

Quickly understand the Vue2 diff algorithm (detailed graphic explanation)

The diff algorithm is an efficient algorithm that compares tree nodes at the same level, avoiding the need to search and traverse the tree layer by layer. So how much do you know about the diff algorithm? The following article will give you an in-depth analysis of the diff algorithm of vue2. I hope it will be helpful to you!

I have been looking at the source code of Vue 2 for a long time. From using flow to now using TypeScript, I will open its source code and take a look every time, but every time I only saw the data initialization part, which is the stage of beforeMount, about how to generate VNode (Visual Dom Node, which can also be directly called vdom) and how to compare VNode (diff) when updating components ) has never been carefully studied. I only know that the double-ended diff algorithm is used. As for how this double-ended starts and ends, I have never seen it, so I took the opportunity to write an article to study it carefully this time. If the content is wrong, I hope you can help me point it out. Thank you very much~
What is diff?
In my understanding, diff refers to differences, that is, calculating the difference between old and new content; the diff algorithm in Vue quickly compares the old and new content through a simple and efficient method The difference between VNode node arrays is to update page content with minimal dom operations. [Related recommendations: vuejs video tutorial, web front-end development]
There are two necessary prerequisites here:
The comparison is the VNode array
There are two sets of old and new VNode arrays at the same time
So it generally only occurs when data updates Execute when the page content needs to be updated, that is, renderWatcher.run().
Why VNode?
As mentioned above, what is compared in diff is VNode, not the real dom node. I believe that why VNode is used? Most people compare It’s clear, let me just briefly explain it, right?~
There are roughly two reasons for using VNode in Vue:
VNode is designed as a framework designer according to the framework requirements. The JavaScript object itself has simpler properties than the real DOM node, and there is no need to perform DOM query during operation, which can greatly optimize the performance consumption during calculation
This link from VNode to the real DOM The rendering process can be processed differently according to different platforms (web, WeChat applet) to generate real dom elements adapted to each platform
During the diff process, the old and new node data will be traversed. In comparison, using VNode can bring great performance improvements.
Process sorting
In the web page, the real dom nodes exist in the form of tree, and the root nodes are all , in order to ensure that the virtual node is consistent with the real dom node, VNode also uses a tree structure.
If all VNode nodes need to be compared when the component is updated, both the old and new sets of nodes need to be deeply traversed and compared, which will cause a lot of performance overhead; therefore, by default in Vue Comparison of nodes at the same level, that is, if the levels of the old and new VNode trees are different, the content of the extra levels will be directly created or discarded, and only the diff operation will be performed at the same level.
Generally speaking, diff operations generally occur in v-for loops or v-if/v-else, component and the like. Dynamically generate node objects (static nodes generally do not change, and comparison is very fast), and this process is to update the dom, so in the source code, the method name corresponding to this process is updateChildren , located in src/core/vdom/patch.ts. As shown below:
Here is a review of the creation and update process of Vue component instances:
First of all
beforeCreateto thecreatedstage, mainly processing data and status as well as some basic events and methodsThen,
$mount(vm .$options.el)method enters the creation and mounting phase ofVnodeand dom, that is, betweenbeforeMountandmounted(when the component is updated Similar to here)The
$mounton the prototype will be rewritten inplatforms/web/runtime-with-compiler.ts, and the original implementation is inplatforms/web/runtime/index.ts; in the original implementation method, it actually calls themountComponentmethod to executerender; and inwebTheruntime-with-compilerbelow adds the template string compilation module, which will perform thetemplateinoptionsOnce parsed and compiled, converted into a function bound tooptions.render
mountComponentinside the function defines rendering MethodupdateComponent = () => (vm._update(vm._render()), instantiates awatcherinstance withbeforeconfiguration (i.e.renderWatcher), by defining thewatchobservation object as the just-definedupdateComponentmethod to perform the first component rendering and trigger dependency collection , wherebeforeThe configuration only configures the method to trigger thebeforeMount/beforeUpdatehook function; this is why the real dom node cannot be obtained in thebeforeMountstage and thebeforeUpdatestage The reason is that the old dom node
_updatemethod is defined in the same file asmountComponent, and its core is reading The$el(old dom node) and_vnode(old VNode) in the component instance are compared with thevnodegenerated by the_render()function.patchOperation
patchThe function first compares to see if it has an old node. If not, it must be a new one. Component, create and render directly; if there is an old node, compare the old and new nodes throughpatchVnode, And if the old and new nodes are consistent and both havechildrenchild nodes, Then enter the core logic ofdiff-updateChildrenChild node comparison update, this method is also what we often call thediffalgorithm
Preface content
Since we are comparing the old and new VNode arrays, there must first be a comparison judgment method: sameNode (a, b), method of adding nodesaddVnodes, method of removing nodesremoveVnodes, of course, even after sameNode determines that the VNode is consistent , patchVnode will still be used to deeply compare the contents of a single new and old VNode to confirm whether the internal data needs to be updated.
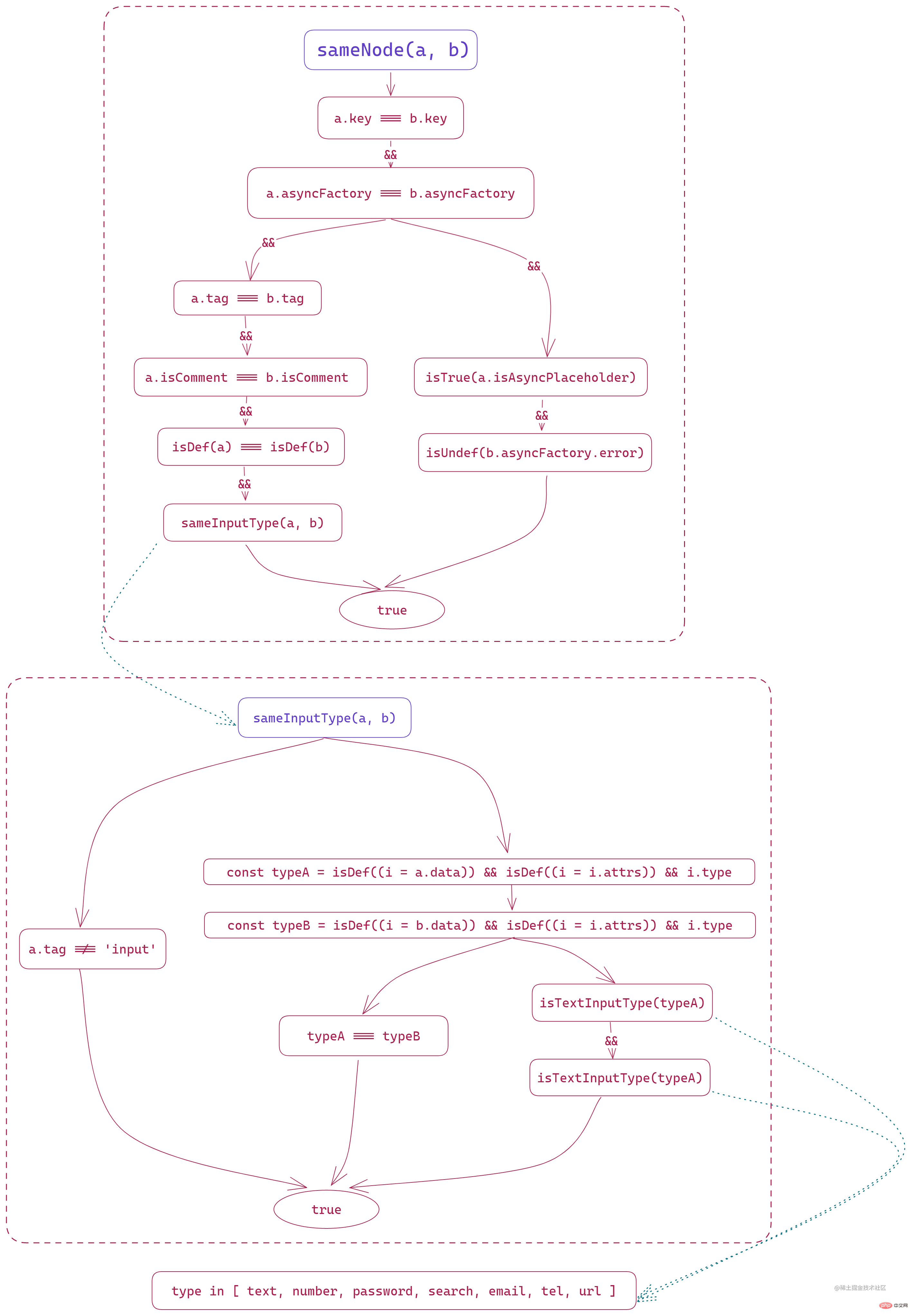
sameNode(a, b)
This method has one purpose: Compare whether the old and new nodes are the same.
In this method, the first thing to compare is whether the key of a and b are the same. This is why Vue notes v-for, v-if, Dynamic nodes such as v-else must set key to identify the uniqueness of the node. If key exists and is the same, you only need to compare whether the internal changes have occurred. Under normal circumstances It can reduce a lot of DOM operations; if it is not set, the corresponding node elements will be directly destroyed and rebuilt.
Then it will compare whether it is an asynchronous component, and here it will compare whether their constructors are consistent.
Then you will enter two different situations for comparison:
- Non-asynchronous component: the label is the same, both are not comment nodes, both have data, and the same type of text input box
- Asynchronous component: The error prompts of the old node placeholder and the new node are both
undefined
The overall process of the function is as follows
addVnodes
As the name suggests, add new VNode nodes.
This function receives 6 parameters: parentElm The parent element of the current node array, refElm The element at the specified position, vnodes New Virtual node array, startIdx The starting position of the inserted element of the new node array, endIdx The end index of the inserted element of the new node array, insertedVnodeQueue The virtual node that needs to be inserted Node queue.
The internal function will traverse the vnodes array starting from startIdx until the endIdx position , and then call createElm Create and insert the elements corresponding to vnodes[idx] before refElm in turn.
Of course, there may be Component components in this vnodes[idx], and createComponent will also be called to create the corresponding Component instance.
Because the entire
VNodeand dom are both a tree structure, so after comparison at the same level, it is necessary to process the deeper VNode under the current level. and dom processing.
removeVnodes
Contrary to addVnodes, this method is used to remove VNode nodes.
Since this method only removes, it only requires three parameters: vnodes Old virtual node array, startIdx Start index, endIdx End index.
The internal function will traverse the vnodes array starting from startIdx until the endIdx position , if vnodes[idx ] If it is not undefined, it will be processed according to the tag attribute:
- exists, indicating that it is An element or component needs to
recursively process the contents ofvnodes[idx], triggerremove hooks and destroy hooksdoes not existtag , indicating that it is a - plain text node
, you can directly remove the node from the dompatchVnode
The actual complete comparison and dom update
method of node comparison.In this method, it mainly contains nine
main parameter judgments, and corresponds to different processing logic:The old and new VNodes are congruent, It means there is no change,
- Exit directly
-
If the new VNode has real dom binding, and the node set that needs to be updated is an array, copy the current The VNode goes to the specified position of the collection
- If the old node is an asynchronous component and has not finished loading, exit
- directly, otherwise pass
hydrate The function converts the new VNode into a real dom for rendering; in both cases, exits the function
If the old and new nodes are both static nodes - and
key are equal, or if the node is not updated if isOnce
If the new VNode node has theis specified, the component instance of the old node will be directlyreusedandexit the function data - attribute and is configured with the
prepatch
If the new VNode has thehook function, executeprepatch(oldVnode, vnode)Notifies the node to enter the comparison phase. Generally, this step will configure performance optimizationdata - attribute and recursively changes the node's child If the vnode of the component instance is still available with labels, the
update
If the new VNode is not a text node, it will enter the core comparison phasehook function configured in thecbscallback function object and theupdate## configured indata#Hook function : -
If there are both old and new nodes children
child node, enter the- updateChildren
- method to compare child nodes
If the old node has no child nodes, directly create a new child node corresponding to the VNode - If there are no child nodes and the old node has text content configuration, clear the previous one text
- Text
text (it is a text node), compare the text content of the old and new nodes to see if they are consistent, otherwise proceed with the text content The update - method to compare child nodes
-
postpatchfinally calls the hook function configured in the - data
of the new node to notify the node that the update is complete
patchVnodeSimply put, is to compare the new content with the old content in the
. And The comparison and update of child node arrays is the core logic of diff, and it is also one of the questions often mentioned during interviews.
Next, let’s enter the analysis of the updateChildren method~
##updateChildren diff core analysis
First, let's think about itComparing the difference in elements of two object arrays based on the new arrayWhat are the methods?
Generally speaking, we can directly traverse two arraysthrough violent means to find the order and difference of each element in the array, which is simple diff algorithm
.That is, traverses the new node array, traverses the old node array again in each cycle to compare whether the two nodes are consistent, and determines whether the new node is added, removed or moved by comparing the results , The entire process requires m*n comparisons, so the default time complexity is On.
This comparison method is very performance consuming during a large number of node updates, so Vue 2 has optimized it and changed it to Double-ended comparison algorithm, which is Double-ended diff.
Double-ended diff algorithm
As the name suggests, Double-ended is starting from both ends and traversing to the middle for comparison algorithm.
In double-ended diff, there are five comparison situations:
The old and new headers are equal
The old and new tails are equal
The old head is equal to the new tail
The old tail is equal to the new head
The four are not equal to each other
Among them, the first four are ideal situations, while the fifth is The most complex comparison situation.
Judge equality, that is,
sameVnode(a, b)is equal totrue
Below we use a preset situation to Perform analysis.
1. Preset new and old node states
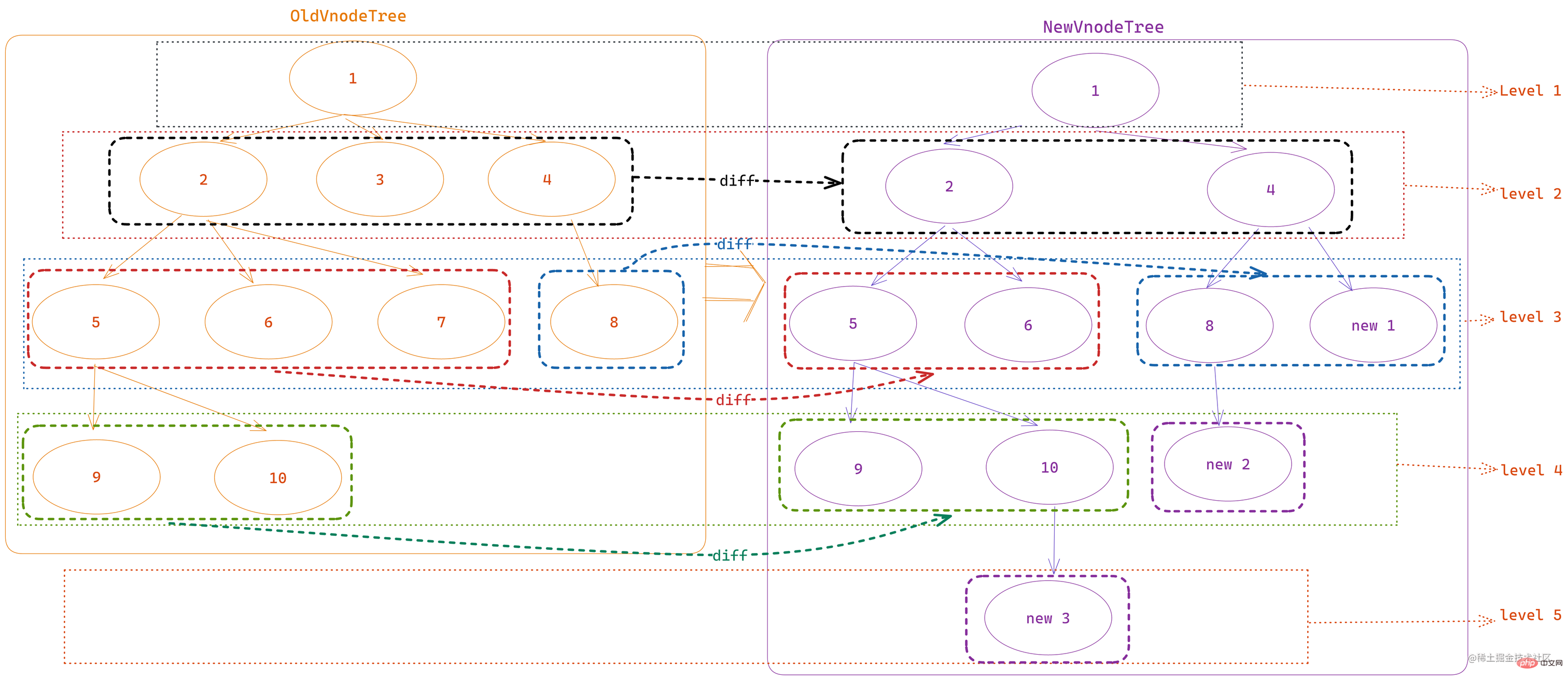
In order to try to demonstrate the above five situations at the same time, I preset the following new and old node arrays:
- As the old node array in initial node order
oldChildren, including a total of 7 nodes from 1 to 7 - As the new node array after disorder
newChildren, There are also 7 nodes, but compared to the old node, there is one lessvnode 3and one morevnode 8
Before comparing, you first need toDefine the double-ended index of two sets of nodes :
let oldStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newStartIdx = 0 let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx]
Copied source code, where
oldChisoldChildrenin the figure,newChisnewChildren
Then, we define the stop condition for the traversal comparison operation:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)
stop here The condition is As soon as either the traversal of the old or new node array ends, the traversal will stop immediately.
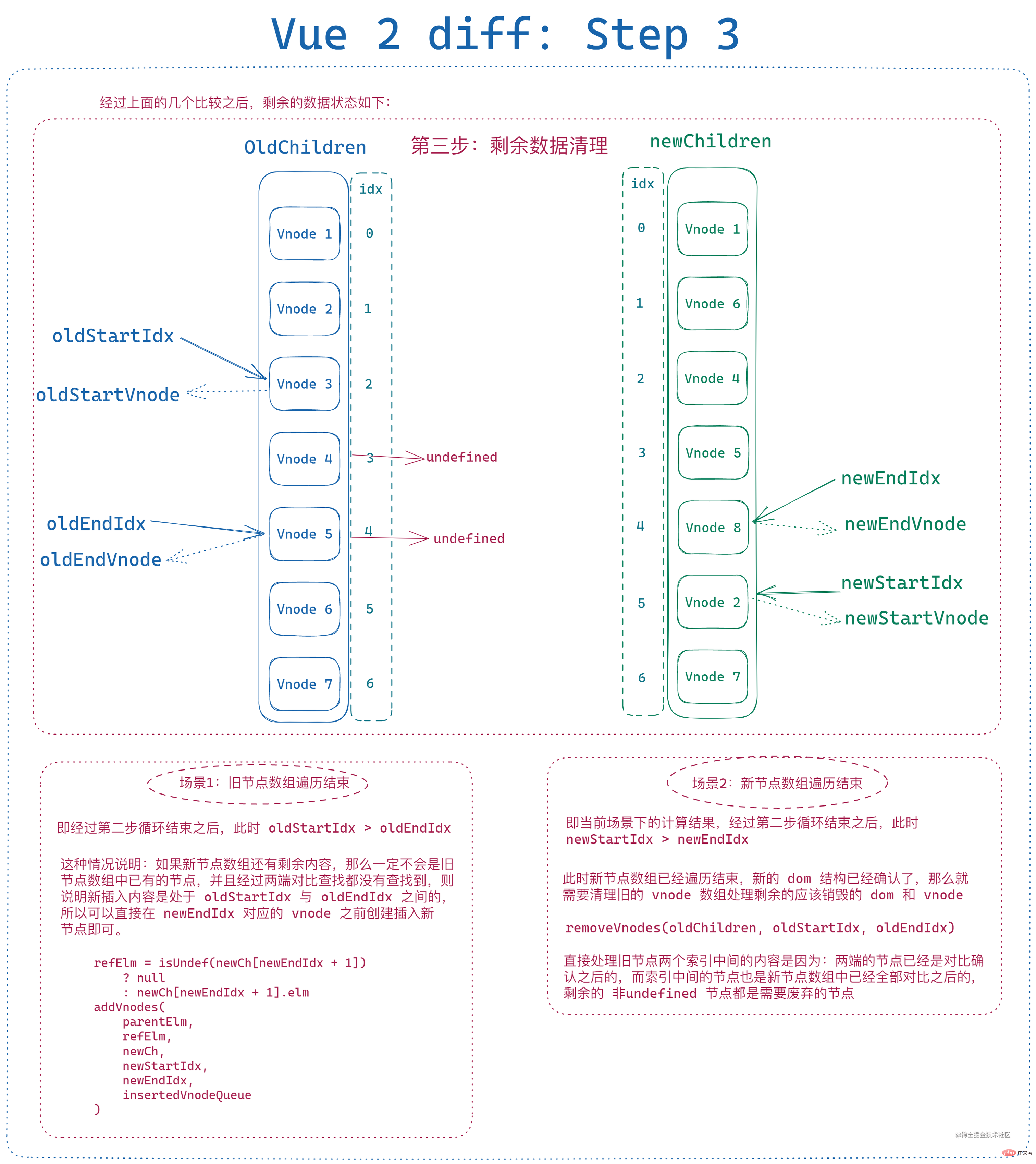
The node status at this time is as follows:

2. Confirm that vnode exists before comparing
In order to ensure the old and new The node array will not perform invalid comparison during comparison, and will first exclude the data where the beginning part and end part of the old node array are continuous and the value is Undefined.
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
Of course this is not the case in our example and can be ignored.
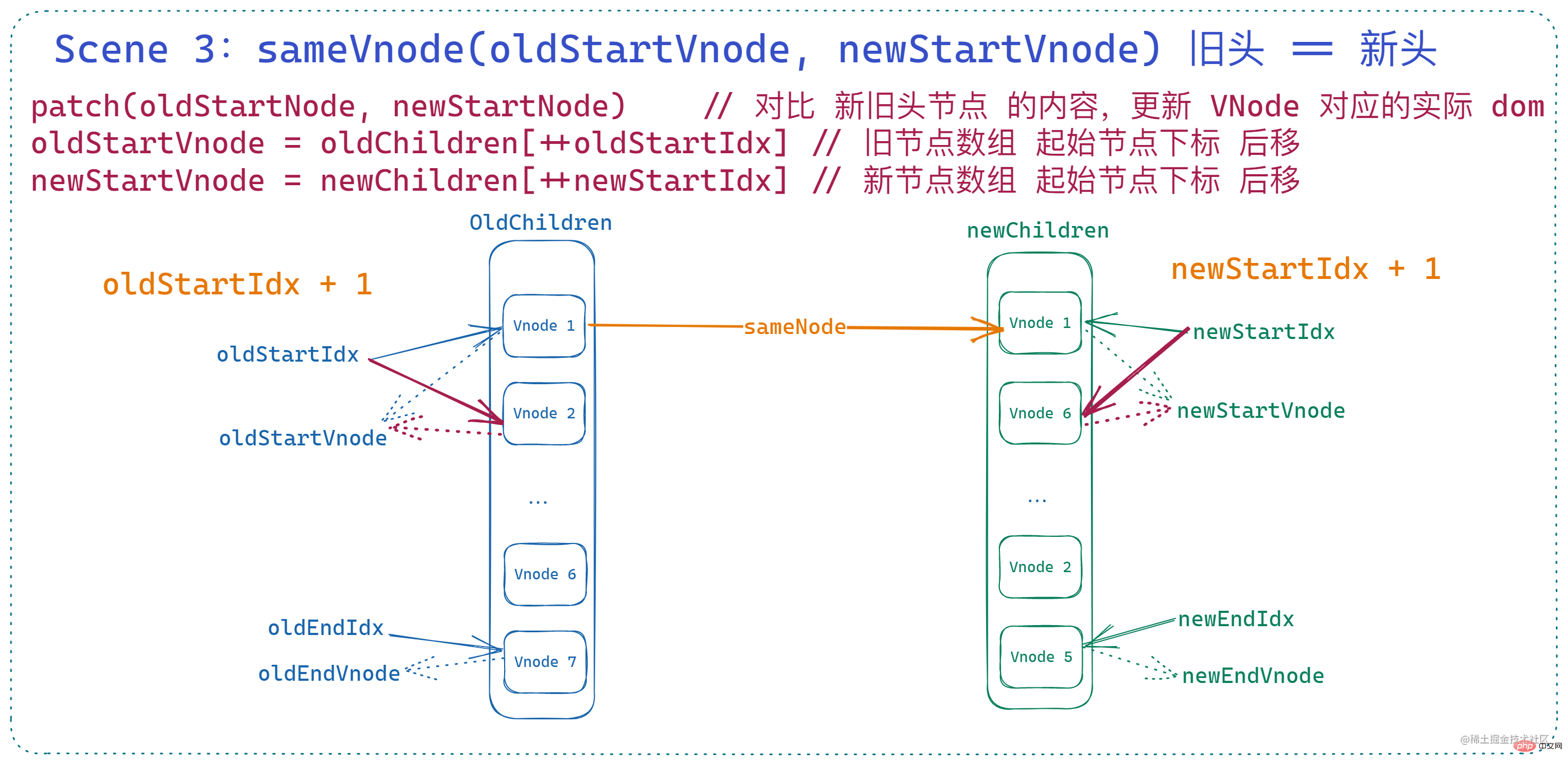
3. The old head is equal to the new head
At this time, it is equivalent to the two starting indexes of the old and new node arrays. The node pointed to isBasically consistent, then patchVnode will be called at this time to perform deep comparison and dom update of the two vnodes, and the two starting indexes will be moved backward . That is:
if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
is similar to head node equality. This situation means that
the last node of the old and new node arrays are basically the same. At this time, patchVnode is also called to compare the sum of the two tail nodes. Update the dom and move the two end indices forward . if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}
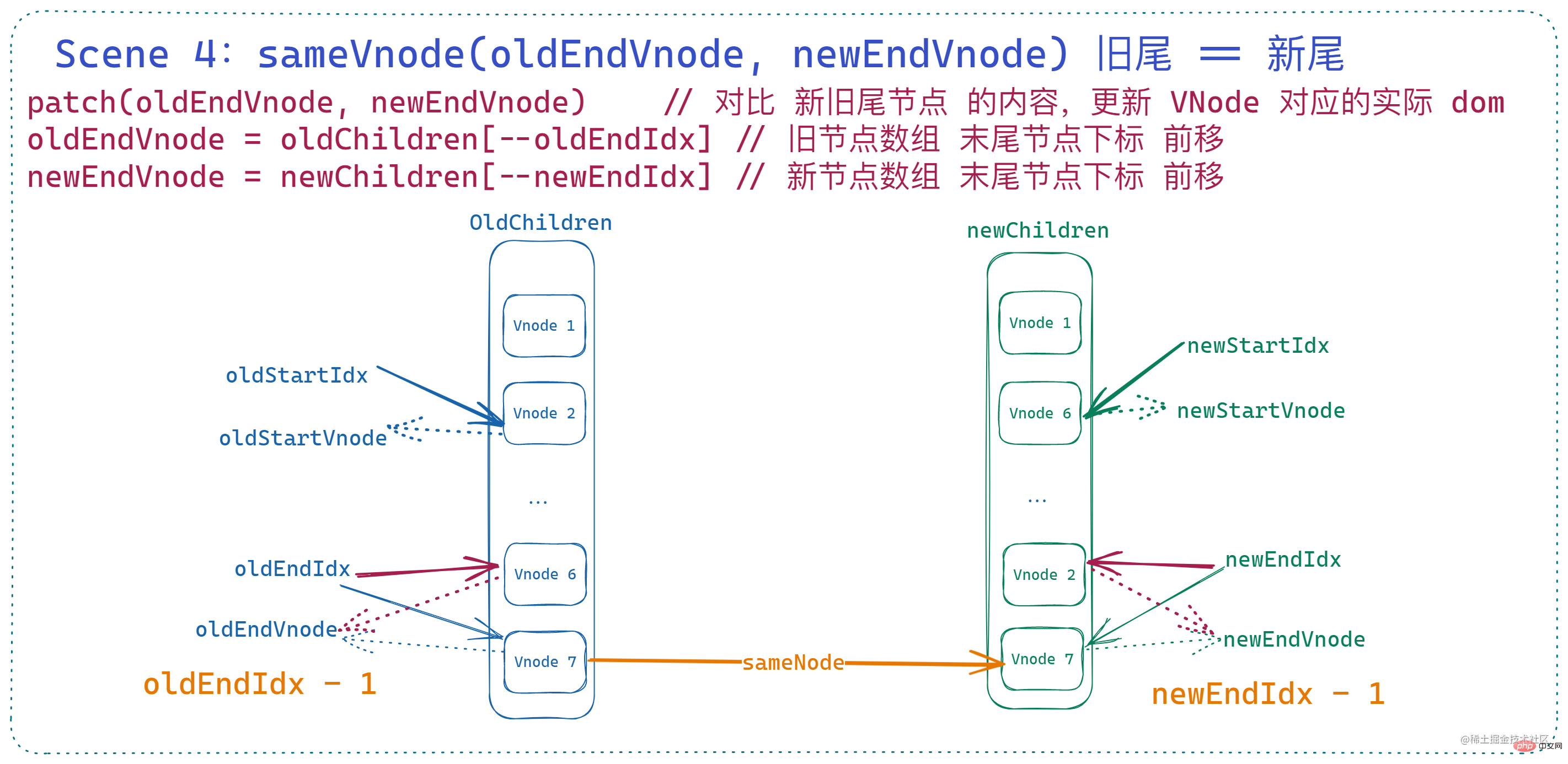
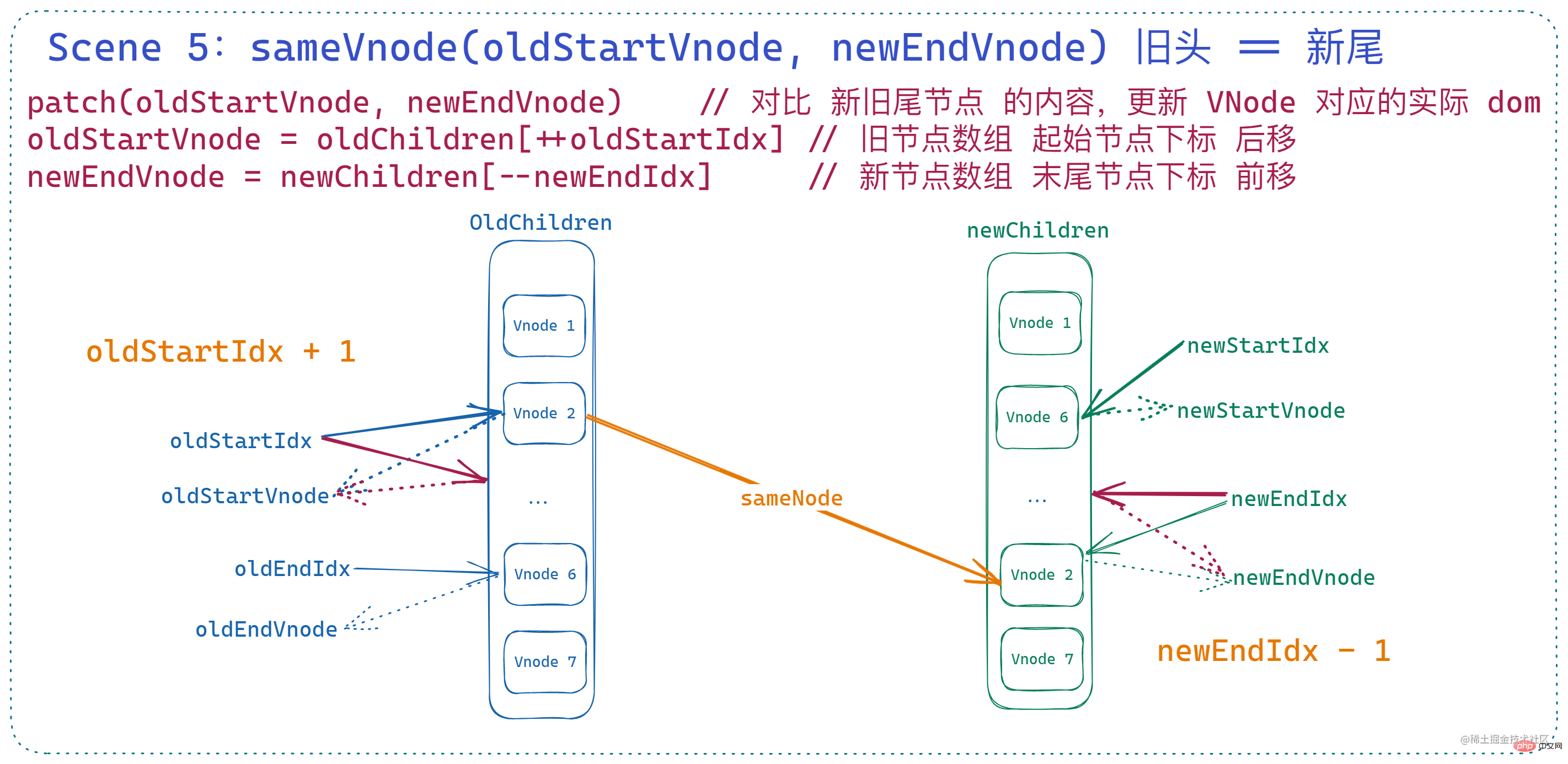
What this means is that
The vnode pointed by the current starting index of the old node array is basically the same as the vnode pointed by the current end index of the new node array. Call patchVnode to perform the same on the two nodes. deal with. But the difference from the above two is that in this case, the
, so it will end at patchVnode Then reinsert the old head node through nodeOps.insertBefore to after the current old tail node . Then,
forward.
You may have a question when you see this, why is theold node arraymoved here? This is because there is an attribute elm in the vnode node. , will point to the actual dom node corresponding to the vnode, so moving the old node array here is actually
moving the actual dom node sequenceon the side; and note that this is the current tail node, when the index changes Afterwards, this is not necessarily the end of the old node array.
即:
if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}此时状态如下:
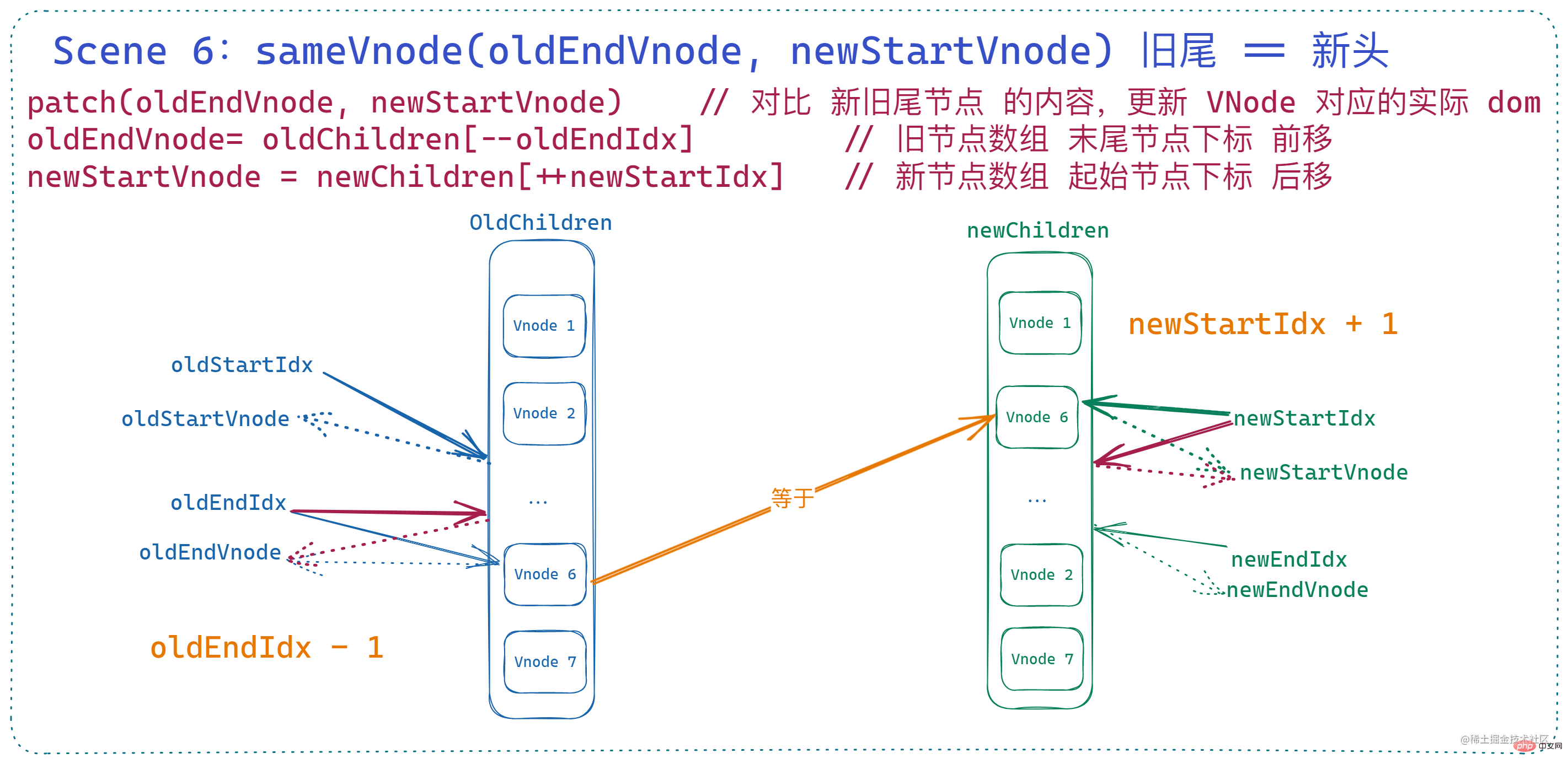
6. 旧尾等于新头
这里与上面的 旧头等于新尾 类似,一样要涉及到节点对比和移动,只是调整的索引不同。此时 旧节点的 末尾索引 前移、新节点的 起始索引 后移,当然了,这里的 dom 移动对应的 vnode 操作是 将旧节点数组的末尾索引对应的 vnode 插入到旧节点数组 起始索引对应的 vnode 之前。
if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}此时状态如下:
7. 四者均不相等
在以上情况都处理之后,就来到了四个节点互相都不相等的情况,这种情况也是 最复杂的情况。
当经过了上面几种处理之后,此时的 索引与对应的 vnode 状态如下:
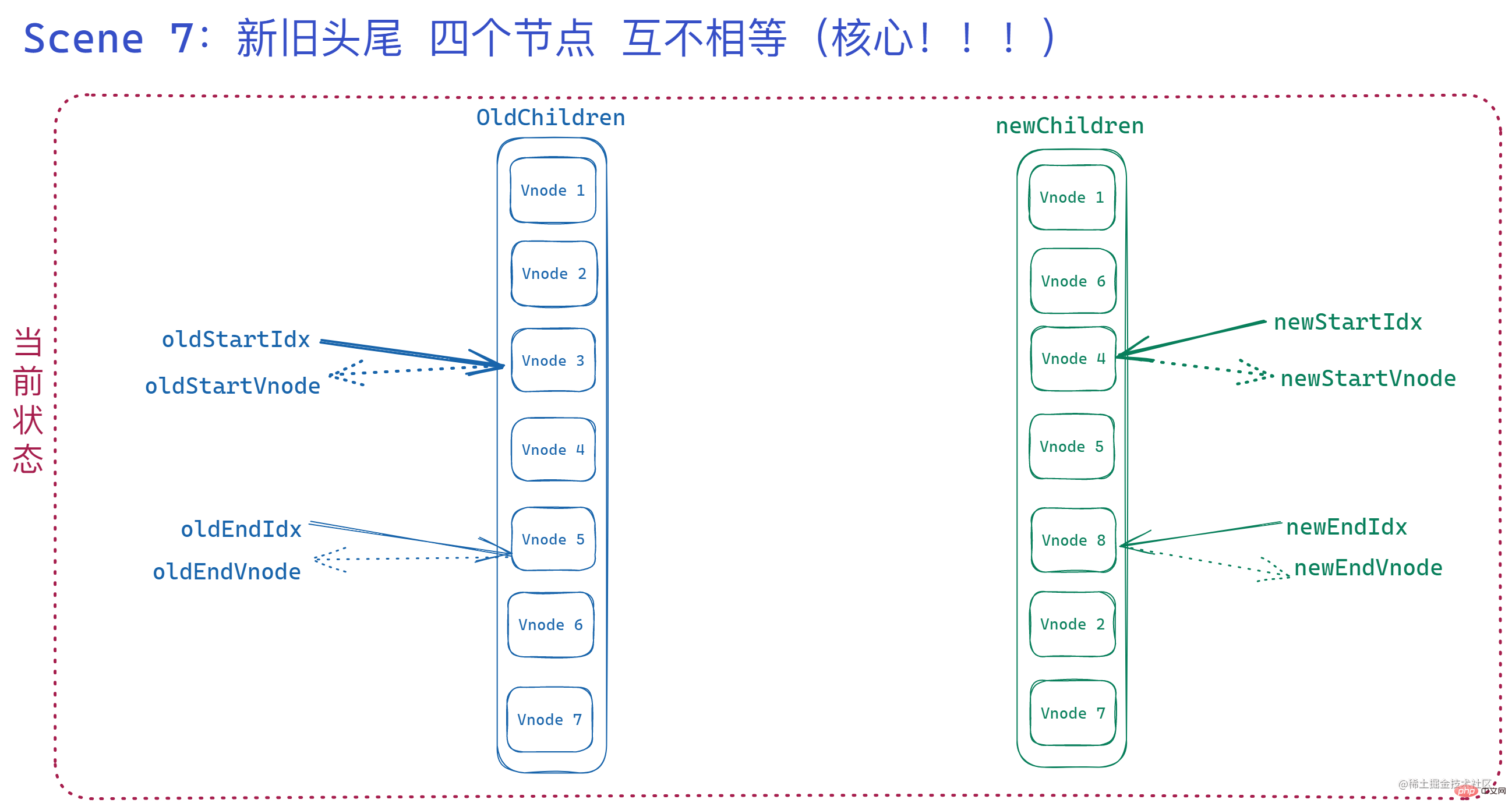
可以看到四个索引对应的 vnode 分别是:vnode 3、vnode 5、 vnode 4、vnode 8,这几个肯定是不一样的。
此时也就意味着 双端对比结束。
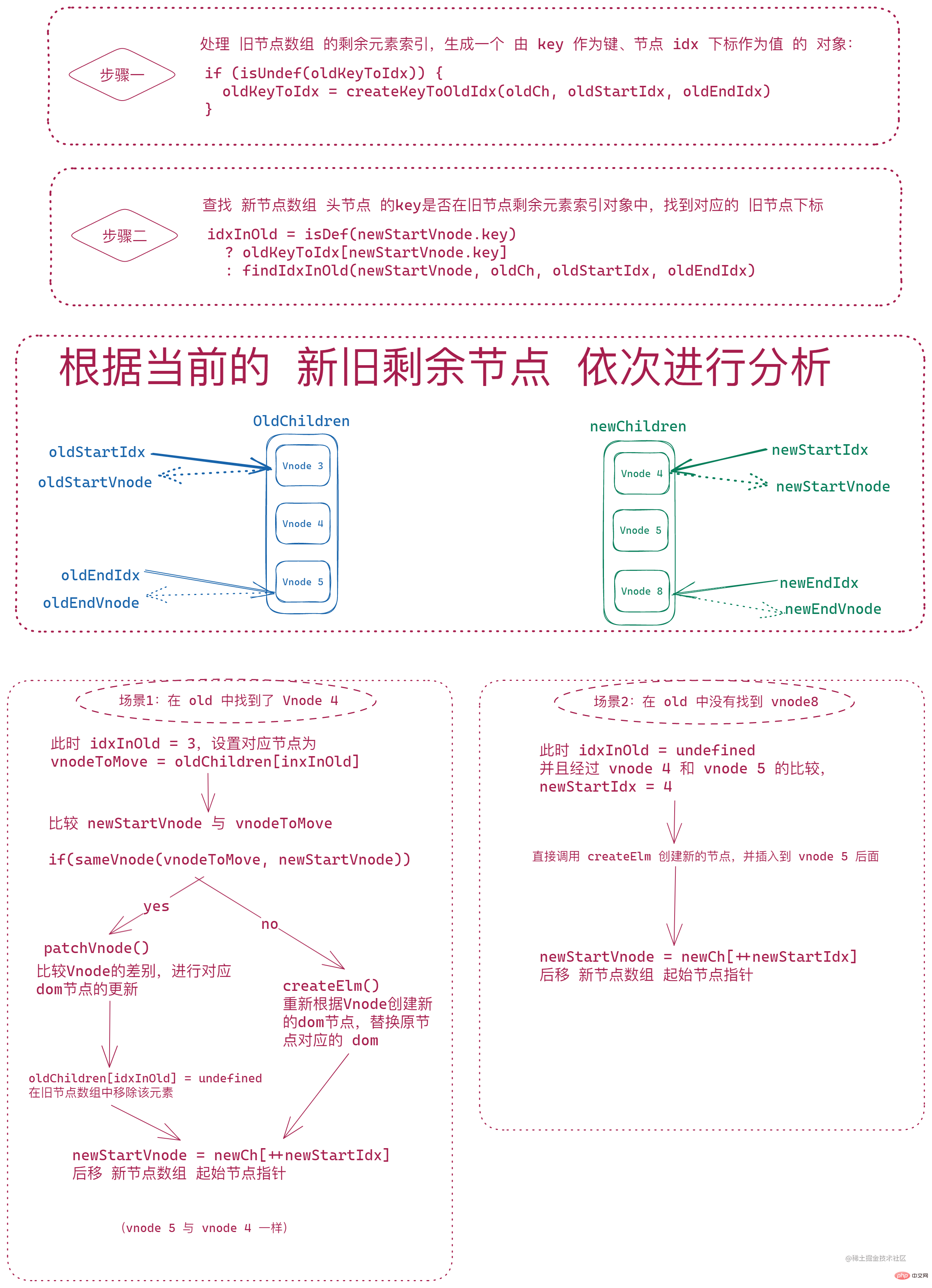
后面的节点对比则是 将旧节点数组剩余的 vnode (oldStartIdx 到 oldEndIdx 之间的节点)进行一次遍历,生成由 vnode.key 作为键,idx 索引作为值的对象 oldKeyToIdx,然后 遍历新节点数组的剩余 vnode(newStartIdx 到 newEndIdx 之间的节点),根据新的节点的 key 在 oldKeyToIdx 进行查找。此时的每个新节点的查找结果只有两种情况:
找到了对应的索引,那么会通过
sameVNode对两个节点进行对比:- 相同节点,调用
patchVnode进行深层对比和 dom 更新,将oldKeyToIdx中对应的索引idxInOld对应的节点插入到oldStartIdx对应的 vnode 之前;并且,这里会将 旧节点数组中idxInOld对应的元素设置为undefined - 不同节点,则调用
createElm重新创建一个新的 dom 节点并将 新的 vnode 插入到对应的位置
- 相同节点,调用
没有找到对应的索引,则直接
createElm创建新的 dom 节点并将新的 vnode 插入到对应位置
注:这里 只有找到了旧节点并且新旧节点一样才会将旧节点数组中
idxInOld中的元素置为undefined。
最后,会将 新节点数组的 起始索引 向后移动。
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
}
}
newStartVnode = newCh[++newStartIdx]
}大致逻辑如下图:
剩余未比较元素处理
经过上面的处理之后,根据判断条件也不难看出,遍历结束之后 新旧节点数组都刚好没有剩余元素 是很难出现的,当且仅当遍历过程中每次新头尾节点总能和旧头尾节点中总能有两个新旧节点相同时才会发生,只要有一个节点发生改变或者顺序发生大幅调整,最后 都会有一个节点数组起始索引和末尾索引无法闭合。
那么此时就需要对剩余元素进行处理:
- 旧节点数组遍历结束、新节点数组仍有剩余,则遍历新节点数组剩余数据,分别创建节点并插入到旧末尾索引对应节点之前
- 新节点数组遍历结束、旧节点数组仍有剩余,则遍历旧节点数组剩余数据,分别从节点数组和 dom 树中移除
即:
小结
Vue 2 的 diff 算法相对于简单 diff 算法来说,通过 双端对比与生成索引 map 两种方式 减少了简单算法中的多次循环操作,新旧数组均只需要进行一次遍历即可将所有节点进行对比。
The double-end comparison will perform four comparisons and moves respectively, and the performance is not the optimal solution, so Vue 3 introduced the Longest Increasing Subsequence method to replace the double-end comparison. , while the rest still uses space expansion to reduce time complexity by converting it into an index map, thereby further improving computing performance.
Of course, the real dom node of elm corresponding to vnode is not given in the figure of this article. The mobile relationship between the two may cause misunderstandings. It is recommended to read it together with "Vue.js Design and Implementation".
The overall process is as follows:
(Learning video sharing: vuejs introductory tutorial, Programming Basic video)
The above is the detailed content of Quickly understand the Vue2 diff algorithm (detailed graphic explanation). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to add functions to buttons for vue
Apr 08, 2025 am 08:51 AM
How to add functions to buttons for vue
Apr 08, 2025 am 08:51 AM
You can add a function to the Vue button by binding the button in the HTML template to a method. Define the method and write function logic in the Vue instance.
 How to use bootstrap in vue
Apr 07, 2025 pm 11:33 PM
How to use bootstrap in vue
Apr 07, 2025 pm 11:33 PM
Using Bootstrap in Vue.js is divided into five steps: Install Bootstrap. Import Bootstrap in main.js. Use the Bootstrap component directly in the template. Optional: Custom style. Optional: Use plug-ins.
 How to reference js file with vue.js
Apr 07, 2025 pm 11:27 PM
How to reference js file with vue.js
Apr 07, 2025 pm 11:27 PM
There are three ways to refer to JS files in Vue.js: directly specify the path using the <script> tag;; dynamic import using the mounted() lifecycle hook; and importing through the Vuex state management library.
 How to use watch in vue
Apr 07, 2025 pm 11:36 PM
How to use watch in vue
Apr 07, 2025 pm 11:36 PM
The watch option in Vue.js allows developers to listen for changes in specific data. When the data changes, watch triggers a callback function to perform update views or other tasks. Its configuration options include immediate, which specifies whether to execute a callback immediately, and deep, which specifies whether to recursively listen to changes to objects or arrays.
 How to return to previous page by vue
Apr 07, 2025 pm 11:30 PM
How to return to previous page by vue
Apr 07, 2025 pm 11:30 PM
Vue.js has four methods to return to the previous page: $router.go(-1)$router.back() uses <router-link to="/" component window.history.back(), and the method selection depends on the scene.
 What does vue multi-page development mean?
Apr 07, 2025 pm 11:57 PM
What does vue multi-page development mean?
Apr 07, 2025 pm 11:57 PM
Vue multi-page development is a way to build applications using the Vue.js framework, where the application is divided into separate pages: Code Maintenance: Splitting the application into multiple pages can make the code easier to manage and maintain. Modularity: Each page can be used as a separate module for easy reuse and replacement. Simple routing: Navigation between pages can be managed through simple routing configuration. SEO Optimization: Each page has its own URL, which helps SEO.
 How to jump to the div of vue
Apr 08, 2025 am 09:18 AM
How to jump to the div of vue
Apr 08, 2025 am 09:18 AM
There are two ways to jump div elements in Vue: use Vue Router and add router-link component. Add the @click event listener and call this.$router.push() method to jump.
 How to use foreach loop in vue
Apr 08, 2025 am 06:33 AM
How to use foreach loop in vue
Apr 08, 2025 am 06:33 AM
The foreach loop in Vue.js uses the v-for directive, which allows developers to iterate through each element in an array or object and perform specific operations on each element. The syntax is as follows: <template> <ul> <li v-for="item in items>>{{ item }}</li> </ul> </template>&am
