
 Backend Development
Golang
What are atomic operations? An in-depth analysis of atomic operations in go
Backend Development
Golang
What are atomic operations? An in-depth analysis of atomic operations in go
What are atomic operations? An in-depth analysis of atomic operations in go


In some of our previous articles related to the sync package, we should have also discovered that atomic operations are used in many places.
For example, sync.WaitGroup, sync.Map, and then sync.Pool, these structures all have atomic operations in their implementation.
Atomic operations are a very important operation in concurrent programming. They can ensure concurrency safety and are very efficient.
This article will deeply explore the principles, usage scenarios, usage, etc. of atomic operations in go.
What are atomic operations?
Atomic operations are variable-level mutex locks.
If I were to explain in one sentence what an atomic operation is, it would be: Atomic operations are variable-level mutex locks. Simply put, at the same time, only one CPU can read or write variables.
When we want to make concurrent and safe modifications to a certain variable, in addition to using the officially provided Mutex, we can also use the atomic operations of the sync/atomic package.
It can ensure that the reading or modification of variables will not be affected by other coroutines.
We can use the following figure to represent it:
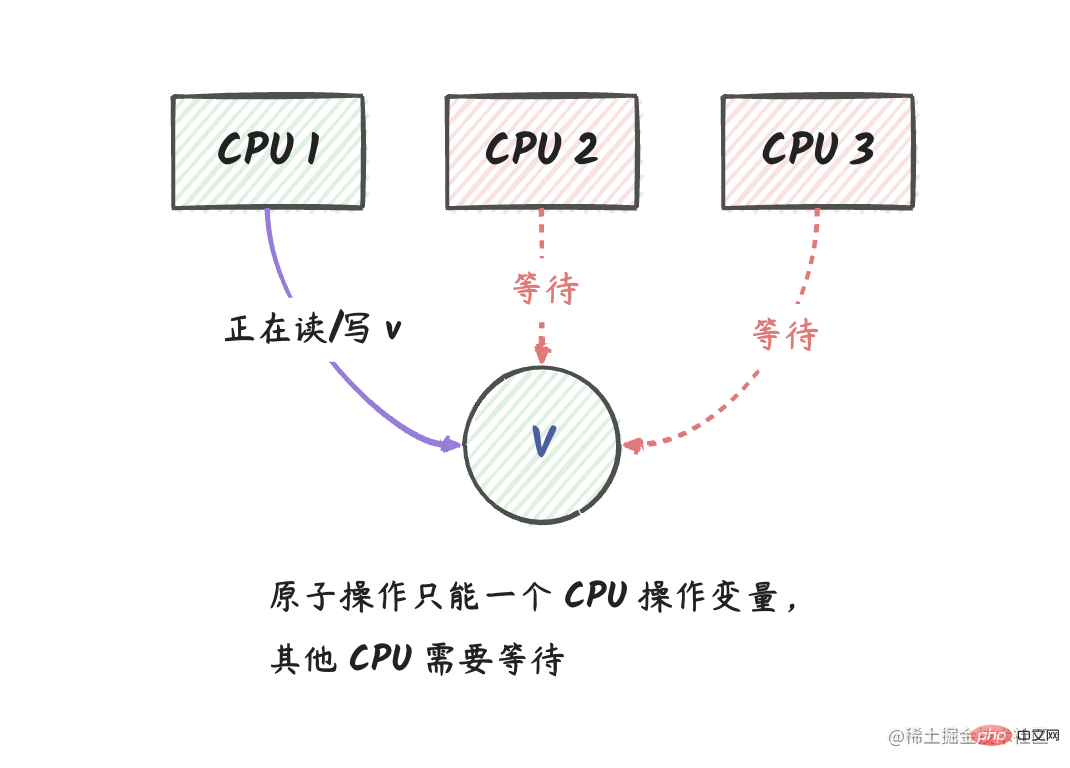
#Explanation: In the above figure, we have three CPU logical cores, among which CPU 1 is processing variablesv performs atomic operations. At this time, CPU 2 and CPU 3 cannot perform any operations on v.
After the CPU 1 operation is completed, CPU 2 and CPU 3 can obtain the latest value of v.
From this perspective, we can regard the atomic operations in the
sync/atomicpackage as variable-level mutex locks. That is to say, in go, when a coroutine performs an atomic operation on a variable, other coroutines cannot perform any operations on the variable until the coroutine operation is completed.
What are the usage scenarios of atomic operations?
Take a simple example to illustrate the usage scenario of atomic operations:
func TestAtomic(t *testing.T) {
var sum = 0
var wg sync.WaitGroup
wg.Add(1000)
// 启动 1000 个协程,每个协程对 sum 做加法操作
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
sum++
}()
}
// 等待所有的协程都执行完毕
wg.Wait()
fmt.Println(sum) // 这里输出多少呢?
}We can run this code on our own computer to see what the output result is. . If nothing else, it should be different every time, and it shouldn’t be 1000. Why is this?
This is because when the CPU adds sum, it needs to first read the current value of sum into the CPU register, and then perform the addition. operation, and finally write it back to memory.
If two CPUs take the value of sum at the same time, then both perform addition operations, and then both write them back to the memory, then the value of sum will be overwritten. This results in incorrect results.
For example, the current sum in the memory is 1, and then the two CPUs take this 1 for addition at the same time, and then both get the result 2,
Then the two CPUs write their respective calculation results back to the memory, so the sum in the memory becomes 2 instead of 3.
In this scenario, we can use atomic operations to implement concurrent and safe addition operations:
func TestAtomic1(t *testing.T) {
// 将 sum 的类型改成 int32,因为原子操作只能针对 int32、int64、uint32、uint64、uintptr 这几种类型
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
// 启动 1000 个协程,每个协程对 sum 做加法操作
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// 将 sum++ 改成下面这样
atomic.AddInt32(&sum, 1)
}()
}
wg.Wait()
fmt.Println(sum) // 输出 1000
}In the above example, we can get the result of 1000 every time we execute it.
Because when using atomic operations, only one CPU can read or write variables at the same time, so the above problem will not occur.
So in many places where concurrent reading and writing of variables is required, we can consider whether atomic operations can be used to achieve concurrent and safe operations (instead of using mutex locks, mutual exclusion locks, etc.) The lock exclusion efficiency is lower than that of atomic operations).
The usage scenarios of atomic operations are similar to mutex locks, but the difference is that our lock granularity is just a variable. In other words, when we do not allow multiple CPUs to read and write variables at the same time (to ensure that only one CPU can operate on variables at the same time), we can use atomic operations.
How are atomic operations implemented?
After reading the above introduction to atomic operations, do you think that atomic operations are amazing and that there is such a useful thing? So how is it achieved?
Generally, the implementation of atomic operations requires special CPU instructions or system calls. These instructions or system calls can ensure that they will not be interrupted by other operations or events during execution, thereby ensuring the atomicity of the operation.
例如,在 x86 架构的 CPU 中,可以使用 LOCK 前缀来实现原子操作。LOCK 前缀可以与其他指令一起使用,用于锁定内存总线,防止其他 CPU 访问同一内存地址,从而实现原子操作。
在使用 LOCK 前缀的指令执行期间,CPU 会将当前处理器缓存中的数据写回到内存中,并锁定该内存地址,
防止其他 CPU 修改该地址的数据(所以原子操作总是可以读取到最新的数据)。
一旦当前 CPU 对该地址的操作完成,CPU 会释放该内存地址的锁定,其他 CPU 才能继续对该地址进行访问。
x86 LOCK 的时候发生了什么
我们再来捋一下上面的内容,看看 LOCK 前缀是如何实现原子操作的:
- CPU 会将当前处理器缓存中的数据写回到内存中。(因此我们总能读取到最新的数据)
- 然后锁定该内存地址,防止其他 CPU 修改该地址的数据。
- 一旦当前 CPU 对该地址的操作完成,CPU 会释放该内存地址的锁定,其他 CPU 才能继续对该地址进行访问。
其他架构的 CPU 可能会略有不同,但是原理是一样的。
原子操作有什么特征?
- 不会被中断:原子操作是一个不可分割的操作,要么全部执行,要么全部不执行,不会出现中间状态。这是保证原子性的基本前提。同时,原子操作过程中不会有上下文切换的过程。
- 操作对象是共享变量:原子操作通常是对共享变量进行的,也就是说,多个协程可以同时访问这个变量,因此需要采用原子操作来保证数据的一致性和正确性。
- 并发安全:原子操作是并发安全的,可以保证多个协程同时进行操作时不会出现数据竞争问题(虽然说是同时,但是实际上在操作那个变量的时候是互斥的)。
- 无需加锁:原子操作不需要使用互斥锁来保证数据的一致性和正确性,因此可以避免互斥锁的使用带来的性能损失。
- 适用场景比较局限:原子操作适用于操作单个变量,如果需要同时并发读写多个变量,可能需要考虑使用互斥锁。
go 里面有哪些原子操作?
在 go 中,主要有以下几种原子操作:Add、CompareAndSwap、Load、Store、Swap。
增减(Add)
- 用于进行增加或减少的原子操作,函数名以
Add为前缀,后缀针对特定类型的名称。 - 原子增被操作的类型只能是数值类型,即
int32、int64、uint32、uint64、uintptr - 原子增减函数的第一个参数为原值,第二个参数是要增减多少。
- 方法:
func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
int32和int64的第二个参数可以是负数,这样就可以做原子减法了。
比较并交换(CompareAndSwap)
也就是我们常见的 CAS,在 CAS 操作中,会需要拿旧的值跟 old 比较,如果相等,就将 new 赋值给 addr。
如果不相等,则不做任何操作。最后返回一个 bool 值,表示是否成功 swap。
也就是说,这个操作可能是不成功的。这很正常,在并发环境下,多个协程对同一个变量进行操作,肯定会存在竞争的情况。 在这种情况下,偶尔的失败是正常的,我们只需要在失败的时候,重新尝试即可。 因为原子操作需要的时间往往是比较短的,因此在失败的时候,我们可以通过自旋的方式来再次进行尝试。
在这种情况下,如果不自旋,那就需要将这个协程挂起,等待其他协程完成操作,然后再次尝试。这个过程相比自旋可能会更加耗时。 因为很有可能这次原子操作不成功,下一次就成功了。如果我们每次都将协程挂起,那么效率就会大大降低。
for + 原子操作的方式,在 go 的 sync 包中很多地方都有使用,比如 sync.Map,sync.Pool 等。
这也是使用原子操作时一个非常常见的使用模式。
CompareAndSwap 的功能:
- 用于比较并交换的原子操作,函数名以
CompareAndSwap为前缀,后缀针对特定类型的名称。 - 原子比较并交换被操作的类型可以是数值类型或指针类型,即
int32、int64、uint32、uint64、uintptr、unsafe.Pointer - 原子比较并交换函数的第一个参数为原值指针,第二个参数是要比较的值,第三个参数是要交换的值。
- 方法:
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
载入(Load)
原子性的读取操作接受一个对应类型的指针值,返回该指针指向的值。原子性读取意味着读取值的同时,当前计算机的任何 CPU 都不会进行针对值的读写操作。
如果不使用原子 Load,当使用 v := value 这种赋值方式为变量 v 赋值时,读取到的 value 可能不是最新的,因为在读取操作时其他协程对它的读写操作可能会同时发生。
Load 操作有下面这些:
func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
存储(Store)
Store 可以将 val 值保存到 *addr 中,Store 操作是原子性的,因此在执行 Store 操作时,当前计算机的任何 CPU 都不会进行针对 *addr 的读写操作。
- 原子性存储会将
val值保存到*addr中。 - 与读操作对应的写入操作,
sync/atomic提供了与原子值载入Load函数相对应的原子值存储Store函数,原子性存储函数均以Store为前缀。
Store 操作有下面这些:
func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintpre, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
交换(Swap)
Swap 跟 Store 有点类似,但是它会返回 *addr 的旧值。
func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
原子操作任意类型的值 - atomic.Value
从上一节中,我们知道了在 go 中原子操作可以操作 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 这些类型的值。
但是在实际开发中,我们的类型还有很多,比如 string、struct 等等,那这些类型的值如何进行原子操作呢?答案是使用 atomic.Value。
atomic.Value 是一个结构体,它的内部有一个 any 类型的字段,存储了我们要原子操作的值,也就是一个任意类型的值。
atomic.Value 支持以下操作:
Load:原子性的读取Value中的值。Store:原子性的存储一个值到Value中。Swap:原子性的交换Value中的值,返回旧值。CompareAndSwap:原子性的比较并交换Value中的值,如果旧值和old相等,则将new存入Value中,返回true,否则返回false。
atomic.Value 的这些操作跟上面讲到的那些操作其实差不多,只不过 atomic.Value 可以操作任意类型的值。
那 atomic.Value 是如何实现的呢?
atomic.Value 源码分析
atomic.Value 是一个结构体,这个结构体只有一个字段:
// Value 提供一致类型值的原子加载和存储。
type Value struct {
v any
}Load - 读取
Load 返回由最近的 Store 设置的值。如果还没有 Store 过任何值,则返回 nil。
// Load 返回由最近的 Store 设置的值。
func (v *Value) Load() (val any) {
// atomic.Value 转换为 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// 判断 atomic.Value 的类型
typ := LoadPointer(&vp.typ)
// 第一次 Store 还没有完成,直接返回 nil
if typ == nil || typ == unsafe.Pointer(&firstStoreInProgress) {
// firstStoreInProgress 是一个特殊的变量,存储到 typ 中用来表示第一次 Store 还没有完成
return nil
}
// 获取 atomic.Value 的值
data := LoadPointer(&vp.data)
// 将 val 转换为 efaceWords 类型
vlp := (*efaceWords)(unsafe.Pointer(&val))
// 分别赋值给 val 的 typ 和 data
vlp.typ = typ
vlp.data = data
return
}在 atomic.Value 的源码中,我们都可以看到 efaceWords 的身影,它实际上代表的是 interface{}/any 类型:
// 表示一个 interface{}/any 类型
type efaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}看到这里我们会不会觉得很困惑,直接返回 val 不就可以了吗?为什么要将 val 转换为 efaceWords 类型呢?
这是因为 go 中的原子操作只能操作 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 这些类型的值,
不支持 interface{} 类型,但是如果了解 interface{} 底层结构的话,我们就知道 interface{} 底层其实就是一个结构体,
它有两个字段,一个是 type,一个是 data,type 用来存储 interface{} 的类型,data 用来存储 interface{} 的值。
而且这两个字段都是 unsafe.Pointer 类型的,所以其实我们可以对 interface{} 的 type 和 data 分别进行原子操作,
这样最终其实也可以达到了原子操作 interface{} 的目的了,是不是非常地巧妙呢?
Store - 存储
Store 将 Value 的值设置为 val。对给定值的所有存储调用必须使用相同具体类型的值。不一致类型的存储会发生恐慌,Store(nil) 也会 panic。
// Store 将 Value 的值设置为 val。
func (v *Value) Store(val any) {
// 不能存储 nil 值
if val == nil {
panic("sync/atomic: store of nil value into Value")
}
// atomic.Value 转换为 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// val 转换为 efaceWords
vlp := (*efaceWords)(unsafe.Pointer(&val))
// 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小
for {
// LoadPointer 可以保证获取到的是最新的
typ := LoadPointer(&vp.typ)
// 第一次 store 的时候 typ 还是 nil,说明是第一次 store
if typ == nil {
// 尝试开始第一次 Store。
// 禁用抢占,以便其他 goroutines 可以自旋等待完成。
// (如果允许抢占,那么其他 goroutine 自旋等待的时间可能会比较长,因为可能会需要进行协程调度。)
runtime_procPin()
// 抢占失败,意味着有其他 goroutine 成功 store 了,允许抢占,再次尝试 Store
// 这也是一个原子操作。
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
// 完成第一次 store
// 因为有 firstStoreInProgress 标识的保护,所以下面的两个原子操作是安全的。
StorePointer(&vp.data, vlp.data) // 存储值(原子操作)
StorePointer(&vp.typ, vlp.typ) // 存储类型(原子操作)
runtime_procUnpin() // 允许抢占
return
}
// 另外一个 goroutine 正在进行第一次 Store。自旋等待。
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
// 第一次 Store 已经完成了,下面不是第一次 Store 了。
// 需要检查当前 Store 的类型跟第一次 Store 的类型是否一致,不一致就 panic。
if typ != vlp.typ {
panic("sync/atomic: store of inconsistently typed value into Value")
}
// 后续的 Store 只需要 Store 值部分就可以了。
// 因为 atomic.Value 只能保存一种类型的值。
StorePointer(&vp.data, vlp.data)
return
}
}在 Store 中,有以下几个注意的点:
- 使用
firstStoreInProgress来确保第一次Store的时候,只有一个goroutine可以进行Store操作,其他的goroutine需要自旋等待。如果没有这个保护,那么存储typ和data的时候就会出现竞争(因为需要两个原子操作),导致数据不一致。在这里其实可以将firstStoreInProgress看作是一个互斥锁。 - 在进行第一次
Store的时候,会将当前的 goroutine 和P绑定,这样拿到firstStoreInProgress锁的协程就可以尽快地完成第一次Store操作,这样一来,其他的协程也不用等待太久。 - 在第一次
Store的时候,会有两个原子操作,分别存储类型和值,但是因为有firstStoreInProgress的保护,所以这两个原子操作本质上是对interface{}的一个原子存储操作。 - 其他协程在看到有
firstStoreInProgress标识的时候,就会自旋等待,直到第一次Store完成。 - 在后续的
Store操作中,只需要存储值就可以了,因为atomic.Value只能保存一种类型的值。
Swap - 交换
Swap 将 Value 的值设置为 new 并返回旧值。对给定值的所有交换调用必须使用相同具体类型的值。同时,不一致类型的交换会发生恐慌,Swap(nil) 也会 panic。
// Swap 将 Value 的值设置为 new 并返回旧值。
func (v *Value) Swap(new any) (old any) {
// 不能存储 nil 值
if new == nil {
panic("sync/atomic: swap of nil value into Value")
}
// atomic.Value 转换为 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// new 转换为 efaceWords
np := (*efaceWords)(unsafe.Pointer(&new))
// 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小
for {
// 下面这部分代码跟 Store 一样,不细说了。
// 这部分代码是进行第一次存储的代码。
typ := LoadPointer(&vp.typ)
if typ == nil {
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
StorePointer(&vp.data, np.data)
StorePointer(&vp.typ, np.typ)
runtime_procUnpin()
return nil
}
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
if typ != np.typ {
panic("sync/atomic: swap of inconsistently typed value into Value")
}
// ---- 下面是 Swap 的特有逻辑 ----
// op 是返回值
op := (*efaceWords)(unsafe.Pointer(&old))
// 返回旧的值
op.typ, op.data = np.typ, SwapPointer(&vp.data, np.data)
return old
}
}CompareAndSwap - 比较并交换
CompareAndSwap 将 Value 的值与 old 比较,如果相等则设置为 new 并返回 true,否则返回 false。
对给定值的所有比较和交换调用必须使用相同具体类型的值。同时,不一致类型的比较和交换会发生恐慌,CompareAndSwap(nil, nil) 也会 panic。
// CompareAndSwap 比较并交换。
func (v *Value) CompareAndSwap(old, new any) (swapped bool) {
// 注意:old 是可以为 nil 的,new 不能为 nil。
// old 是 nil 表示是第一次进行 Store 操作。
if new == nil {
panic("sync/atomic: compare and swap of nil value into Value")
}
// atomic.Value 转换为 efaceWords
vp := (*efaceWords)(unsafe.Pointer(v))
// new 转换为 efaceWords
np := (*efaceWords)(unsafe.Pointer(&new))
// old 转换为 efaceWords
op := (*efaceWords)(unsafe.Pointer(&old))
// old 和 new 类型必须一致,且不能为 nil
if op.typ != nil && np.typ != op.typ {
panic("sync/atomic: compare and swap of inconsistently typed values")
}
// 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小
for {
// LoadPointer 可以保证获取到的 typ 是最新的
typ := LoadPointer(&vp.typ)
if typ == nil { // atomic.Value 是 nil,还没 Store 过
// 准备进行第一次 Store,但是传递进来的 old 不是 nil,compare 这一步就失败了。直接返回 false
if old != nil {
return false
}
// 下面这部分代码跟 Store 一样,不细说了。
// 这部分代码是进行第一次存储的代码。
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
StorePointer(&vp.data, np.data)
StorePointer(&vp.typ, np.typ)
runtime_procUnpin()
return true
}
if typ == unsafe.Pointer(&firstStoreInProgress) {
continue
}
if typ != np.typ {
panic("sync/atomic: compare and swap of inconsistently typed value into Value")
}
// 通过运行时相等性检查比较旧版本和当前版本。
// 这允许对值类型进行比较,这是包函数所没有的。
// 下面的 CompareAndSwapPointer 仅确保 vp.data 自 LoadPointer 以来没有更改。
data := LoadPointer(&vp.data)
var i any
(*efaceWords)(unsafe.Pointer(&i)).typ = typ
(*efaceWords)(unsafe.Pointer(&i)).data = data
if i != old { // atomic.Value 跟 old 不相等
return false
}
// 只做 val 部分的 cas 操作
return CompareAndSwapPointer(&vp.data, data, np.data)
}
}这里需要特别说明的只有最后那个比较相等的判断,也就是 data := LoadPointer(&vp.data) 以及往后的几行代码。
在开发 atomic.Value 第一版的时候,那个开发者其实是将这几行写成 CompareAndSwapPointer(&vp.data, old.data, np.data) 这种形式的。
但是在旧的写法中,会存在一个问题,如果我们做 CAS 操作的时候,如果传递的参数 old 是一个结构体的值这种类型,那么这个结构体的值是会被拷贝一份的,
同时再会被转换为 interface{}/any 类型,这个过程中,其实参数的 old 的 data 部分指针指向的内存跟 vp.data 指向的内存是不一样的。
这样的话,CAS 操作就会失败,这个时候就会返回 false,但是我们本意是要比较它的值,出现这种结果显然不是我们想要的。
将值作为
interface{}参数使用的时候,会存在一个将值转换为interface{}的过程。具体我们可以看看interface{}的实现原理。
所以,在上面的实现中,会将旧值的 typ 和 data 赋值给一个 any 类型的变量,
然后使用 i != old 这种方式进行判断,这样就可以实现在比较的时候,比较的是值,而不是由值转换为 interface{} 后的指针。
其他原子类型
我们现在知道了,atomic.Value 可以对任意类型做原子操作。
而对于其他的原子类型,比如 int32、int64、uint32、uint64、uintptr、unsafe.Pointer 等,
其实在 go 中也提供了包装的类型,让我们可以以对象的方式来操作这些类型。
对应的类型如下:
atomic.Bool:这个比较特别,但底层实际上是一个uint32类型的值。我们对atomic.Bool做原子操作的时候,实际上是对uint32做原子操作。atomic.Int32:int32类型的包装类型atomic.Int64:int64类型的包装类型atomic.Uint32:uint32类型的包装类型atomic.Uint64:uint64类型的包装类型atomic.Uintptr:uintptr类型的包装类型atomic.Pointer:unsafe.Pointer类型的包装类型
这几种类型的实现的代码基本一样,除了类型不一样,我们可以看看 atomic.Int32 的实现:
// An Int32 is an atomic int32. The zero value is zero.
type Int32 struct {
_ noCopy
v int32
}
// Load atomically loads and returns the value stored in x.
func (x *Int32) Load() int32 { return LoadInt32(&x.v) }
// Store atomically stores val into x.
func (x *Int32) Store(val int32) { StoreInt32(&x.v, val) }
// Swap atomically stores new into x and returns the previous value.
func (x *Int32) Swap(new int32) (old int32) { return SwapInt32(&x.v, new) }
// CompareAndSwap executes the compare-and-swap operation for x.
func (x *Int32) CompareAndSwap(old, new int32) (swapped bool) {
return CompareAndSwapInt32(&x.v, old, new)
}可以看到,atomic.Int32 的实现都是基于 atomic 包中 int32 类型相关的原子操作函数来实现的。
原子操作与互斥锁比较
那我们有了互斥锁,为什么还要有原子操作呢?我们进行比较一下就知道了:
| 原子操作 | 互斥锁 | |
|---|---|---|
| 保护的范围 | 变量 | 代码块 |
| 保护的粒度 | 小 | 大 |
| 性能 | 高 | 低 |
| 如何实现的 | 硬件指令 | 软件层面实现,逻辑较多 |
如果我们只需要对某一个变量做并发读写,那么使用原子操作就可以了,因为原子操作的性能比互斥锁高很多。 但是如果我们需要对多个变量做并发读写,那么就需要用到互斥锁了,这种场景往往是在一段代码中对不同变量做读写。
性能比较
我们前面这个表格提到了原子操作与互斥锁性能上有差异,我们写几行代码来进行比较一下:
// 系统信息 cpu: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz
// 10.13 ns/op
func BenchmarkMutex(b *testing.B) {
var mu sync.Mutex
for i := 0; i < b.N; i++ {
mu.Lock()
mu.Unlock()
}
}
// 5.849 ns/op
func BenchmarkAtomic(b *testing.B) {
var sum atomic.Uint64
for i := 0; i < b.N; i++ {
sum.Add(uint64(1))
}
}在对 Mutex 的性能测试中,我只是写了简单的 Lock() 和 UnLock() 操作,因为这种比较才算是对 Mutex 本身的测试,而在 Atomic 的性能测试中,对 sum 做原子累加的操作。最终结果是,使用 Atomic 的操作耗时大概比 Mutex 少了 40% 以上。
在实际开发中,
Mutex保护的临界区内往往有更多操作,也就意味着Mutex锁需要耗费更长的时间才能释放,也就是会需要耗费比上面这个40%还要多的时间另外一个协程才能获取到Mutex锁。
go 的 sync 包中的原子操作
在文章的开头,我们就说了,在 go 的 sync.Map 和 sync.Pool 中都有用到了原子操作,本节就来看一看这些操作。
sync.Map 中的原子操作
在 sync.Map 中使用到了一个 entry 结构体,这个结构体中大部分操作都是原子操作,我们可以看看它下面这两个方法的定义:
// 删除 entry
func (e *entry) delete() (value any, ok bool) {
for {
p := e.p.Load()
// 已经被删除了,不需要再删除
if p == nil || p == expunged {
return nil, false
}
// 删除成功
if e.p.CompareAndSwap(p, nil) {
return *p, true
}
}
}
// 如果条目尚未删除,trySwap 将交换一个值。
func (e *entry) trySwap(i *any) (*any, bool) {
for {
p := e.p.Load()
// 已经被删除了
if p == expunged {
return nil, false
}
// swap 成功
if e.p.CompareAndSwap(p, i) {
return p, true
}
}
}我们可以看到一个非常典型的特征就是 for + CompareAndSwap 的组合,这个组合在 entry 中出现了很多次。
如果我们也需要对变量做并发读写,也可以尝试一下这种 for + CompareAndSwap 的组合。
sync.WaitGroup 中的原子操作
在 sync.WaitGroup 中有一个类型为 atomic.Uint64 的 state 字段,这个变量是用来记录 WaitGroup 的状态的。
在实际使用中,它的高 32 位用来记录 WaitGroup 的计数器,低 32 位用来记录 WaitGroup 的 Waiter 的数量,也就是等待条件变量满足的协程数量。
如果不使用一个变量来记录这两个值,那么我们就需要使用两个变量来记录,这样就会导致我们需要对两个变量做并发读写, 在这种情况下,我们就需要使用互斥锁来保护这两个变量,这样就会导致性能的下降。
而使用一个变量来记录这两个值,我们就可以使用原子操作来保护这个变量,这样就可以保证并发读写的安全性,同时也能得到更好的性能:
// WaitGroup 的 Add 函数:高 32 位加上 delta state := wg.state.Add(uint64(delta) << 32) // WaitGroup 的 Wait 函数:低 32 位加 1 // 等待者的数量加 1 wg.state.CompareAndSwap(state, state+1)
CAS 操作有失败必然有成功
当然这里是指指向同一行 CAS 代码的时候(也就是有竞争的时候),如果是指向不同行 CAS 代码的时候,那么就不一定了。
比如下面这个例子,我们把前面计算 sum 的例子改一改,改成用 CAS 操作来完成:
func TestCas(t *testing.T) {
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// 这一行是有可能会失败的
atomic.CompareAndSwapInt32(&sum, sum, sum+1)
}()
}
wg.Wait()
fmt.Println(sum) // 不是 1000
}在这个例子中,我们把 atomic.AddInt32(&sum, 1) 改成了 atomic.CompareAndSwapInt32(&sum, sum, sum+1),
这样就会导致有可能会有多个 goroutine 同时执行到 atomic.CompareAndSwapInt32(&sum, sum, sum+1) 这一行代码,
这样肯定会有不同的 goroutine 同时拿到一个相同的 sum 的旧值,那么在这种情况下,就会导致 CAS 操作失败。
也就是说,将 sum 替换为 sum + 1 的操作可能会失败。
失败意味着什么呢?意味着另外一个协程序先把 sum 的值加 1 了,这个时候其实我们不应该在旧的 sum 上加 1 了,
而是应该在最新的 sum 上加上 1,那我们应该怎么做呢?我们可以在 CAS 操作失败的时候,重新获取 sum 的值,
然后再次尝试 CAS 操作,直到成功为止:
func TestCas(t *testing.T) {
var sum int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i++ {
go func() {
defer wg.Done()
// cas 失败的时候,重新获取 sum 的值进行计算。
// cas 成功则返回。
for {
if atomic.CompareAndSwapInt32(&sum, sum, sum+1) {
return
}
}
}()
}
wg.Wait()
fmt.Println(sum)
}总结
原子操作是并发编程中非常重要的一个概念,它可以保证并发读写的安全性,同时也能得到更好的性能。
最后,总结一下本文讲到的内容:
- Atomic operations are lower-level operations that protect a single variable, while mutex locks can protect a piece of code. Their usage scenarios are different.
- Atomic operations need to be implemented through CPU instructions, while mutex locks are implemented at the software level.
- The atomic operations in go include the following:
-
#Add: Atomic increase and decrease -
CompareAndSwap: Atomic comparison and exchange -
Load: Atomic read -
Store: Atomic write -
Swap: Atomic swap
-
- All types in go can use atomic operations, but different types of atomic operations use different functions.
-
atomic.Valuecan be used to atomically operate variables of any type. - Some underlying implementations in go also use atomic operations, such as:
-
sync.WaitGroup: Use atomic operations to ensure the safety of concurrent reading and writing of counters and waiters. sex. -
sync.Map:entryBasically all operations in the structure have atomic operations.
-
- If the atomic operation fails, it must succeed (it is talking about the
CASoperation in the same line). If theCASoperation fails, then we can Re-obtain the old value and try theCASoperation again until it succeeds.
In general, the atomic operation itself does not have too complicated logic. After we understand its principles, we can use it easily.
Recommended learning: Golang tutorial
The above is the detailed content of What are atomic operations? An in-depth analysis of atomic operations in go. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 How to send Go WebSocket messages?
Jun 03, 2024 pm 04:53 PM
How to send Go WebSocket messages?
Jun 03, 2024 pm 04:53 PM
In Go, WebSocket messages can be sent using the gorilla/websocket package. Specific steps: Establish a WebSocket connection. Send a text message: Call WriteMessage(websocket.TextMessage,[]byte("Message")). Send a binary message: call WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}).
 How to match timestamps using regular expressions in Go?
Jun 02, 2024 am 09:00 AM
How to match timestamps using regular expressions in Go?
Jun 02, 2024 am 09:00 AM
In Go, you can use regular expressions to match timestamps: compile a regular expression string, such as the one used to match ISO8601 timestamps: ^\d{4}-\d{2}-\d{2}T \d{2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Use the regexp.MatchString function to check if a string matches a regular expression.
 How to avoid memory leaks in Golang technical performance optimization?
Jun 04, 2024 pm 12:27 PM
How to avoid memory leaks in Golang technical performance optimization?
Jun 04, 2024 pm 12:27 PM
Memory leaks can cause Go program memory to continuously increase by: closing resources that are no longer in use, such as files, network connections, and database connections. Use weak references to prevent memory leaks and target objects for garbage collection when they are no longer strongly referenced. Using go coroutine, the coroutine stack memory will be automatically released when exiting to avoid memory leaks.
 The difference between Golang and Go language
May 31, 2024 pm 08:10 PM
The difference between Golang and Go language
May 31, 2024 pm 08:10 PM
Go and the Go language are different entities with different characteristics. Go (also known as Golang) is known for its concurrency, fast compilation speed, memory management, and cross-platform advantages. Disadvantages of the Go language include a less rich ecosystem than other languages, a stricter syntax, and a lack of dynamic typing.
 How to use atomic operations in C++ to ensure thread safety?
Jun 05, 2024 pm 03:54 PM
How to use atomic operations in C++ to ensure thread safety?
Jun 05, 2024 pm 03:54 PM
Thread safety can be guaranteed by using atomic operations in C++, using std::atomic template class and std::atomic_flag class to represent atomic types and Boolean types respectively. Atomic operations are performed through functions such as std::atomic_init(), std::atomic_load(), and std::atomic_store(). In the actual case, atomic operations are used to implement thread-safe counters to ensure thread safety when multiple threads access concurrently, and finally output the correct counter value.
 How to use Golang's error wrapper?
Jun 03, 2024 pm 04:08 PM
How to use Golang's error wrapper?
Jun 03, 2024 pm 04:08 PM
In Golang, error wrappers allow you to create new errors by appending contextual information to the original error. This can be used to unify the types of errors thrown by different libraries or components, simplifying debugging and error handling. The steps are as follows: Use the errors.Wrap function to wrap the original errors into new errors. The new error contains contextual information from the original error. Use fmt.Printf to output wrapped errors, providing more context and actionability. When handling different types of errors, use the errors.Wrap function to unify the error types.
 A guide to unit testing Go concurrent functions
May 03, 2024 am 10:54 AM
A guide to unit testing Go concurrent functions
May 03, 2024 am 10:54 AM
Unit testing concurrent functions is critical as this helps ensure their correct behavior in a concurrent environment. Fundamental principles such as mutual exclusion, synchronization, and isolation must be considered when testing concurrent functions. Concurrent functions can be unit tested by simulating, testing race conditions, and verifying results.
 How to create a prioritized Goroutine in Go?
Jun 04, 2024 pm 12:41 PM
How to create a prioritized Goroutine in Go?
Jun 04, 2024 pm 12:41 PM
There are two steps to creating a priority Goroutine in the Go language: registering a custom Goroutine creation function (step 1) and specifying a priority value (step 2). In this way, you can create Goroutines with different priorities, optimize resource allocation and improve execution efficiency.
