
 Operation and Maintenance
Linux Operation and Maintenance
What is compilation and installation in linux
Operation and Maintenance
Linux Operation and Maintenance
What is compilation and installation in linux
What is compilation and installation in linux

In Linux, compilation and installation refers to turning the source code into a machine executable code file based on the machine's own hardware, kernel, and environment, and then installing the executable file into the operating system. Because it is compiled for the local software and hardware environment, the generated binary program theoretically has better performance and saves resources when running.

#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
What is compilation and installation
Compilation: Turn the source code into a machine executable code file.
Installation: Install the executable file into the operating system before it can be used.
Compiling and installing means using the source code, compiling it according to the machine's own hardware, kernel, and environment, and generating a binary file. The advantage is that no matter what the machine is, as long as it has a complete compilation environment (basically All Linux distributions on the Internet have their own complete set of compilation environments), and you can generate binary packages suitable for your own machines. At the same time, because they are compiled for the local software and hardware environment, the generated binary programs theoretically have better performance when running. Well, it saves resources.
Disadvantages: The compilation process is cumbersome for novices (of course, it is also very fast if you are familiar with it), and upgrading is cumbersome (of course, some programs will resolve the upgrade themselves during the compilation and installation process) Conflict and coverage)
#Note:
To run the source code, it must first be converted into binary machine code. This is the compiler's job.
For example, the following source code (assuming the file name is test.c).
#include <stdio.h>
int main(void)
{
fputs("Hello, world!\n", stdout);
return 0;
}</stdio.h>It needs to be processed by the compiler before it can be run.
$ gcc test.c $ ./a.out Hello, world!
For complex projects, the compilation process must be divided into three steps.
$ ./configure $ make $ make install
Compilation process flow chart:
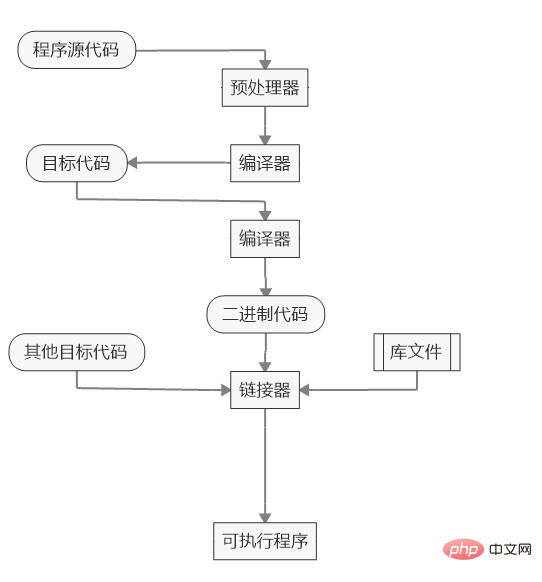
The specific process of compilation
1. Configuration ( configure)
Before the compiler starts working, it needs to know the current system environment, such as where the standard library is, where the software is installed, what components need to be installed, etc. This is because the system environments of different computers are different. By specifying compilation parameters, the compiler can flexibly adapt to the environment and compile machine code that can run in various environments. This step of determining compilation parameters is called "configure".
These configuration information are stored in a configuration file, which by convention is a script file called configure. Usually it is generated by the autoconf tool. The compiler learns the compilation parameters by running this script.
The configure script has tried its best to take into account the differences between different systems and gives default values for various compilation parameters. If the user's system environment is special or has some specific requirements, he or she needs to manually provide compilation parameters to the configure script.
$ ./configure --prefix=/www --with-mysql
The above code is a compilation configuration of PHP source code. The user-specified installation file is saved in the www directory, and support for the mysql module is added during compilation.
2. Determine the location of the standard library and header files
The source code will definitely use the standard library functions (standard library) and header files (header). They can be stored in any directory on the system. There is actually no way for the compiler to automatically detect their location. It can only be known through the configuration file.
The second step in compilation is to know the location of the standard library and header files from the configuration file. Generally speaking, the configuration file will give a list of several specific directories. When compiling, the compiler will go to these directories in order to find the target.
3. Determine dependencies
For large projects, there are often dependencies between source code files, and the compiler needs to determine the order of compilation. Assuming that file A depends on file B, the compiler should ensure the following two points.
(1)只有在B文件编译完成后,才开始编译A文件。 (2)当B文件发生变化时,A文件会被重新编译。
The compilation order is saved in a file called makefile, which lists which file is compiled first and which file is compiled later. The makefile file is generated by running the configure script, which is why configure must be run first during compilation.
While determining the dependencies, the compiler also determines which header files will be used during compilation.
4. Precompilation of header files
Different source code files may reference the same header file (such as stdio.h). When compiling, the header files must also be compiled together. To save time, the compiler will compile the header files before compiling the source code. This ensures that the header file only needs to be compiled once and does not need to be recompiled every time it is used.
However, not all the contents of the header file will be precompiled. The #define command used to declare macros will not be precompiled.
5. 预处理(Preprocessing)
预编译完成后,编译器就开始替换掉源码中bash的头文件和宏。以本文开头的那段源码为例,它包含头文件stdio.h,替换后的样子如下。
extern int fputs(const char *, FILE *);
extern FILE *stdout;
int main(void)
{
fputs("Hello, world!\n", stdout);
return 0;
}为了便于阅读,上面代码只截取了头文件中与源码相关的那部分,即fputs和FILE的声明,省略了stdio.h的其他部分(因为它们非常长)。另外,上面代码的头文件没有经过预编译,而实际上,插入源码的是预编译后的结果。编译器在这一步还会移除注释。
这一步称为"预处理"(Preprocessing),因为完成之后,就要开始真正的处理了。
6. 编译(Compilation)
预处理之后,编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码。
下面是本文开头的那段源码转成的汇编码。
.file "test.c" .section .rodata .LC0: .string "Hello, world!\n" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movq stdout(%rip), %rax movq %rax, %rcx movl $14, %edx movl $1, %esi movl $.LC0, %edi call fwrite movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Debian 4.9.1-19) 4.9.1" .section .note.GNU-stack,"",@progbits
这种转码后的文件称为对象文件(object file)。
注:make (gcc), 其调用 gcc 执行编译的过程依赖于配置文件makefile
7. 连接(Linking)
对象文件还不能运行,必须进一步转成执行文件。如果你仔细看上一步的转码结果,会发现其中引用了stdout函数和fwrite函数。也就是说,程序要正常运行,除了上面的代码以外,还必须有stdout和fwrite这两个函数的代码,它们是由C语言的标准库提供的。
编译器的下一步工作,就是把外部函数的代码(通常是后缀名为.lib和.a的文件),添加到可执行文件中。这就叫做连接(linking)。这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking),后文会提到还有动态连接(dynamic linking)。
make命令的作用,就是从第四步头文件预编译开始,一直到做完这一步。
8. 安装(Installation)
上一步的连接是在内存中进行的,即编译器在内存中生成了可执行文件。下一步,必须将可执行文件保存到用户事先指定的安装目录。
表面上,这一步很简单,就是将可执行文件(连带相关的数据文件)拷贝过去就行了。但是实际上,这一步还必须完成创建目录、保存文件、设置权限等步骤。这整个的保存过程就称为"安装"(Installation)。
9. 操作系统连接
可执行文件安装后,必须以某种方式通知操作系统,让其知道可以使用这个程序了。比如,我们安装了一个文本阅读程序,往往希望双击txt文件,该程序就会自动运行。
这就要求在操作系统中,登记这个程序的元数据:文件名、文件描述、关联后缀名等等。Linux系统中,这些信息通常保存在/usr/share/applications目录下的.desktop文件中。另外,在Windows操作系统中,还需要在Start启动菜单中,建立一个快捷方式。
这些事情就叫做"操作系统连接"。make install命令,就用来完成"安装"和"操作系统连接"这两步。
10. 生成安装包
写到这里,源码编译的整个过程就基本完成了。但是只有很少一部分用户,愿意耐着性子,从头到尾做一遍这个过程。事实上,如果你只有源码可以交给用户,他们会认定你是一个不友好的家伙。大部分用户要的是一个二进制的可执行程序,立刻就能运行。这就要求开发者,将上一步生成的可执行文件,做成可以分发的安装包。
所以,编译器还必须有生成安装包的功能。通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包,交给用户。
11. 动态连接(Dynamic linking)
正常情况下,到这一步,程序已经可以运行了。至于运行期间(runtime)发生的事情,与编译器一概无关。但是,开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接)。所以,最后还要提一下,什么叫做动态连接。
前面已经说过,静态连接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,适用范围比较广,不用担心用户机器缺少某个库文件;缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。动态连接的做法正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件;缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行。
现实中,大部分软件采用动态连接,共享库文件。这种动态共享的库文件,Linux平台是后缀名为.so的文件,Windows平台是.dll文件,Mac平台是.dylib文件。
Linux编译安装的具体实现
1.编译安装源程序的前提:
1).提供开发环境:开发工具和开发库
2).编译安装需要的包组:
Development Tools、Server Platform Development、Desktop Platform Development、Debug Tools
2.configure脚本常用的选项:
--help获取./configure脚本帮助 --prefix=: 指定安装路径;多数程序都有默认安装路径; --sysconfidr=: 指定配置文件安装路径; --with-PACKAGE[=ARG]:在自由软件社区里,有使用已有软件包和库的优秀传统.当用'configure'来配置一个源码树时, 可以提供其他已经安装的软件包的信息 --without-PACKAGE:有时候你可能不想让你的软件包与系统已有的软件包交互。例如,你可能不想让你的新编译器使用 GNU ld --enable-FEATURE:一些软件包可能提供了一些默认被禁止的特性,可以使用'--enable-FEATURE'来起用它 --disable-EEATURE:关闭指定的默认特性
3.编译安装源程序方法:
1)、展开源代码,找INSTALL、README;不存在此类文件时,找项目官方文档;
2)、根据安装说明执行安装操作;
4.程序安装于专用目录时,安装后的配置:
1)、导出二进制程序所在路径至PATH环境中
# export PATH=/usr/local/nginx/sbin:$PATH 实现永久有效的办法: /etc/profile.d/*.sh
2)、导出库文件给OS
OS查找库文件方法:根据/etc/ld.so.conf配置文件指定的路径搜索,或搜索/lib, /lib64, /usr/lib, /usr/lib64,把查找到的所有的库文件路径和其名称映射关系保存为一个缓存文件/etc/ld.so.cache;
/etc/ld.so.conf配置文件有其它组成部分:/etc/ld.so.conf.d/*.conf
假设nginx安装于/usr/local/nginx,此目录中有其库文件子目录lib,导出此目录中库文件:
(1)新建文件/etc/ld.so.conf.d/nginx.conf,在文件添加如下行:
/usr/local/nginx/lib
(2)运行命令:ldconfig
ldconfig的主要用途:
默认搜寻/lilb和/usr/lib,以及配置文件/etc/ld.so.conf内所列的目录下的库文件。
搜索出可共享的动态链接库,库文件的格式为:lib***.so.**,进而创建出动态装入程序(ld.so)所需的连接和缓存文件。
缓存文件默认为/etc/ld.so.cache,该文件保存已排好序的动态链接库名字列表。
ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库时,就需要手工运行这个命令。
常用选项:
-v: 用此选项时,ldconfig将显示正在扫描的目录及搜索到的动态链接库,还有它所创建的连接的名字. -p: 显示当前OS已经加载到的所有库文件名称及其文件所在路径的映射关系;
ldconfig需要注意的地方:
(a)、往/lib和/usr/lib里面加东西,是不用修改/etc/ld.so.conf文件的,但是添加完后需要调用下ldconfig,不然添加的library会找不到。
(b)、如果添加的library不在/lib和/usr/lib里面的话,就一定要修改/etc/ld.so.conf文件,往该文件追加library所在的路径,然后也需要重新调用下ldconfig命令。比如在安装mysql的时候,其库文件/usr/local/mysql/lib,就需要追加到/etc/ld.so.conf文件中。命令如下:
# echo "/usr/local/mysql/lib" >> /etc/ld.so.conf # ldconfig -v | grep mysql
(c)、如果添加的library不在/lib或/usr/lib下,但是却没有权限操作写/etc/ld.so.conf文件的话,这时就需要往export里写一个全局变量LD_LIBRARY_PATH,就可以了。
(3)、帮助文件导出
man命令搜索特定路径查找手册页文件,这些路径是定义在/etc/man.config中的MANPATH参数所指定的路径下的;
新增办法:编辑/etc/man.config文件,新增一个MANPATH参数,其值为新安装程序的man手册所在的目录;
/usr/local/nginx/share/man/{man1,man8}
man -M /path/to/man KEYWORD(4)、头文件导出
有些程序安装后会生成对自己拥有库文件调用接口相关头文件系统查找头文件的路径为/usr/include
导出独立安装应用程序的头文件方法:创建链接至/usr/include下即可;
例如:
/usr/local/nginx/include # ln -sv /usr/local/nginx/include/* /usr/include/ # ln -sv /usr/local/nginx/include /usr/include/nginx
perl源程序的编译安装方法:
(1) perl Makefile.in (2) make (3) make install
相关推荐:《Linux视频教程》
The above is the detailed content of What is compilation and installation in linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
deepseek web version entrance deepseek official website entrance
Feb 19, 2025 pm 04:54 PM
DeepSeek is a powerful intelligent search and analysis tool that provides two access methods: web version and official website. The web version is convenient and efficient, and can be used without installation; the official website provides comprehensive product information, download resources and support services. Whether individuals or corporate users, they can easily obtain and analyze massive data through DeepSeek to improve work efficiency, assist decision-making and promote innovation.
 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet official website installation (2025 beginner's guide)
Feb 21, 2025 pm 08:42 PM
BITGet is a cryptocurrency exchange that provides a variety of trading services including spot trading, contract trading and derivatives. Founded in 2018, the exchange is headquartered in Singapore and is committed to providing users with a safe and reliable trading platform. BITGet offers a variety of trading pairs, including BTC/USDT, ETH/USDT and XRP/USDT. Additionally, the exchange has a reputation for security and liquidity and offers a variety of features such as premium order types, leveraged trading and 24/7 customer support.
 Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi okx installation package is directly included
Feb 21, 2025 pm 08:00 PM
Ouyi OKX, the world's leading digital asset exchange, has now launched an official installation package to provide a safe and convenient trading experience. The OKX installation package of Ouyi does not need to be accessed through a browser. It can directly install independent applications on the device, creating a stable and efficient trading platform for users. The installation process is simple and easy to understand. Users only need to download the latest version of the installation package and follow the prompts to complete the installation step by step.
 Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Get the gate.io installation package for free
Feb 21, 2025 pm 08:21 PM
Gate.io is a popular cryptocurrency exchange that users can use by downloading its installation package and installing it on their devices. The steps to obtain the installation package are as follows: Visit the official website of Gate.io, click "Download", select the corresponding operating system (Windows, Mac or Linux), and download the installation package to your computer. It is recommended to temporarily disable antivirus software or firewall during installation to ensure smooth installation. After completion, the user needs to create a Gate.io account to start using it.
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, also known as OKX, is a world-leading cryptocurrency trading platform. The article provides a download portal for Ouyi's official installation package, which facilitates users to install Ouyi client on different devices. This installation package supports Windows, Mac, Android and iOS systems. Users can choose the corresponding version to download according to their device type. After the installation is completed, users can register or log in to the Ouyi account, start trading cryptocurrencies and enjoy other services provided by the platform.
 gate.io official website registration installation package link
Feb 21, 2025 pm 08:15 PM
gate.io official website registration installation package link
Feb 21, 2025 pm 08:15 PM
Gate.io is a highly acclaimed cryptocurrency trading platform known for its extensive token selection, low transaction fees and a user-friendly interface. With its advanced security features and excellent customer service, Gate.io provides traders with a reliable and convenient cryptocurrency trading environment. If you want to join Gate.io, please click the link provided to download the official registration installation package to start your cryptocurrency trading journey.
 How to Install phpMyAdmin with Nginx on Ubuntu?
Feb 07, 2025 am 11:12 AM
How to Install phpMyAdmin with Nginx on Ubuntu?
Feb 07, 2025 am 11:12 AM
This tutorial guides you through installing and configuring Nginx and phpMyAdmin on an Ubuntu system, potentially alongside an existing Apache server. We'll cover setting up Nginx, resolving potential port conflicts with Apache, installing MariaDB (
