

Take you to understand the database buffer pool (Buffer Pool) in MySQL


For tables using the InnoDB storage engine, storage space is managed in units of pages, as the basic granularity for swapping in and out between memory and disk. When we load a page from disk into memory, disk I/O will be performed. The overhead of disk I/O greatly affects the overall performance. If we read the corresponding page directly from the memory, wouldn't it reduce the performance loss caused by disk I/O and the efficiency will be improved a lot. Based on this, Buffer Pool (
Buffer Pool) appeared, so next, let’s talk about the Buffer Pool in InnoDB.
Buffer Pool
Some people may think that since the buffer pool is so good, why not just store all the data in the buffer pool? No, no, no , The buffer pool is a continuous piece of memory allocated by the operating system. Memory has a much smaller capacity than disk and is expensive. So how much memory will the operating system allocate to the buffer pool?
- By default, the size of the buffer pool is 128MB;
Of course, if your machine has a very large memory capacity, you can configure the startup option parameters in the configuration file innodb_buffer_pool_sizeThe unit is bytes, and the minimum cannot be less than 5MB.
The internal structure of the buffer pool
The buffer pool divides the continuous memory allocated by the operating system into several pages (buffer pages) with a default size of 16KB [At this time, there is no actual The disk page is cached in the Buffer Pool]. When we swap a page from the disk into the buffer pool, how do we allocate the location? Therefore, some control information is needed to identify the buffer pages in these buffer pools. This control information is stored in a memory area called a control block and corresponds to the buffer page one-to-one. The size of the control block is also fixed. Therefore, in this continuous memory space, memory fragmentation will inevitably occur. In summary, the internal structure of the buffer pool is as follows:
- Buffer page
- Control block: page number, address of the buffer page in the buffer pool, linked list node information, etc.
- Memory fragmentation [If memory is allocated properly, memory fragmentation is dispensable]
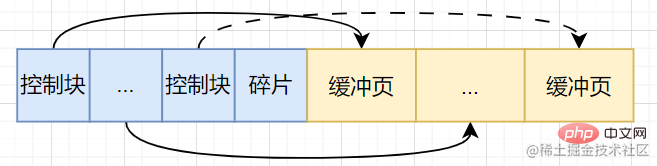
Buffer pool management
Above The linked list node information is mentioned in the control block, so what are the linked list nodes used for? It is to better manage the pages in the buffer pool. The linked list is used to link control blocks, because there is a one-to-one correspondence between control blocks and buffer pages.
1) Free linked list
Links the control blocks corresponding to all free buffer pages to form a linked list.
Solution to the problem: When swapping a page from the disk into the buffer pool, how to distinguish which page in the buffer pool is free? With the free linked list, when a disk page is swapped into the buffer pool, a free buffer page is obtained directly from the free linked list, and the corresponding information in the disk page is filled in the control block corresponding to the buffer page, and then Just delete the control block from the free linked list.
2) Update linked list
If the data of the buffer page in the buffer pool is modified, causing it to be inconsistent with the data on the disk, the page is called a dirty page. Link the control blocks corresponding to all dirty pages to form an update linked list, and refresh the data of the corresponding cache page to the disk at a certain time in the future based on this linked list.
3) LRU linked list
The size of the buffer pool is limited. If the cached pages exceed the size of the buffer pool, that is, there are no free buffer pages. When there are new pages to be added, When entering the buffer pool, the LRU strategy is adopted to remove old buffer pages from the buffer pool, and then add new pages. Since the LRU linked list involves a lot of content, we will introduce it separately next.
The "philosophy" contained in the LRU linked list
Let me first mention the pre-reading mechanism
The optimization mechanism on I/O. As the name suggests, pre-reading will asynchronously These pages are loaded into the buffer pool and are expected to be needed soon. These requests introduce all pages in a range, which is the so-called locality principle. The purpose is to reduce the disk I/O.
Before understanding the read-ahead mechanism, let’s review the InnoDB logical storage unit: tablespace → segment → extent → page. Specifically mention the area, which will be used later: an area is a continuous 64 pages in physical location, that is, the size of an area is 1MB.
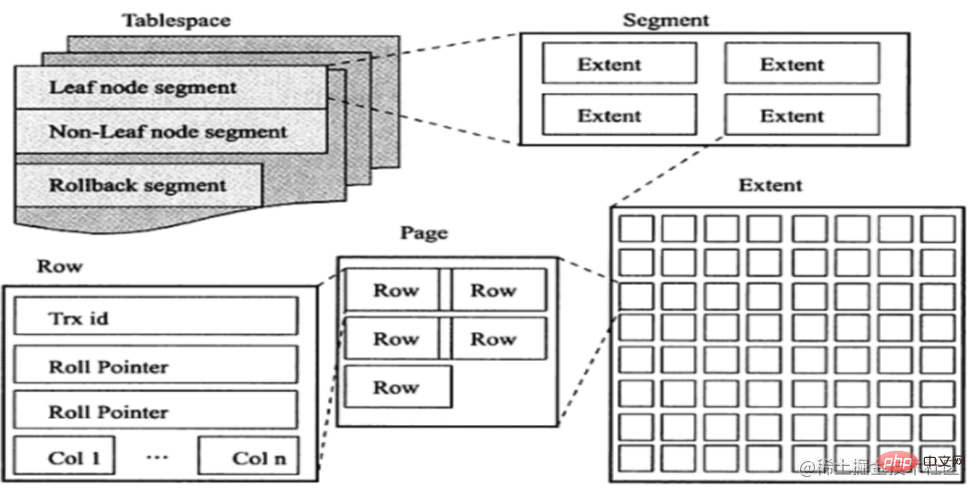
The pre-reading mechanism can be subdivided into the following two types:
- Linear read-ahead: A technique that predicts which pages may be needed soon based on sequentially accessed pages in the buffer pool. By configuring the parameter innodb_read_ahead_threshold, if the pages of a certain area accessed sequentially exceed the value of this parameter, an asynchronous read request will be triggered to read all the pages in the next area into the buffer pool.
- Random read-ahead: Can predict when pages may be needed based on pages already in the buffer pool, regardless of the order in which those pages are read. If 13 consecutive pages of the same extent are found in the buffer pool, InnoDB will asynchronously issue a request to prefetch the remaining pages of the extent. Random reading is controlled by configuring the variable innodb_random_read_ahead. How does traditional LRU manage buffer pages?
Use the LRU algorithm to manage the least recently used buffer pages and form a corresponding linked list for easy elimination.
When a page is accessed [that is, the most recent access]
The page is in the buffer pool, the corresponding control block is moved to the head of the LRU linked list- The page is not in the buffer pool In the buffer pool, the least recently used page at the end is eliminated, the page is loaded from the disk and placed at the head of the LRU linked list
- So why doesn't InnoDB use such an intuitive LRU algorithm? The reasons are as follows:
- Read ahead failure
The pages read ahead into the buffer pool will be placed at the head of the LRU linked list, but many of them The page may not be read.
- Buffer pool pollution
Loading many pages with low frequency into the buffer pool will remove pages with high frequency from the buffer Eliminated from the pool. For example,
full table scan How does the optimized LRU manage buffer pages?
Based on the above shortcomings, the specific optimized method divides the traditional LRU linked list into two parts: hot data area [young area] & cold data area [old area]
- Hot data area [Young area]
- : Buffer page with high frequency of use Cold data area [Old area]
- : Area with low use frequency
As shown in the figure, the hot data area and the cold data area occupy different proportions respectively, then we can start it through
innodb_old_blocks_pct option to control the proportion of cold data area.
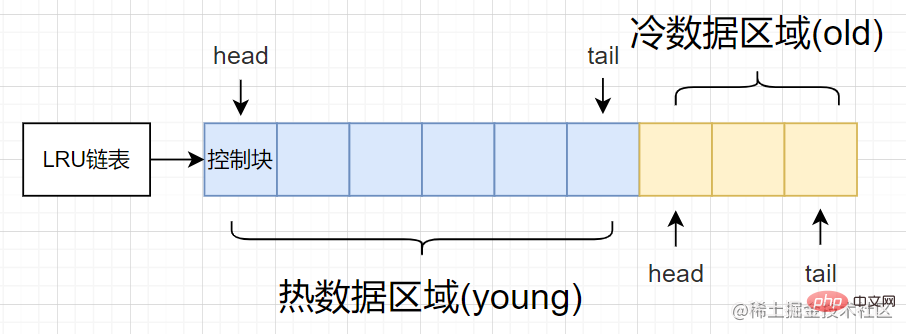
When a page is loaded into the buffer pool for the first time, the control block at the end of the cold data area is first eliminated (that is, its corresponding page is eliminated), and then the control block corresponding to the new page is eliminated. Blocks will be placed at the head of the cold data area first.
- If the page is not accessed subsequently, it will be slowly eliminated from the cold data area. Generally, it will not affect the frequently accessed buffer pages in the hot data area.
Let me talk about the conclusion first. This problem has not been well optimized. The reasons are as follows [take full table scan as an example]:
A page visited for the first time will also be Put it at the head of the cold data area, but subsequent access will put it at the head of the hot data area, which will also crowd out pages with higher access frequency.- So how to solve the problem of buffer pool pollution?
- Similarly, the window value can be set through the innodb_old_blocks_time
- parameter [unit ms]. The default is 1000ms, and 1s will filter out most operations such as full table scans. For example, during a full table scan, the time interval between multiple accesses to a page will not exceed 1 second.
The buffer pool will try to save frequently used data. When MySQL performs a page read operation, it will first determine whether the page is in the buffer pool. If it exists, it will be directly Read, if it does not exist, the page will be stored in the buffer pool through memory or disk and then read.
- Query caching is to cache the query results in advance, so that you can get the results directly without executing them next time. It should be noted that the query cache in MySQL does not cache the query plan, but the corresponding results of the query. The hit conditions are strict, and as long as the data table changes, the query cache will become invalid, so the hit rate is low.
- [Related recommendations:
The above is the detailed content of Take you to understand the database buffer pool (Buffer Pool) in MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
Recovering deleted rows directly from the database is usually impossible unless there is a backup or transaction rollback mechanism. Key point: Transaction rollback: Execute ROLLBACK before the transaction is committed to recover data. Backup: Regular backup of the database can be used to quickly restore data. Database snapshot: You can create a read-only copy of the database and restore the data after the data is deleted accidentally. Use DELETE statement with caution: Check the conditions carefully to avoid accidentally deleting data. Use the WHERE clause: explicitly specify the data to be deleted. Use the test environment: Test before performing a DELETE operation.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
