

In Linux, disc refers to "disk", which is a block storage device, that is, a device used to store files; the file system is actually a mapping of disk space. In order to avoid storing or reading data in too large a space to reduce access efficiency, or to store and manage data in categories, there is a need to divide a disk space into multiple areas, which is the so-called disk partition.

#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
Disk (disc) is a block storage device used to store files. The file system is actually a mapping of disk space.
In the Linux system, the file system is created on the hard disk. Therefore, if you want to thoroughly understand the management mechanism of the file system, Let’s start by understanding the hard drive. Hard drives can be divided into mechanical hard drives (Hard Disk Drive, HDD) and solid state drives (Solid State Disk, SSD). Mechanical hard drives use magnetic platters to store data, while solid state drives use flash memory particles to store data.

Mechanical disk appearance
Disk structure diagram
Mechanical hard disk is mainly composed of disk, track, sector, head, cylinder and transmission shaft.
Disk: A disk generally has one or more platters. Each disk can have two sides, that is, the front side of the first disk is side 0 and the back side is side 1; the front side of the second disk is side 2...and so on.
Track: The surface of each disk is divided into multiple narrow concentric rings, and data is stored on such concentric rings. We call such rings tracks. Each disk can be divided into multiple tracks. The outermost track is track 0, and increasing toward the center of the circle is track 1, track 2... The data storage of the disk starts from the outermost circle.
Sectors: Depending on the specifications of the hard disk, the number of tracks can range from hundreds to thousands. Each track can store several kilobytes of data, but the computer doesn't have to read and write that much data every time. Therefore, each track is divided into several arc segments, and each arc segment is a sector. It has now become an industry convention that each sector can store 512 bytes of data. In other words, even if the computer only
needs a certain byte of data, it still has to read all 512 bytes of data into the memory and then select the required byte.
Magnetic head: It is a key component of the hard disk to read data. Its main function is to convert the magnetic information stored on the hard disk platter into electrical signals and transmit them outward. Its working principle uses special materials. The resistance value will read and write data on the disk according to the principle of magnetic field change. The quality of the magnetic head determines the storage density of the hard disk platter to a large extent. The more commonly used one is GMR (Giant Magneto Resistive) giant magnetoresistive head.
Modern hard disks use the CHS (Cylinder Head Sector) method for seeking. When the hard disk reads data, the read and write heads move along the Move radially to the top of the track where the sector to be read is located. This period of time is called seek time. Because the distance between the read and write head's starting position and the target position is different, the seek time is also different. Current hard drives generally take 2 to 30 milliseconds, with an average of about 9 milliseconds. After the magnetic head reaches the designated track, the sector to be read is moved under the read and write head through the rotation of the disk. This period of time is called rotational latency. A 7200 (revolutions per minute) hard disk , the time required for each rotation is 60×1000÷7200=8.33 milliseconds, then the average rotation delay time is 8.33÷2=4.17 milliseconds (on average, half a turn is required). The average seek time and the average optional delay are called the average access time.
Solid State Drive (SSD)
The biggest difference between SSD and traditional mechanical hard drive is that it no longer uses platters for data storage, but Use memory chips for data storage. There are two main types of storage chips for solid-state drives: one uses flash memory as the storage medium; the other uses DRAM as the storage medium. Currently, the most commonly used ones are solid-state drives that use flash memory as storage media
Solid-state drives and Mechanical hard drive comparison
IDE hard disk interface: (Integrated Drive Eectronics, parallel port, electronic integrated drive), also known as "ATA hard disk" or "PATA hard disk", is the main interface of early mechanical hard disks. The theoretical speed of ATA133 hard disk can reach 133MB/s (This speed is a theoretical average) Because the anti-interference performance of the parallel port cable is too poor, and the cable takes up a lot of space, which is not conducive to the internal heat dissipation of the computer, it has been gradually replaced by SATA.
SATA interface: The full name is Serial ATA, which is an ATA interface using a serial port. It is characterized by strong anti-interference, has much lower requirements for data lines than ATA, and supports hot swapping, etc. Function. The interface speed of SATA-II is 300MiB/s, while the new SATA-III standard can reach a transmission speed of 600MiB/s. SATA data cables are also much thinner than ATA, which is beneficial to air circulation in the chassis and makes it easier to organize the cables.
SCSI interface: The full name is Small Computer System Interface (small computer system interface). It has experienced multiple generations of development, from the early SCSI-II to the current Ultra320 SCSI and Fiber-Channel (fiber channel). The interface type Also diverse. SCSI hard drives are widely used in workstation-level personal computers and servers. Therefore, they use more advanced technologies, such as a high disk speed of 15,000 rpm, and the CPU usage is lower during data transmission. However, the unit price is also higher than that of ATA and SATA of the same capacity. Hard drives are more expensive.
SAS interface: The full name is Serial Attached SCSI. It is a new generation of SCSI technology that is compatible with SATA hard drives. They all use serial technology to obtain higher transmission speeds, which can reach 12Gb/s. In addition, the internal space of the system is improved by reducing the connection cables.
FC interface: The full name is Fiber Channel (Fibre Channel interface). Hard drives with this interface have the characteristics of hot-swappability, high-speed bandwidth (4Gb/s or 10Gb/s), remote connection, etc. when using optical fiber connections. ;The internal transfer rate is also higher than that of ordinary hard drives. But its price is high, so the FC interface is usually only used in the field of high-end servers
#Nowadays, most ordinary mechanical disk interfaces are SATA, and most solid-state disk interfaces are SAS
The file system is used by the operating system to identify storage devices (commonly disks, but also solid-state based on NAND Flash) Methods and data structures for files on a hard disk) or partition, that is, a method of organizing files on a storage device. The software organization responsible for managing and storing file information in the operating system is called a file management system, or file system for short. An interface to a file system, a collection of software for manipulation and management of objects, objects and attributes. From a system perspective, the file system is a system that organizes and allocates the space of file storage devices, is responsible for file storage, and protects and retrieves stored files. Specifically, it is responsible for creating files for users, storing, reading, modifying, and dumping files, controlling file access, and revoking files when users no longer use them. The file system is a part of the software system. Its existence allows applications to conveniently use abstract named data objects and variable-sized space. Manage and schedule the storage space of files, provide the logical structure, physical structure and storage method of files; realize the mapping of files from identification to actual addresses, realize the control operations and access operations of files, realize the sharing of file information and provide reliable files Confidentiality and Protection Measures Provide security measures for documents.
FAT:
Under Win 9X, the maximum partition supported by FAT16 is 2GB. We know that computers store information on the hard disk in areas called "clusters." The smaller the clusters used, the more efficiently information can be saved. In the case of FAT16, the larger the partition, the larger the cluster, and the lower the storage efficiency, which will inevitably cause a waste of storage space. And with the continuous improvement of computer hardware and applications, the FAT16 file system can no longer adapt well to system requirements. In this case, the enhanced file system FAT32 was introduced.
NTFS:
The NTFS file system is a security-based file system. It is a unique file system structure adopted by Windows NT. It is built to protect file and directory data. Basically, it is an advanced file system that saves storage resources and reduces disk usage. The widely used Windows NT 4.0 uses the NTFS 4.0 file system. I believe that the powerful system security it brings must have left a deep impression on the majority of users. Win 2000 uses an updated version of the NTFS file system NTFS 5.0. Its introduction allows users to not only operate and manage computers as conveniently and quickly as Win 9X, but also enjoy the system security brought by NTFS.
exFAT:
The full name is Extended File Allocation Table File System. Extended FAT is the extended file allocation table. It is Microsoft’s Windows Embeded 5.0 and above (including Windows CE 5.0, 6.0, Windows A file system suitable for flash memory introduced in Mobile 5, 6, 6.1), introduced to solve the problem that FAT32 and other files do not support 4G and larger files.
RAW:
The RAW file system is a file system produced by unprocessed or unformatted disks. Generally speaking, there are several possibilities that cause a normal file system to become a RAW file. System: There is no formatting, the formatting operation is canceled midway, bad sectors appear on the hard disk, unpredictable errors occur on the hard disk, or caused by viruses. The fastest way to solve the problem of RAW file system is to format it immediately and use anti-virus software to completely disinfect it
Ext:
Ext2:Ext is the standard file system in GNU/Linux system , which is characterized by excellent performance in accessing files, especially for small and medium-sized files, which is mainly due to the excellent design of its cluster cache layer.
Ext3: It is a log file system, an extension of the ext2 system, and it is compatible with ext2. The advantage of a journaled file system is that since the file system has a cache layer involved in its operation, the file system must be unmounted when not in use so that the data in the cache layer can be written back to the disk. Therefore, whenever the system wants to shut down, all its file systems must be shut down before shutting down
Ext4: The Linux kernel officially supports the new file system Ext4 since 2.6.28. Ext4 is an improved version of Ext3, which modifies some important data structures in Ext3, not just adding a logging function like Ext3 did to Ext2. Ext4 can provide better performance and reliability, as well as richer features.
It is especially obvious that files that may be damaged can be quickly restored, and the powerful log function only requires very low computing and storage performance. And its maximum supported storage capacity is 18EB, which almost meets all needs.
HFS:
Hierarchical File System (HFS) is a file system developed by Apple Computer and used on Mac OS. Originally designed for use with floppy disks and hard disks, it can also be found on read-only media such as CD-ROMs.
4. RAID redundant array of independent disks
Data striping saves data fragments on multiple different disks. Multiple data fragments together form a complete data copy. This is different from multiple copies of a mirror. It is usually used for performance considerations. Data striping has a higher concurrency granularity. When accessing data, data located on different disks can be read and written simultaneously, thereby obtaining a very considerable I/O performance improvement.
Data verification uses redundant data to detect and repair data errors. Redundant data is usually calculated using algorithms such as Hamming codes and XOR operations. Using the verification function can greatly improve the reliability, robustness and fault tolerance of the disk array. However, data verification requires reading data from multiple places and performing calculations and comparisons, which will affect system performance. Different levels of RAID use one or more of the three technologies to obtain different data reliability, availability and I/O performance. As for what kind of RAID to design (or even a new level or type) or what mode of RAID to use, it is necessary to make a reasonable choice based on an in-depth understanding of the system requirements, and to make a compromise choice by comprehensively evaluating reliability, performance, and cost.
The main advantages of RAID are as follows:
The high performance of RAID benefits from data striping technology. The I/O performance of a single disk is limited by computer technology such as interface and bandwidth. The performance is often very limited and can easily become a bottleneck for system performance. Through data striping, RAID spreads data I/O across member disks, resulting in aggregate I/O performance that is exponentially greater than a single disk.
(3) Reliability
Availability and reliability are another important characteristics of RAID. In theory, a RAID system consisting of multiple disks should be less reliable than a single disk. There is an implicit assumption here: a single disk failure will render the entire RAID unavailable. RAID breaks this assumption by using data redundancy technologies such as mirroring and data parity. Mirroring is the most primitive redundancy technology. It completely copies the data on a certain set of disk drives to another set of disk drives to ensure that a copy of the data is always available. Compared with the 50% redundancy overhead of mirroring, data verification is much smaller. It uses verification redundant information to verify and correct data. RAID redundancy technology greatly improves data availability and reliability, ensuring that when several disk errors occur, data will not be lost and the continuous operation of the system will not be affected.
(4) Manageability
In fact, RAID is a virtualization technology that virtualizes multiple physical disk drives into a large-capacity logical drive. RAID is a single, fast and reliable large-capacity disk drive for an external host system. In this way, users can organize and store application system data on this virtual drive. From the perspective of user applications, the storage system can be made simple and easy to use, and management is also very convenient. Since RAID does a lot of storage management work internally, administrators only need to manage a single virtual drive, saving a lot of management work. RAID can dynamically add or remove disk drives, and can automatically perform data verification and data reconstruction, which can greatly simplify management work.
RAID0
RAID1
RAID3
RAID5
RAID6
RAID10
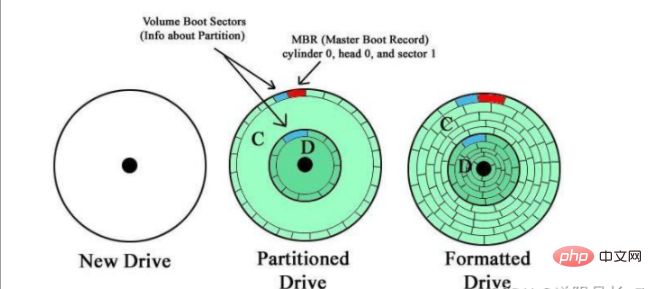
##MBR partition (also known as msdos partition, traditional)


 ##A cluster or logical block can correspond to a sector or a group of sectors, and is a logical single
##A cluster or logical block can correspond to a sector or a group of sectors, and is a logical single
The above is the detailed content of what is linux disc. For more information, please follow other related articles on the PHP Chinese website!









![[Introduction to beginners, easy to understand] Learn Linux in one week](https://img.php.cn/upload/course/000/000/068/6242a86a890b1568.png)


![Linux operation and maintenance basic course [detailed explanation of the whole process]](https://img.php.cn/upload/course/000/000/068/63ff173c79edd672.jpg)






![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



