
 Technology peripherals
AI
GPT-4's ability greatly increased after 'self-reflection', and test performance increased by 30%
Technology peripherals
AI
GPT-4's ability greatly increased after 'self-reflection', and test performance increased by 30%
GPT-4's ability greatly increased after 'self-reflection', and test performance increased by 30%


News on April 4th, OpenAI’s latest language model GPT-4 is not only able to generate various texts like humans , also able to design and execute tests to evaluate and improve their performance. This "reflection" technology has allowed GPT-4 to achieve significant improvements in many difficult tests, with test performance improved by 30%.
GPT-4 is the most advanced system launched by OpenAI after GPT, GPT-2 and GPT-3, and is currently the largest multi-modal model (can accept image and text input and output text). It leverages deep learning technology, using artificial neural networks to imitate human writing.
Researchers Noah Shinn and Ashwin Gopinath wrote in the paper: "We have developed a novel technology that allows AI agents to Simulate human self-reflection and evaluate one's own performance. When completing various tests, GPT-4 will add some extra steps, allowing it to design its own tests to check its own answers and identify errors and deficiencies. Then modify your solution based on your findings."
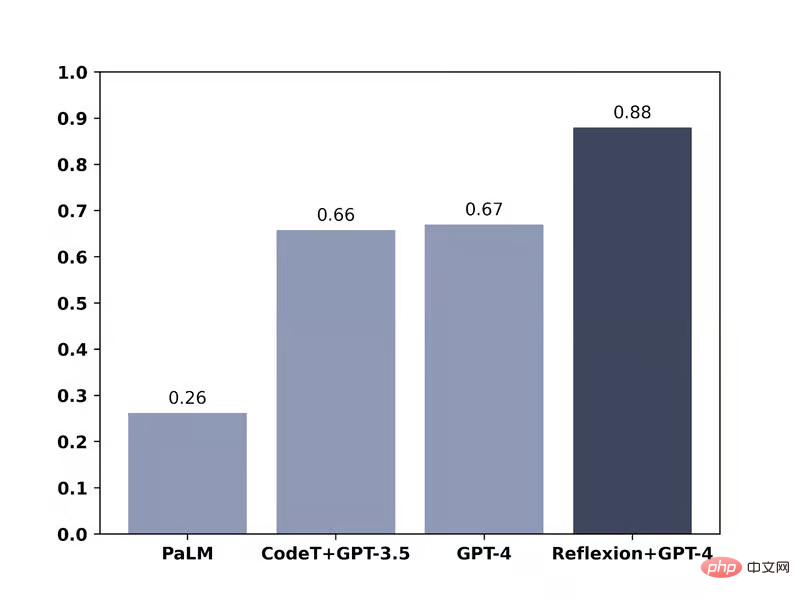
In the HumanEval coding test, GPT-4 used a self-reflection loop, and the accuracy increased from 67% to 88%
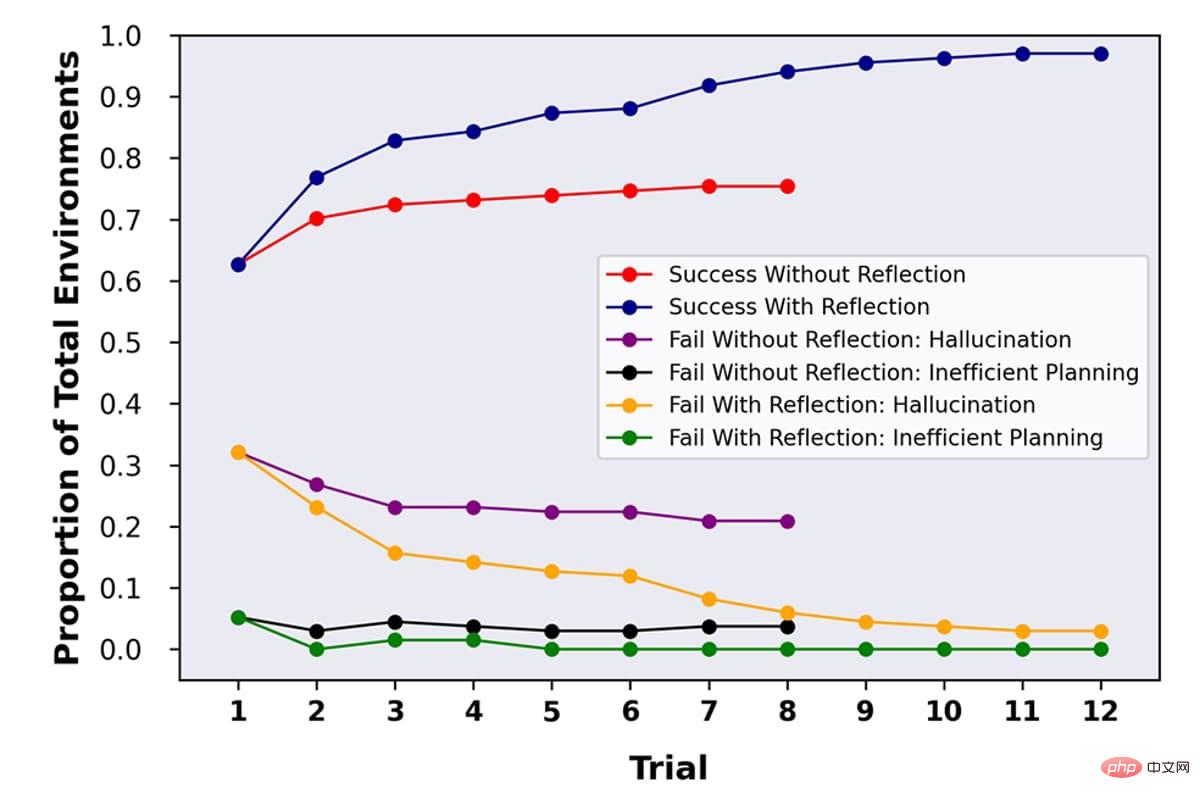
GPT-4 can be designed and executed to critique its own performance, and as shown in the AlfWorld test results, its performance can be greatly improved
Research The team used this technique to conduct several different performance tests on GPT-4. In the HumanEval test, GPT-4 needed to solve 164 never-before-seen Python programming problems. The original accuracy was 67%. After using reflection technology, the accuracy increased to 88%. In the Alfworld test, the AI needs to make decisions and solve multi-step tasks by performing a number of allowed operations in a variety of different interactive environments. After using reflection techniques, GPT-4's accuracy increased from 73% to 97%, with only 4 task failures. In the HotPotQA test, GPT-4 accessed Wikipedia and answered 100 questions that required parsing content and reasoning from multiple supporting documents. The original accuracy was 34%. After using reflection technology, the accuracy increased to 54%.
This research shows that solutions to AI problems sometimes rely on AI itself. IT House found that this is a bit like a generative adversarial network, which is a method for two AIs to improve each other's skills. For example, one AI tries to generate some pictures that look like real pictures, and the other AI tries to distinguish which ones are fake. Which ones are true. But in this case, GPT is both a writer and an editor, using self-reflection to improve the quality of his or her output.
The above is the detailed content of GPT-4's ability greatly increased after 'self-reflection', and test performance increased by 30%. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
OpenAI recently announced the launch of their latest generation embedding model embeddingv3, which they claim is the most performant embedding model with higher multi-language performance. This batch of models is divided into two types: the smaller text-embeddings-3-small and the more powerful and larger text-embeddings-3-large. Little information is disclosed about how these models are designed and trained, and the models are only accessible through paid APIs. So there have been many open source embedding models. But how do these open source models compare with the OpenAI closed source model? This article will empirically compare the performance of these new models with open source models. We plan to create a data
 A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
In 2023, AI technology has become a hot topic and has a huge impact on various industries, especially in the programming field. People are increasingly aware of the importance of AI technology, and the Spring community is no exception. With the continuous advancement of GenAI (General Artificial Intelligence) technology, it has become crucial and urgent to simplify the creation of applications with AI functions. Against this background, "SpringAI" emerged, aiming to simplify the process of developing AI functional applications, making it simple and intuitive and avoiding unnecessary complexity. Through "SpringAI", developers can more easily build applications with AI functions, making them easier to use and operate.
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Author丨Compiled by TimAnderson丨Produced by Noah|51CTO Technology Stack (WeChat ID: blog51cto) The Zed editor project is still in the pre-release stage and has been open sourced under AGPL, GPL and Apache licenses. The editor features high performance and multiple AI-assisted options, but is currently only available on the Mac platform. Nathan Sobo explained in a post that in the Zed project's code base on GitHub, the editor part is licensed under the GPL, the server-side components are licensed under the AGPL, and the GPUI (GPU Accelerated User) The interface) part adopts the Apache2.0 license. GPUI is a product developed by the Zed team
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
Regarding Llama3, new test results have been released - the large model evaluation community LMSYS released a large model ranking list. Llama3 ranked fifth, and tied for first place with GPT-4 in the English category. The picture is different from other benchmarks. This list is based on one-on-one battles between models, and the evaluators from all over the network make their own propositions and scores. In the end, Llama3 ranked fifth on the list, followed by three different versions of GPT-4 and Claude3 Super Cup Opus. In the English single list, Llama3 overtook Claude and tied with GPT-4. Regarding this result, Meta’s chief scientist LeCun was very happy and forwarded the tweet and
 The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The volume is crazy, the volume is crazy, and the big model has changed again. Just now, the world's most powerful AI model changed hands overnight, and GPT-4 was pulled from the altar. Anthropic released the latest Claude3 series of models. One sentence evaluation: It really crushes GPT-4! In terms of multi-modal and language ability indicators, Claude3 wins. In Anthropic’s words, the Claude3 series models have set new industry benchmarks in reasoning, mathematics, coding, multi-language understanding and vision! Anthropic is a startup company formed by employees who "defected" from OpenAI due to different security concepts. Their products have repeatedly hit OpenAI hard. This time, Claude3 even had a big surgery.
