
 Technology peripherals
AI
What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is
Technology peripherals
AI
What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is
What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is

#Whether a machine can think about this question is like asking whether a submarine can swim. ——Dijkstra
Long before the release of ChatGPT, the industry had already smelled the changes brought about by large models.
On October 14 last year, professors Melanie Mitchell and David C. Krakauer of the Santa Fe Institute published a review on arXiv, comprehensively investigating all the Regarding the debate on whether large-scale pre-trained language models can understand language, the article describes the arguments for and against, as well as the key issues in the broader intelligence science derived from these arguments.

Paper link: https://arxiv.org/pdf/2210.13966.pdf
Published journal: "Academy of the National Academy of Sciences Newspaper" (PNAS)
Too long to read:
The main argument in support of "understanding" is that large language models can complete many seemingly Tasks that require understanding before they can be completed.
The main argument against "understanding" is that from a human perspective, the understanding of large language models is very fragile, such as being unable to understand subtle changes between prompts; and language models do not have real-world life experience To validate their knowledge, multimodal language models may alleviate this problem.
The most critical problem is that no one has a reliable definition of "what is understanding" yet, and they don't know how to test the understanding ability of language models for human The test is not necessarily suitable for testing the understanding of large language models.
In short, large language models can understand language, but perhaps in a different way than humans.
Researchers believe that a new science of intelligence can be developed that deeply studies different types of understanding, finds out the advantages and limitations of different understanding modes, and at the same time integrates the results produced by different forms of understanding. Cognitive differences.

# Melanie Mitchell, the first author of the paper, is a professor at the Santa Fe Institute. She received her Ph.D. in 1990 Graduated from the University of Michigan, her mentors were Hofstadter (author of "Gödel, Escher, Bach: A Collection of Different Masters") and John Holland. Her main research directions are analogical reasoning, complex systems, genetic algorithms and cells. Automata.
What exactly is "understanding"?
"What is understanding" has always puzzled philosophers, cognitive scientists and educators. Researchers often use humans or other animals as a reference for "understanding ability".
Until recently, with the rise of large-scale artificial intelligence systems, especially the emergence of large language models (LLM), a fierce debate has been set off in the artificial intelligence community, that is, now Can it be said that machines have been able to understand natural language and thus understand the physical and social situations described by language.
This is not a purely academic debate. The degree and way in which machines understand the world will have an impact on the extent to which humans can trust AI to perform tasks such as driving cars, diagnosing diseases, caring for the elderly, and educating children, so that in humans Take strong and transparent action on relevant tasks.
The current debate shows that there are some differences in how the academic community thinks about understanding in intelligent systems, especially in mental models that rely on "statistical correlation" and "causal mechanisms" (mental models), the differences are more obvious.
However, there is still a general consensus in the artificial intelligence research community about machine understanding, that is, although artificial intelligence systems exhibit seemingly intelligent behavior in many specific tasks, they are not Understand the data they process like humans do.
For example, facial recognition software does not understand that the face is part of the body, nor does it understand the role of facial expressions in social interactions, nor does it understand how humans act in nearly infinite ways. To use the facial concept.
Similarly, speech-to-text and machine translation programs don’t understand the language they process, and self-driving systems don’t understand the subtle eye contact or body language that drivers and pedestrians use to avoid accidents.
In fact, the oft-cited brittleness of these AI systems—unpredictable errors and lack of robust generalization—is a key metric in assessing AI understanding. .
Over the past few years, the audience and influence of large language models (LLMs) in the field of artificial intelligence have surged, and it has also changed some people's views on the prospects of machine understanding of language.
Large-scale pre-training models, also called foundation models, are deep neural networks with billions to trillions of parameters (weights). They are used in massive natural language corpora (including online texts, online books, etc.) Obtained after performing "pre-training" on.
The task of the model during training is to predict the missing parts of the input sentence, so this method is also called "self-supervised learning", and the resulting network is a complex statistical model , you can get how the words and phrases in the training data are related to each other.
This model can be used to generate natural language and fine-tuned for specific natural language tasks, or further trained to better match "user intent", but for non-professionals How exactly language models accomplish these tasks remains a mystery to scientists.
The inner workings of neural networks are largely opaque, and even the researchers who build them have limited intuition for systems of this scale.

After crossing a certain threshold, it’s as if aliens suddenly appear and can communicate with us in a terrifying, human way. Only one thing is clear at the moment, large language models are not human, some aspects of their behavior appear to be intelligent, but if not human intelligence, what is the nature of their intelligence?Support the understanding camp VS Oppose the understanding campAlthough the performance of large language models is shocking, the most advanced LLMs are still susceptible to brittleness and non-human error. However, it can be observed that the network performance has improved significantly with the expansion of its number of parameters and the size of the training corpus, which has also led some researchers in this field to claim that as long as there is a large enough The network and training data set, the language model (a multi-modal version) and perhaps the multi-modal version - will lead to human-level intelligence and understanding. A new artificial intelligence slogan has emerged: Scale is all you need! This statement also reflects the debate about large language models in the artificial intelligence research community: One group believes that language models can truly understand language , and can reason in a general way (although not yet to a human level). For example, Google’s LaMDA system is pre-trained on text and then fine-tuned on conversational tasks, enabling it to hold conversations with users in a very wide range of domains.

Machine understanding is different from humans
While both sides of the “LLM understanding” debate have ample intuition to support their respective views, there are currently available cognitive science-based insights into understanding. method is not sufficient to answer such questions about LLM.
In fact, some researchers have applied psychological tests (originally designed to assess human understanding and reasoning mechanisms) to LLMs and found that in some cases, LLMs do indeed think theoretically Demonstrated human-like responses on tests and human-like abilities and biases on reasoning assessments.
While these tests are considered reliable agents for assessing human generalization abilities, this may not be the case for artificial intelligence systems.
Large language models have a special ability to learn correlations between their training data and tokens in the input, and can use this correlation to solve problems; in contrast, humans Use condensed concepts that reflect their real-world experiences.
When applying tests designed for humans to LLMs, interpretation of the results may rely on assumptions about human cognition that may simply not be true for these models .
To make progress, scientists will need to develop new benchmarks and detection methods to understand the mechanisms of different types of intelligence and understanding, including the new forms of “bizarre” intelligence we have created. , mind-like entities", and some related work has already been done.
As models become larger and more capable systems are developed, the debate over understanding in LLMs highlights the need to "expand our science of intelligence" , so that "understanding" is meaningful, whether for humans or machines.
Neuroscientist Terrence Sejnowski points out that experts’ differing opinions on the intelligence of LLMs show that our old ideas based on natural intelligence are not enough.
If LLMs and related models can succeed by exploiting statistical correlations on an unprecedented scale, perhaps they can be considered a "new form of understanding", one that can achieve extraordinary forms of superhuman prediction capabilities, such as DeepMind's AlphaZero and AlphaFold systems, which bring an "exotic" form of intuition to the fields of chess playing and protein structure prediction respectively.
So it can be said that in recent years, the field of artificial intelligence has created machines with new modes of understanding, most likely a completely new concept, as we pursue the elusive goal of intelligence. As progress is made in essential aspects, these new concepts will continue to be enriched.
Problems that require extensive coding knowledge and have high performance requirements will continue to promote the development of large-scale statistical models, while those with limited knowledge and strong causal mechanisms will have Conducive to understanding human intelligence.
The challenge for the future is to develop new scientific methods to reveal the detailed understanding of different forms of intelligence, discern their strengths and limitations, and learn how to integrate these truly different cognitions model.
References:
https://www.pnas.org/doi/10.1073/pnas.2215907120
The above is the detailed content of What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 3 Ways to Change Language on iPhone
Feb 02, 2024 pm 04:12 PM
3 Ways to Change Language on iPhone
Feb 02, 2024 pm 04:12 PM
It's no secret that the iPhone is one of the most user-friendly electronic gadgets, and one of the reasons why is that it can be easily personalized to your liking. In Personalization, you can change the language to a different language than the one you selected when setting up your iPhone. If you're familiar with multiple languages, or your iPhone's language setting is wrong, you can change it as we explain below. How to Change the Language of iPhone [3 Methods] iOS allows users to freely switch the preferred language on iPhone to adapt to different needs. You can change the language of interaction with Siri to facilitate communication with the voice assistant. At the same time, when using the local keyboard, you can easily switch between multiple languages to improve input efficiency.
 How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
Installation steps: 1. Download the ChatGTP software from the ChatGTP official website or mobile store; 2. After opening it, in the settings interface, select the language as Chinese; 3. In the game interface, select human-machine game and set the Chinese spectrum; 4 . After starting, enter commands in the chat window to interact with the software.
 How to set the language of Win10 computer to Chinese?
Jan 05, 2024 pm 06:51 PM
How to set the language of Win10 computer to Chinese?
Jan 05, 2024 pm 06:51 PM
Sometimes we just install the computer system and find that the system is in English. In this case, we need to change the computer language to Chinese. So how to change the computer language to Chinese in the win10 system? Now Give you specific operation methods. How to change the computer language in win10 to Chinese 1. Turn on the computer and click the start button in the lower left corner. 2. Click the settings option on the left. 3. Select "Time and Language" on the page that opens. 4. After opening, click "Language" on the left. 5. Here you can set the computer language you want.
 How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
In this article, we will introduce how to develop intelligent chatbots using ChatGPT and Java, and provide some specific code examples. ChatGPT is the latest version of the Generative Pre-training Transformer developed by OpenAI, a neural network-based artificial intelligence technology that can understand natural language and generate human-like text. Using ChatGPT we can easily create adaptive chats
 Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
chatgpt can be used in China, but cannot be registered, nor in Hong Kong and Macao. If users want to register, they can use a foreign mobile phone number to register. Note that during the registration process, the network environment must be switched to a foreign IP.
 How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to use ChatGPTPHP to build an intelligent customer service robot Introduction: With the development of artificial intelligence technology, robots are increasingly used in the field of customer service. Using ChatGPTPHP to build an intelligent customer service robot can help companies provide more efficient and personalized customer services. This article will introduce how to use ChatGPTPHP to build an intelligent customer service robot and provide specific code examples. 1. Install ChatGPTPHP and use ChatGPTPHP to build an intelligent customer service robot.
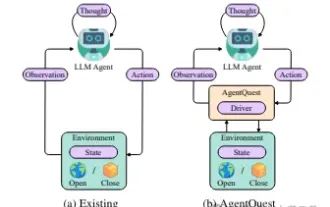 Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Apr 11, 2024 pm 08:52 PM
Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Apr 11, 2024 pm 08:52 PM
Based on the continuous optimization of large models, LLM agents - these powerful algorithmic entities have shown the potential to solve complex multi-step reasoning tasks. From natural language processing to deep learning, LLM agents are gradually becoming the focus of research and industry. They can not only understand and generate human language, but also formulate strategies, perform tasks in diverse environments, and even use API calls and coding to Build solutions. In this context, the introduction of the AgentQuest framework is a milestone. It not only provides a modular benchmarking platform for the evaluation and advancement of LLM agents, but also provides researchers with a Powerful tools to track and improve the performance of these agents at a more granular level
