

The char type occupies 1 byte in C or C and 2 bytes in java. char is used in C or C to define character variables, and the char data type is an integer type and only occupies 1 byte. In Java, the char type occupies 2 bytes because the Java compiler uses Unicode encoding by default, so 2 bytes (16 bits) can represent all characters.

The operating environment of this tutorial: Windows 7 system, Dell G3 computer.
I searched on Baidu for "how many bytes does char occupy" and got the following answer:

char is used for Character variables defined in C or C are an integer type, occupying only one byte, and the value range is -128 ~ 127 (-27 ~ 27-1).
The char type occupies 1 byte, which is 8 bits. The positive integers that can be stored are 0111 1111, which is 127.
Obviously this is not the result we want, so I continued to search for "how many bytes does char in java occupy"

Char in Java is used to store the data type of characters. It occupies 2 bytes and uses unicode encoding. Its first 128 bytes of encoding are compatible with ASCII, but some characters require two chars to represent them.
Why does char occupy the same number of bytes in C or C and java?
What does it mean that some characters require two chars to represent?
Encoding
Before discussing this issue, let us first popularize some knowledge points.
First of all, we all know that the information stored in the computer is represented by binary numbers, so how do we let the computer store the Chinese characters or English that we humans use?
For example, how to convert 'a' into binary and store it in the computer is called encoding;
And analyzing and displaying the binary number stored in the computer is called Decode for .
Character set
Character (Character) is a general term for various characters and symbols, including various national characters, punctuation marks, graphic symbols, Numbers etc. A character set (Character set) is a collection of multiple characters. There are many types of character sets, and each character set contains a different number of characters. Common character set names: ASCII character set, GB2312 character set, BIG5 character set, GB18030 character set , Unicode character set, etc. This is the explanation given by Baidu Encyclopedia. Anyway, a character set is a collection of characters. There are many types of character sets, and the number of characters in a character set is also different. In order for a computer to accurately process text in various character sets, character encoding is required so that the computer can recognize and store various text.
unicode
Its name is Unicode, also called Universal Code. The number of symbols is constantly increasing and has exceeded one million.
Before Unicode was created, there were hundreds of encoding systems. No encoding can contain enough characters. As can be seen from its name, it is an encoding of all symbols. Each symbol is given a unique encoding, so the garbled code problem caused by different encodings will disappear.
Most computers use ASCII (American Standard Code for Information Interchange), which is a 7-bit encoding scheme that represents all uppercase and lowercase letters, numbers, punctuation marks, and control characters. Unicode contains ASCII codes, and '\u0000' to '\u007F' correspond to all 128 ACSII characters.
I can’t help but feel that only those with strength can set standards. Unicode is just a symbol set. It only specifies the binary code of the symbol. It only provides the mapping between characters and numbers, but does not specify how this binary code should be stored. We know that the number of English letters is very small and can be represented by one byte, but the number of Chinese symbols in Unicode is very large, and one byte cannot be used at all. As a result, various implementation methods for unicode character storage appeared later, such as UTF-8, UTF-16, etc. UTF-8 is the most widely used Unicode implementation on the Internet.
Inner code and external code
We often say that char in java occupies several bytes, which should be the char in the internal code in java.
Internal code refers to the encoding method of char and string in memory when Java is running; external code is the character encoding used externally when the program interacts with the outside world, such as serialization technology. Foreign code can be understood as: as long as it is not an internal code, it is a foreign code. It should be noted that the encoding method in the object code file (executable file or class file) generated by source code compilation belongs to foreign code. The internal code in the JVM uses UTF16. The 16 in UTF-16 refers to the minimum unit of 16 bits, that is, two bytes are one unit. In the early days, UTF16 was encoded using a fixed-length 2-byte encoding. Two bytes can represent 65536 symbols (in fact, it can actually represent less than this), which was enough to represent all characters in Unicode at that time. However, with the increase of characters in Unicode, 2 bytes cannot represent all characters. UTF16 uses 2 bytes or 4 bytes to complete the encoding. To deal with this situation, Java uses a pair of char to represent characters that require 4 bytes, taking into account forward compatibility requirements. Therefore, char in Java takes up two bytes, but some characters require two chars to represent them. This explains why some characters require two chars to represent them.
In addition: Java's class file uses UTF8 to store characters, that is to say, the characters in the class occupy 1 to 6 bytes. During Java serialization, characters are also encoded in UTF8, accounting for 1 to 6 characters.
length()
Then here’s another question: What is the String.length() of a character in Java?
After reading the previous knowledge points, you can’t open your mouth anymore and answer 1... Write a demo and have a look: use tiger to test in the Year of the Tiger, tigerUTF represents the corresponding unicode encoding.
String tiger = "?"; String tigerUTF = "\uD83D\uDC05"; System.out.println(tigerUTF); System.out.println(tiger.length()); System.out.println(tiger.codePointCount(0,tiger.length()));
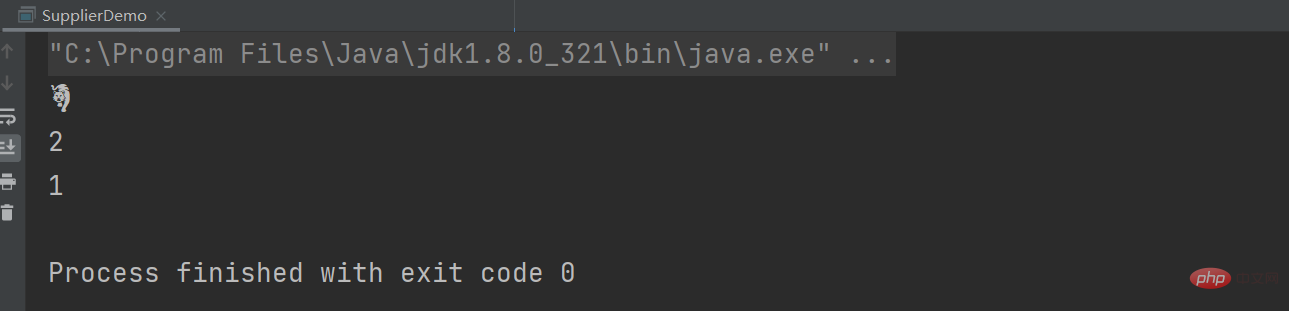
It can be concluded that the result of calling String.length() is 2, which means that the string char array occupies UTF- 2 code units (i.e. 4 bytes) of 16 format, not how many characters there are. Of course, we can use the codePointCount method to get how many characters we want to get.
For more related knowledge, please visit the FAQ column!
The above is the detailed content of How many bytes does the char type occupy?. For more information, please follow other related articles on the PHP Chinese website!










![HarmonyOS 2.0 application development practice [Hongmeng system APP development]](https://img.php.cn/upload/course/000/000/041/61c970d04644f402.jpg)

![Practical development of imitation Meituan APP [A must-have JavaScript project for front-end programmers]](https://img.php.cn/upload/course/000/000/068/6242bebc05ca9210.png)







![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



