

In MySQL, load balancing refers to forming multiple MySQL servers into a cluster to improve database system performance by allocating database query requests. MySQL load balancing is to solve the bottleneck problem when a single database handles a large number of requests. It achieves the purpose of improving the performance of the database system by evenly distributing the requests to multiple servers. At the same time, load balancing can also improve the availability of the database system. Once one of the servers If one server fails, other servers can continue to process requests, thus ensuring service continuity.

The operating environment of this tutorial: windows7 system, mysql8 version, Dell G3 computer.
What is MySQL load balancing?
MySQL load balancing refers to forming multiple MySQL servers into a cluster and allocating database query requests to improve database system performance. Load balancing enables high availability, scalability, and load balancing.
The basic idea of load balancing is simple: average the load as much as possible in a server cluster. Based on this idea, our usual approach is to set up a load balancer on the front end of the server. The role of the load balancer is to route requested connections to the idlest available server.
Figure 1 shows a large website load balancing setup. One is responsible for HTTP traffic and the other is for MySQL access.
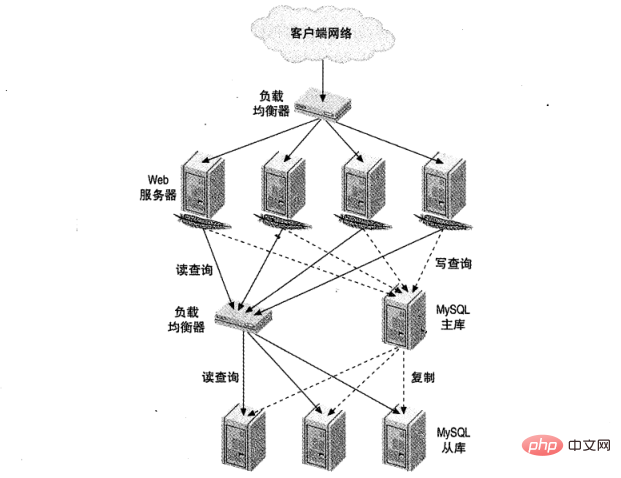
Why is MySQL load balancing needed?
MySQL load balancing is to solve the bottleneck problem when a single database handles a large number of requests. By evenly distributing requests to multiple servers, the purpose of improving database system performance is achieved. At the same time, load balancing can also improve the availability of the database system. Once one of the servers fails, other servers can continue to process requests, thus ensuring service continuity.
Load balancing has five common purposes:
Scalability. Load balancing is helpful for certain expansions, such as reading data from the standby database when reading and writing are separated.
Efficiency. Load balancing helps to use resources more efficiently by being able to control where requests are routed.
Availability. Flexible load balancing solutions can significantly improve service availability.
Transparency. The client does not need to know whether the load balancer exists, nor does it need to know how many machines are behind the load balancer. What is presented to the client is a transparent server.
consistency. If the application is stateful (database transactions, website sessions, etc.), then the load balancer can point related queries to the same server to prevent state loss.
How to implement MySQL load balancing
There are generally two ways to implement load balancing:Direct connection and Introduction of middleware.
Some people think that load balancing is to configure something directly between the application and the MySQL server, but in fact this is not the only load balancing method. Next, we will discuss common application direct connection methods and related precautions.
In this method, one of the biggest problems is prone to occur: Dirty data. A typical example is when a user comments on a blog post and then reloads the page but does not see the new comment.
Of course, we cannot abandon read-write separation because of the problem of dirty data. In fact, for many applications, the tolerance for dirty data may be relatively high, and this method can be boldly introduced at this time.
So for applications that have a low tolerance for dirty data, how to separate reading and writing? Next, we will further differentiate between reading and writing separation. I believe you can always find a strategy that suits you.
1) Based on query separation
If the application has only a small amount of data that cannot tolerate dirty data, we can allocate all reads and writes that cannot tolerate dirty data to the master . Other read queries are allocated on the slave. This strategy is easy to implement, but if there are few queries that tolerate dirty data, it is likely that the standby database cannot be used effectively.
2) Separation based on dirty data
This is a small improvement to the query-based separation strategy. Some additional work is required, such as having the application check replication latency to determine whether the standby data is up to date. Many reporting applications can use this strategy: they only need to copy the data loaded at night to the standby database interface, and they don't care whether it has completely caught up with the main database.
3) Based on session separation
This strategy is deeper than the dirty data separation strategy. It determines whether the user has modified the data. The user does not need to see the latest data of other users, only his own updates.
Specifically, a flag bit can be set in the session layer to indicate whether the user has made an update. Once the user makes an update, the user's query will be directed to the main database for a period of time.
This strategy is a good compromise between simplicity and effectiveness, and is a more recommended strategy.
Of course, if you have enough ideas, you can combine the session-based separation strategy with the replication latency monitoring strategy. If the user updated the data 10 seconds ago, and all standby database delays are within 5 seconds, you can boldly read data from the standby database. It should be noted that remember to select the same standby database for the entire session, otherwise once the delays of multiple standby databases are inconsistent, it will cause trouble to users.
4) Based on global version/session separation
Confirm whether the standby database has updated data by recording the log coordinates of the main database and comparing them with the copied coordinates of the standby database. When the application points to a write operation, after committing the transaction, perform a SHOW MASTER STATUS operation, and then store the master log coordinates in the cache as the version number of the modified object or session. When the application connects to the standby database, execute SHOW SLAVE STATUS and compare the coordinates on the standby database with the version number in the cache. If the standby database is newer than the main database record point, it means that the standby database has updated the corresponding data and can be used with confidence.
In fact, many read-write separation strategies require monitoring replication latency to determine the allocation of read queries. However, it should be noted that the value of the Seconds_behind_master column obtained by SHOW SLAVE STATUS does not accurately represent the delay. We can use the pt-heartbeat tool in the Percona Toolkit to better monitor latency.
For some relatively simple applications, DNS can be created for different purposes. The simplest method is to have one DNS name for the read-only server (read.mysql-db.com) and another DNS name for the server responsible for write operations (write.mysql-db.com). If the standby database can keep up with the primary database, point the read-only DNS name to the standby database, otherwise, point to the primary database.
This strategy is very easy to implement, but there is a big problem: it cannot fully control DNS.
This strategy is more dangerous. Even if the problem of unable to fully control DNS can be avoided by modifying the /etc/hosts file, it is still an ideal strategy.
Achieve load balancing by transferring virtual addresses between servers. Does it feel similar to modifying DNS? But in fact they are completely different things. Transferring the IP address allows the DNS name to remain unchanged. We can force the IP address change to be quickly and atomically notified to the local network through the ARP command (don't know about ARP, see here).
A more convenient technique is to assign a fixed IP address to each physical server. This IP address is fixed on the server and does not change. You can then use a virtual IP address for each logical "service" (which can be understood as a container).
In this way, IP can be easily transferred between servers without reconfiguring the application, and the implementation is easier.
The above strategies assume that the application is connected to the MySQL server, but many load balancing will introduce a middleware as a network Communication agent. It accepts all communications on one side, distributes these requests to the designated server on the other side, and sends the execution results back to the requesting machine. Figure 2 illustrates this architecture. 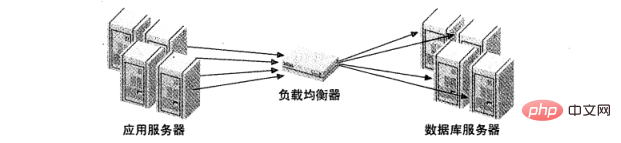
There are many load balancing hardware and software, but few are designed specifically for MySQL server. Web servers generally have a greater need for load balancing, so many general-purpose load balancing devices will support HTTP and have only a few basic features for other uses.
MySQL connections are just normal TCP/IP connections, so you can use a multi-purpose load balancer on MySQL. However, due to the lack of MySQL-specific features, there will be more restrictions:
There are many algorithms used to decide which server accepts the next connection. Each manufacturer has its own different algorithm, and the following common methods are:
Random allocation. A server is randomly selected from the available server pool to handle the request.
polling. Send requests to the server in a round-robin order, for example: A, B, C, A, B, C.
Hash. The connection's source IP address is hashed and mapped to the same server in the pool.
Fastest response. Allocate connections to the server that can handle the request fastest.
Minimum number of connections. Assign connections to the server with the fewest active connections.
Weights. According to the performance of the machine and other conditions, different weights are configured for different machines so that high-performance machines can handle more connections.
There is no best method among the above methods, only the most suitable, depending on the specific workload.
In addition, we only describe the algorithm for immediate processing. But sometimes it may be more efficient to use a queuing algorithm. For example, an algorithm might maintain a given database server concurrency, allowing no more than N active transactions at a time. If there are too many active transactions, new requests are put into a queue and let the list of available servers handle them.
The most common replication structure isone master database and multiple backup databases. This architecture has poor scalability, but we can combine it with load balancing through some methods to achieve better results.
We cannot and should not think about making the architecture like Alibaba at the beginning of the application. The best way is to implement what the application clearly needs today and plan ahead for possible rapid growth.
Also, it makes sense to have a numeric goal for scalability, just like we have a precise goal for performance, meeting 10K or 100K concurrency. This can avoid overhead issues such as serialization or interoperability from being brought into our applications through relevant theories.
In terms of MySQL expansion strategy, when a typical application grows to a very large size, it usually first moves from a single server to a scale-out architecture with standby databases, and then to data sharding or functional partitioning. It should be noted here that we do not advocate advice such as "shard as early as possible, shard as much as possible". In fact, sharding is complex and costly, and most importantly, many applications may not need it at all. Rather than spending a lot of money on sharding, it is better to take a look at the changes in new hardware and new versions of MySQL. Maybe these new changes will surprise you.
Summary
is a quantitative indicator of scalability.
[Related recommendations: mysql video tutorial]
The above is the detailed content of What is load balancing in mysql. For more information, please follow other related articles on the PHP Chinese website!









![MySQL query optimization solution [taught by architects from major manufacturers] [Getting Started with MySQL | Tuning | Indexing] Advanced Tutorial](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



