

This article brings you relevant knowledge about data tables. It mainly shares with you a self-balancing table subdivision method to solve the problem of data skew. Friends who are interested can take a look at it together. I hope it will be helpful to everyone. help.
This article mainly describes the application of data sub-tables in the B-side token system to solve the problem of increasing business data volume and existing data skew. The main scenario is the one-to-many data skew problem
First briefly describe the business background of B token. The B token system is used in marketing scenarios to bind many users to one token and then bind the token to promotions to achieve differentiation and precision marketing. Generally, the life cycle of a token is equivalent to This promotion.
The relationship between tokens and token users is a one-to-many relationship. The early token systems used jed to divide The database has 2 shards, and an expansion was performed in the middle to reach 8 shards, and the number of stored data rows reached 120 million
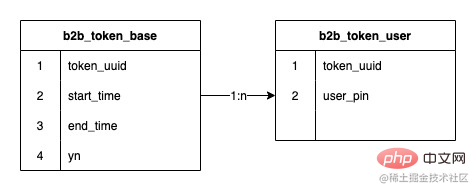
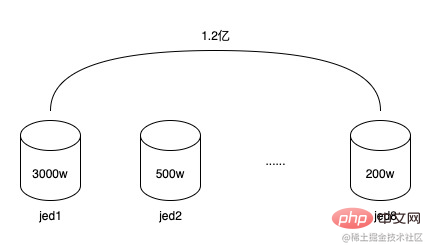
120 million data, distributed in 8 sub-databases, each sub-database has an average of 15 million, but because the sub-database fields use tokens ID (token_uuid), some have few token users, only a few thousand to 10,000, some have many token users, 1 million to 1.5 million, the total number of tokens is not many, only about 20,000, so the data exists Inclined, some sub-databases have more than 30 million data, and some sub-databases may only have a few million, which has begun to lead to a decline in database read and write performance. And because the data structure of the token user relationship table is very simple, although there are many data rows, it does not take up much space. The total occupied space of the 8 sub-databases is less than 20G. At the same time, the life cycle of tokens is basically the same as that of promotions. After a token serves one or several promotions, it will slowly expire and be discarded, and new tokens will continue to be created in the future. So these expired tokens can be archived.
At the same time, due to the development of B-side business, there are more business demands. Through communication with the business, I learned that an automatic selection system will be launched in the future. The system will automatically create tokens and select people suitable for promotion. In the future The monthly data increment is about 30 million. If it runs for one year, it will increase by 360 million. By then, the average data volume of a single table will reach 60 million. The current design architecture is completely unable to meet business needs.
At the same time, there is also a function to query users under the token in pages based on the token ID, but it is only used for management-side operations and is not used frequently.
Facing the declining database reading and writing Performance, as well as business growth needs, currently face the following problems:
How to solve the problem of too many rows of data in a single table
The current sub-database scheme has serious data skew
If we deal with future data growth
Generally speaking, to deal with the first problem, we usually need to divide the database into tables, and currently we have 8 partitions. database, and 8 sub-databases occupy less than 20G of space. The resources of a single database are seriously wasted, so we will not consider adding more sub-databases at all, so table sharding is the solution.
There are usually two ways to divide data into tables: vertical tables and horizontal tables.
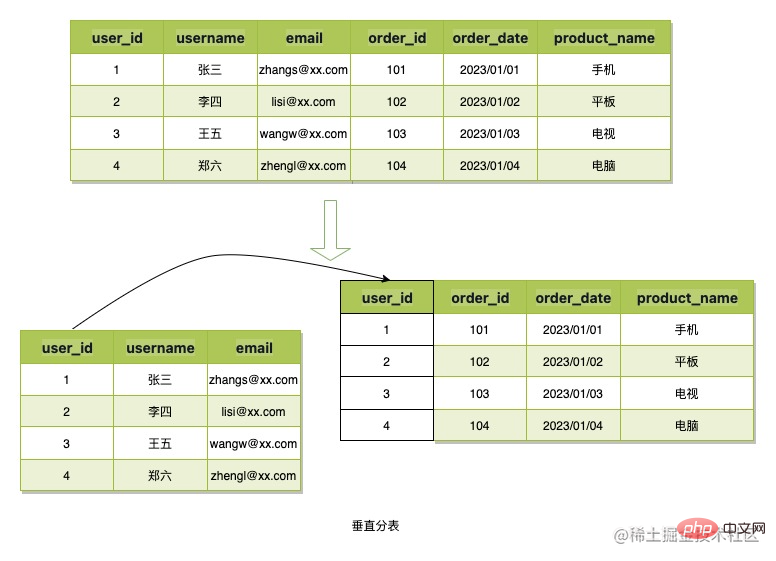
Vertical table splitting refers to splitting the columns of data and then applying primary keys or other business fields to associate them, thereby reducing the space occupied by single table data or reducing redundancy. For residual storage, the scene data structure of B token is simple and the data takes up little space, so this table splitting method will not be used.
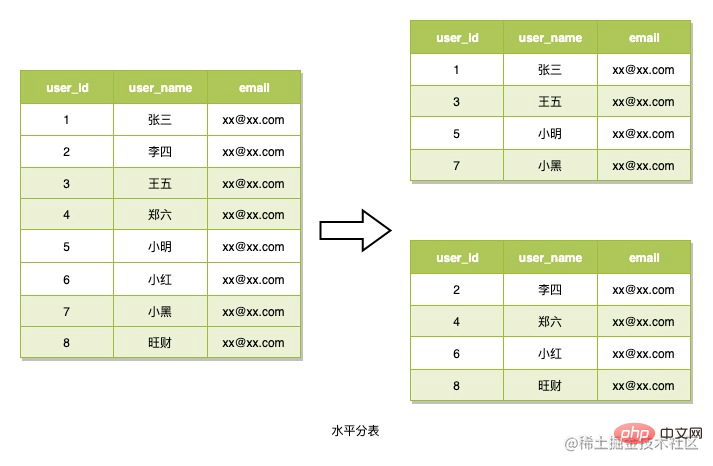
Horizontal table splitting refers to splitting data rows into multiple tables using a routing algorithm. The data is also read based on this routing algorithm when reading. This table partitioning strategy is generally used to deal with scenarios where the data structure is not complex but there are a large number of data rows. This is what we're going to use. What needs to be considered when using this method is how to design the routing algorithm. This method is also used here to divide tables.
There are many ways to use data table routing algorithms in the industry. One is to use consistency hash, select For appropriate sub-table fields, the value after hashing the field value is fixed. Use this value to obtain a fixed serial number through modulo or bitwise operation, thereby determining which table the data is stored in.
Most of the more common applications such as sub-library use consistent hashing. By instantly calculating the value of the sub-library field, it is judged which sub-library the data belongs to and then decides which sub-library to store the data in or read the data from. . If the sub-database field is not specified during the query, query requests need to be sent to all sub-databases at the same time, and finally the results are summarized.
In addition, the HashMap data structure like java code is actually a table partitioning strategy of a consistent hash algorithm. By hashing the key, it is decided which serial number the data will be stored in the array. What is used in HashMap is not modulo. Instead of obtaining the serial number, bitwise operations are used. This method also determines that the expansion of HashMap is based on the size of 2 to the power of x. I will introduce this principle when I have the opportunity in the future.
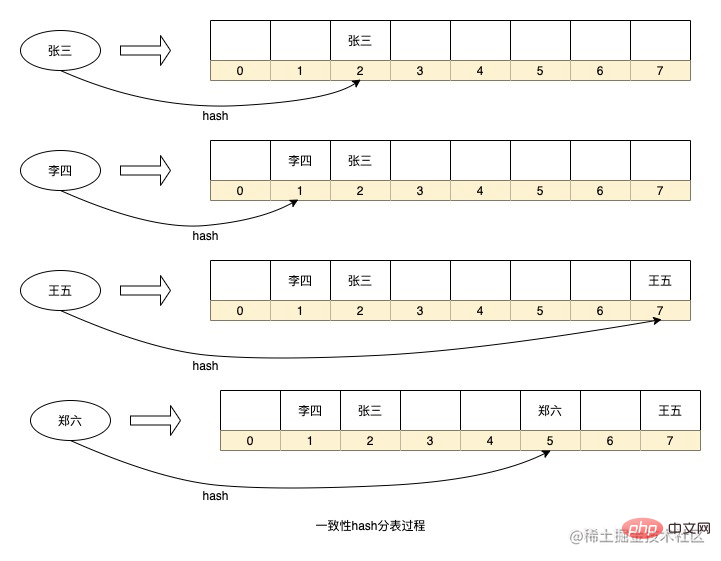
The above is a simplified data Hash storage process in HashMap. Of course, I have omitted some details. For example, each node in HashMap is a linked list (too many conflicts will cause will become a red-black tree). When applied in our scenario, each serial number can be regarded as a data table.
The advantages of the above routing algorithm are that the routing strategy is simple, and there is no need to add additional storage space for real-time calculations. However, there is also a problem that if you want to expand the capacity, you need to re-hash the historical data for migration, such as database partitioning. If the library adds sub-databases, all data needs to be recalculated into sub-databases. HashMap expansion will also perform rehash to recalculate the sequence number of the key in the array. If the amount of data is too large, this calculation process will take a long time. At the same time, if there are too few data tables, or if the fields selected for sharding have low discreteness, it will lead to data skew.
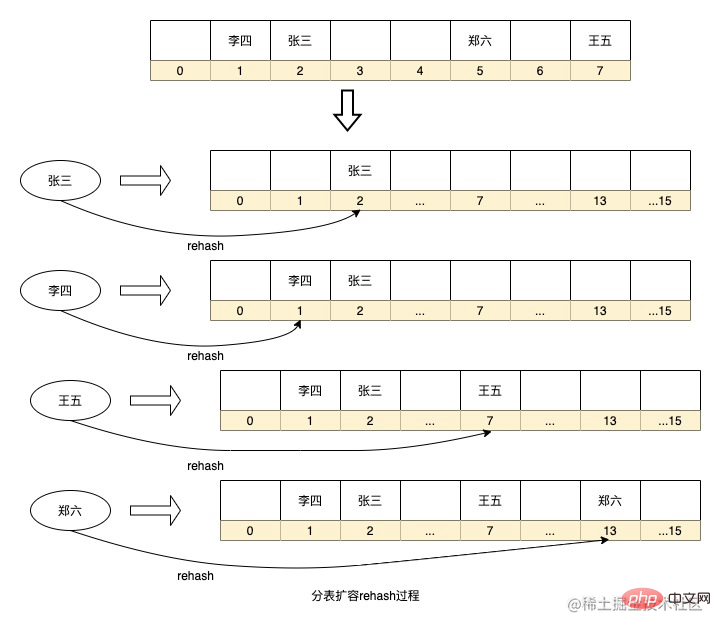
There is also a table splitting algorithm that optimizes this rehash process. This is the consistent hash ring. This method abstracts many virtual nodes between entity nodes. , and then use the consistent hash algorithm to hit the data on these virtual nodes, and each entity node is actually responsible for the data of the virtual nodes adjacent to the other entity node in the counterclockwise direction of the entity node. The advantage of this method is that if you need to expand the capacity and add nodes, the added node will be placed anywhere on the ring, and it will only affect the data of adjacent nodes in the clockwise direction of the node. Only part of the data in the node needs to be migrated to Just install it on this new node, which greatly reduces the rehash process. At the same time, due to the large number of virtual nodes, data can also be distributed more evenly on the ring. As long as the physical nodes are placed in the appropriate location, the data skew problem can be solved to the greatest extent.
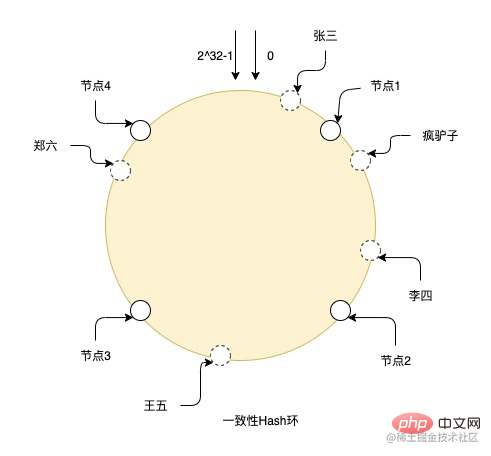
For example, the picture shows the hash process of a consistent Hash ring. There are nodes from 0 to 2^32-1 in the entire ring, and the solid line is the real one. Node, the others are all virtual nodes. Zhang San falls to the virtual node on the ring through hashing, and then searches for the real node clockwise from the position of the virtual node. The final data is stored on the real node, so Crazy Donkey and Li Si store On node 2, Wang Wu is on node 3, and Zheng Liu is on node 4.
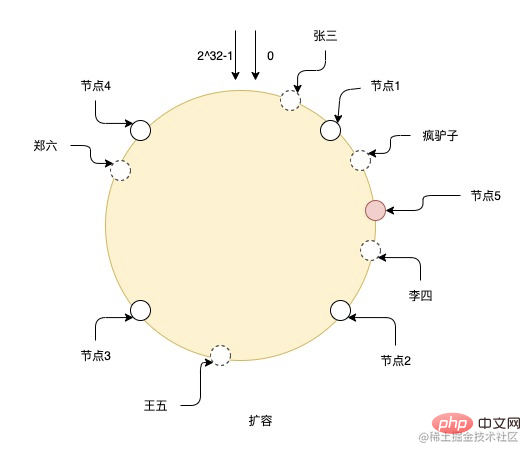
After expanding the capacity of node 5, the data between node 1 and node 5 needs to be migrated to node 5, and the data of other nodes does not need to be changed. But as you can see in the figure, adding only this one node can easily lead to uneven data responsible for each node. For example, node 2 and node 5 are responsible for much less data than other nodes, so it is best to expand the capacity. It is best to expand the capacity exponentially so that the data can continue to remain uniform.
Back to the business scenario of B token, I need to be able to achieve the following demands
First of all, horizontal table sharding must be used to solve the problem of excessive data volume in a single table
It is necessary to support paging query of users based on tokens
Since the current business data increment is 30 million, but the possibility of continued business growth in the future is not ruled out, the number of sub-tables needs to be able to support future expansion
The number of data rows is too high and will be expanded in the future It must be ensured that there is no need for data migration or that the cost of data migration is low
The problem of data skew needs to be solved to ensure that the overall performance is not reduced due to excessive data volume in a single table
Based on the above request, first look at question b. If you want to support paging query of users based on the token, you need to ensure that all users under the token are on the same table to simply support paging query. Otherwise, use some The summary and merge algorithm is too complex, and too many tables will reduce query performance. Although the query function can also be provided by using data heterogeneous es, it is only for a small number of management-side query requests to perform data heterogeneity. The cost is somewhat high and the benefits are not obvious, and it is also a waste of resources. Therefore, the sub-table field can only be determined using the token ID.
As mentioned above, the number of token IDs is not large, and the number of users under the tokens ranges from 10,000 to 1 million. Simply using consistent hashing and using token IDs as a sub-table strategy will lead to Data skew is serious, and data migration costs are also high during future expansion.
However, using a consistent hash ring will lead to the best expansion in the future by a multiple of 2. Otherwise, some nodes will be responsible for more virtual nodes, and some nodes will be responsible for fewer virtual nodes, resulting in The data is uneven. However, when communicating with database colleagues, the number of data tables in one database should not be too many, otherwise it will put great pressure on the database. The consistent hash ring method may expand the capacity two or three times, which will cause the number of sub-tables to reach one. Very high value.
Based on the above issues, under the premise of deciding to use token id as a sub-table, we need to focus on how to support dynamic expansion and solve the problem of data skew .
The fields of the sub-table have been determined to use the token ID. As mentioned earlier, our data structure is a one-to-many relationship between tokens and users. Then the sub-table hashed out when creating the token. The serial number is stored, and subsequent routing is performed based on the stored serial number of the sub-table, which ensures that future expansion will not affect the routing of existing data and does not require data migration.
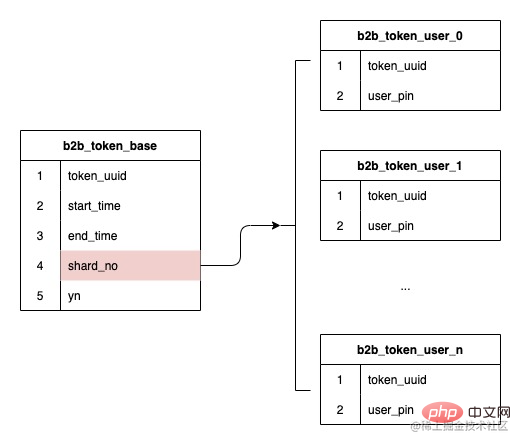
Because the token ID is selected as the sub-table field, the amount of data for each token Different sizes, data skew will be a big problem. So here we try to introduce the concept of sub-meter water level.

When the user requests to save or delete the number of related users, an increase or decrease in the number of current shards is performed based on the shard serial number. When the number of shards in a certain shard is When the data volume is at a high level, the sub-table will be removed from the sub-table algorithm so that the sub-table will not continue to generate new data.
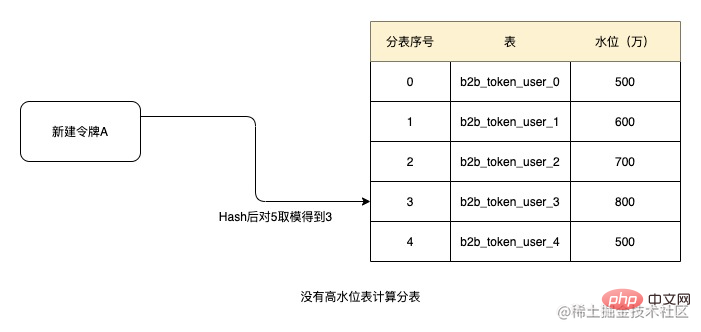
For example, when the threshold value of 10 million is set as the high water level, since none of the above five tables has reached the high water level, when creating the token, Hash and then take the modulus based on the token ID. Get 3, get the tables in order, then the sub-table number of the current token is b2b_token_user_3. Subsequent relational data is obtained from this table.
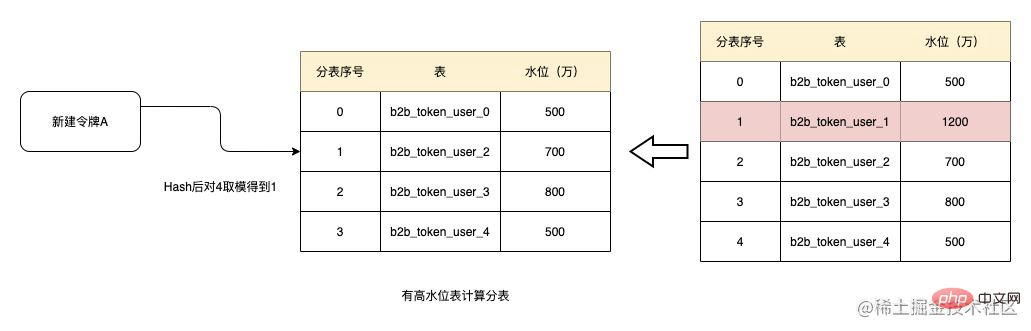
After running for a period of time, the data volume of table b2b_token_user_1 has increased to 12 million, exceeding the 10 million water level. At this time, when creating a token, the table will be removed. After hashing here and taking the modulus to get 1, the current assigned table is b2b_token_user_2. And if the water level of b2b_token_user_1 cannot be lowered, the table will no longer participate in sub-tables in the future, and the amount of data in the table will not increase.
Of course, there is a possibility that all the tables have entered the high water level. In order to be safe, the water level function will be disabled at this time, and all tables will be added to the sub-table.
If the amount of data in the table will only continue to increase rather than decrease, then sooner or later all tables will will reach a high water level, which cannot achieve dynamic effects. As mentioned in the above background, the token is created to serve a certain batch of promotions. After the promotion is terminated, the token will lose its effect. At the same time, the token also has an expiration date, and tokens that exceed the expiration date will also lose their effect. Therefore, archiving data regularly can allow those tables with high water levels to slowly lower their water levels and rejoin the sub-tables.
And the current token already exists in a b2b_token_user table, with 120 million data in it. You can use this table as table 0 on the diagram, so that when you go online for the first time, you only need to change the history command The serial numbers of Paidu's sub-tables can be recorded as 0, and the existing data does not need to be migrated. If the data volume of this table is high, it will not participate in the sub-table. Coupled with regular data archiving, the water level of the table will slowly come down.
Although regular data archiving can reduce the water level of the table, with the development of business, most tables may exist All have entered high water levels, and all are cases of valid data. At this time, the system will automatically expand just like HashMap when it judges that the capacity reaches 75%. We cannot automatically create tables, but when 75% of the tables enter the high water level, an alarm will be issued. Developers will monitor the alarm and intervene manually. Observation requires adjustment. If the water level is high, it is better to expand the table.
• Water level threshold and capacity expansion monitoring
Currently, the water level threshold still relies on manual setting. How large it should be set is quite emotional. You can only set one and adjust it appropriately after the alarm. However, in fact, the system can automatically monitor the fluctuations in the read and write performance of the interface. It is found that when most expressions reach a high level, the read and write performance of the interface does not change significantly. The system can automatically increase the threshold to form a smart threshold.
When the interface performance reading and writing changes significantly and it is found that most tables have reached the threshold, an alarm will be issued indicating that capacity expansion should be considered.
There is never a silver bullet to solve problems. We need to use the technical means and tools at hand to combine and adapt them to make them suitable for our current situation. For business and scenarios, there is no good or bad, only whether it is suitable or not.
The above is the detailed content of Knowledge expansion: a self-balancing table splitting method to solve data skew. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



