

Let's talk about image recognition: Recurrent Neural Network

This article is reproduced from the WeChat public account "Living in the Information Age". The author lives in the information age. To reprint this article, please contact the Living in the Information Age public account.
Recurrent Neural Network (RNN) is mainly used to solve sequence data problems. The reason why it is a recurrent neural network is that the current output of a sequence is also related to the previous output. The RNN network remembers information from previous moments and applies it to the current output calculation. Unlike the convolutional neural network, the neurons in the hidden layers of the recurrent neural network are connected to each other. The input of the neurons in the hidden layer is determined by the input The output of the layer is composed of the output of the hidden neurons at the previous moment. Although the RNN network has achieved some remarkable results, it has some shortcomings and limitations, such as: high training difficulty, low accuracy, low efficiency, long time, etc. Therefore, some improved network models based on RNN have been gradually developed, such as : Long Short-Term Memory (LSTM), bidirectional RNN, bidirectional LSTM, GRU, etc. These improved RNN models have shown outstanding results in the field of image recognition and are widely used. Taking the LSTM network as an example, we will introduce its main network structure.
Long Short-Term Memory (LSTM) solves the problems of gradient disappearance or gradient explosion in RNN and can learn long-term dependence problems. Its structure is as follows.
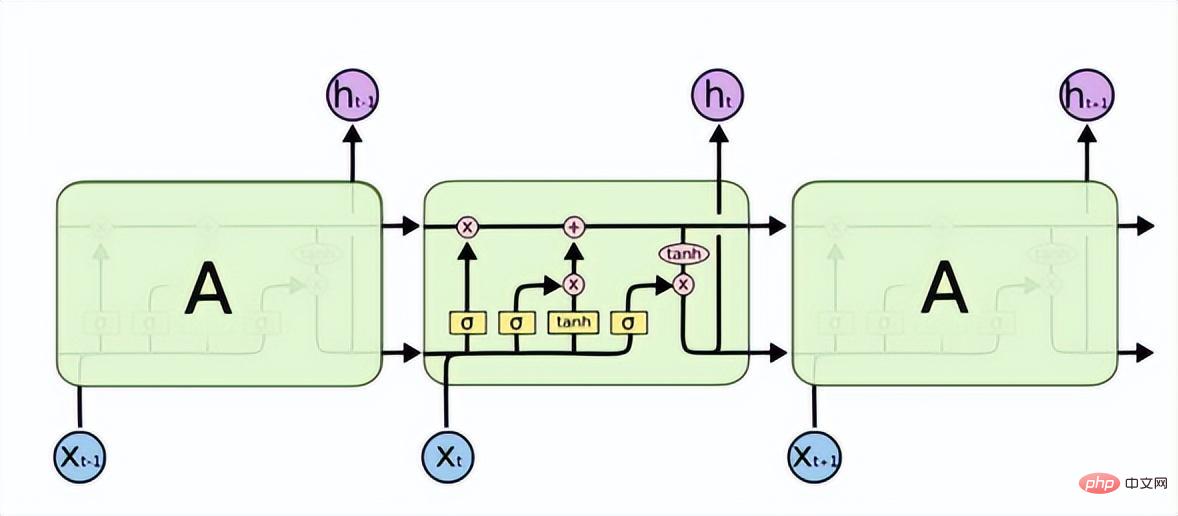
LSTM has three gates to allow information to selectively pass through: forgetting gate, input gate, and output gate. The forgetting gate determines what information can pass through this cell. It is implemented through a sigmoid neural layer. Its input is, and the output is a vector with a value between (0, 1), representing the proportion of each part of the information that is allowed to pass through. 0 means "let no information pass", 1 means "let all information pass".
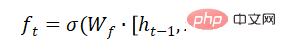
The input gate determines how much new information is added to the cell state. A tanh layer generates a vector, which is the alternative to update content.
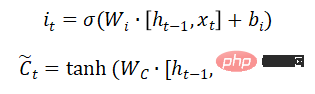
Update cell status:
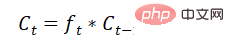
The output gate is being determined Which part of the information is output:
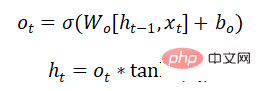
The GRU network model also solves the problems of gradient disappearance or gradient explosion in RNN, and can learn long-term dependencies Relationship is a deformation of LSTM. The structure is simpler than LSTM, has fewer parameters, and the training time is shorter than LSTM. It is also widely used in speech recognition, image description, natural language processing and other scenarios.
The above is the detailed content of Let's talk about image recognition: Recurrent Neural Network. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
Windows are never one to neglect aesthetics. From the bucolic green fields of XP to the blue swirling design of Windows 11, default desktop wallpapers have been a source of user delight for years. With Windows Spotlight, you now have direct access to beautiful, awe-inspiring images for your lock screen and desktop wallpaper every day. Unfortunately, these images don't hang out. If you have fallen in love with one of the Windows spotlight images, then you will want to know how to download them so that you can keep them as your background for a while. Here's everything you need to know. What is WindowsSpotlight? Window Spotlight is an automatic wallpaper updater available from Personalization > in the Settings app
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
With the continuous development of artificial intelligence technology, image semantic segmentation technology has become a popular research direction in the field of image analysis. In image semantic segmentation, we segment different areas in an image and classify each area to achieve a comprehensive understanding of the image. Python is a well-known programming language. Its powerful data analysis and data visualization capabilities make it the first choice in the field of artificial intelligence technology research. This article will introduce how to use image semantic segmentation technology in Python. 1. Prerequisite knowledge is deepening
 How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
Those who have to work with image files on a daily basis often have to resize them to fit the needs of their projects and jobs. However, if you have too many images to process, resizing them individually can consume a lot of time and effort. In this case, a tool like PowerToys can come in handy to, among other things, batch resize image files using its image resizer utility. Here's how to set up your Image Resizer settings and start batch resizing images with PowerToys. How to Batch Resize Images with PowerToys PowerToys is an all-in-one program with a variety of utilities and features to help you speed up your daily tasks. One of its utilities is images
 iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
With the iOS 17 Photos app, Apple makes it easier to crop photos to your specifications. Read on to learn how. Previously in iOS 16, cropping an image in the Photos app involved several steps: Tap the editing interface, select the crop tool, and then adjust the crop using a pinch-to-zoom gesture or dragging the corners of the crop tool. In iOS 17, Apple has thankfully simplified this process so that when you zoom in on any selected photo in your Photos library, a new Crop button automatically appears in the upper right corner of the screen. Clicking on it will bring up the full cropping interface with the zoom level of your choice, so you can crop to the part of the image you like, rotate the image, invert the image, or apply screen ratio, or use markers
 How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
Mobile photography has fundamentally changed the way we capture and share life’s moments. The advent of smartphones, especially the iPhone, played a key role in this shift. Known for its advanced camera technology and user-friendly editing features, iPhone has become the first choice for amateur and experienced photographers alike. The launch of iOS 17 marks an important milestone in this journey. Apple's latest update brings an enhanced set of photo editing features, giving users a more powerful toolkit to turn their everyday snapshots into visually engaging and artistically rich images. This technological development not only simplifies the photography process but also opens up new avenues for creative expression, allowing users to effortlessly inject a professional touch into their photos
