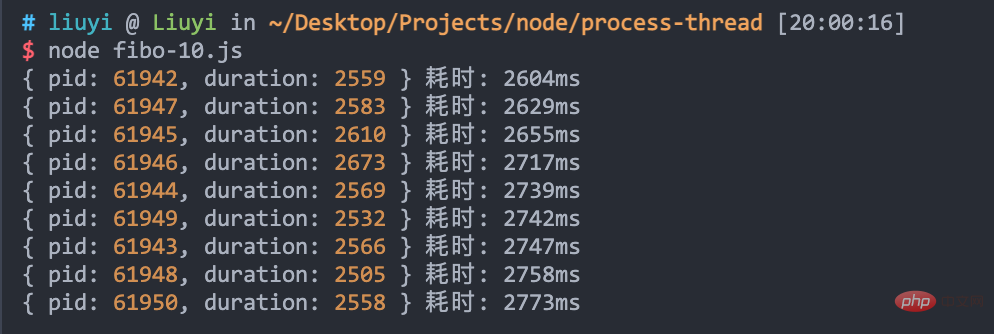
It only takes less than 3 seconds, but the number of processes is not unlimited. In daily development, the number of worker processes is generally the same as the number of CPU cores.
Enabling multi-process is not entirely to deal with high concurrency, but to solve the problem of insufficient multi-core CPU utilization of Node.js.
The child process derived from the parent process through the fork method has the same resources as the parent process, but they are independent and do not share resources with each other. The number of processes is usually set based on the number of CPU cores because system resources are limited.
1. Most solutions to CPU-intensive computing tasks through multi-threading can be replaced by multi-process solutions;
2. Although Node.js is asynchronous, it does not mean that it will not block. It is best not to process CPU-intensive tasks in the main thread to ensure the smooth flow of the main thread;
3. Don’t blindly pursue high performance and high concurrency, and meet system needs immediately However, efficiency and agility are what the project needs, which are also the lightweight characteristics of Node.js.
4. There are many concepts of processes and threads in Node.js that are mentioned in the article but are not discussed in detail or not mentioned, such as: Node.js underlying I/O libuv, IPC communication channel, etc. How to protect processes, how to handle scheduled tasks, agent processes, etc. if resources between processes are not shared;
5. The above code can be viewed at https://github.com/liuxy0551/node-process-thread.
For more node-related knowledge, please visit: nodejs tutorial!
The above is the detailed content of An in-depth analysis of processes and threads in Node. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



