

Counting the stars and hoping for the moon, thousands of Jay fans have been waiting for 6 years. Not long ago, Jay Chou finally released a new album! Once it went online, it sparked discussions across the Internet.
While everyone was immersed in the beautiful memories of those lush years, the friend who posted the viral audio said: This conversation was actually speech synthesis!
When it comes to "speech synthesis", the following may appear in your mind:
• Navigation has a rich variety but mechanical tone of "turn left at the intersection ahead"
• ‐ ‐‐ Credit Card Center "
•信 信, ten commentary videos have the same sounds in the same, and when you see it, you want to quickly draw away. "Little Handsome"...
Now it has directly subverted many people's stereotypes. Speech synthesis technology can already achieve the same perfect and natural effect as the audio above. The publisher of this audio -Volcano Voice, ByteDance AI Lab Speech & Audio Intelligent Speech and Audio Team, and through two pieces of audio, we can better decipher the technical highlights to the public.
The text entered in these sentences is exactly the same, that is, "Southern cuisine prefers dipping sauces. For example, it was my first time in Shanghai that I learned that vegetables in barbecue also need to be served with dipping sauces." But The synthesized audio effect is obviously different, that is, the second audio is derived from the new supernatural dialogue speech synthesis technology launched by the Volcano Voice Team this time.Recall the state of people's daily expressions. The brain needs thinking time to process information. When it comes to language, people will involuntarily hesitate, pronunciation, inversion, or even change their words mid-sentence, stutter and repeat. They will also deliberately emphasize pronunciation to emphasize the key information they want to express. This brings about a large number of subtle expressions that are difficult to observe. These phenomena are difficult to capture and restore in traditional TTS. The perfect reproduction of these subtleties is the source of the mystery that makes it difficult to distinguish the authenticity of the sound, and is also the mystery of the above-mentioned audio.
Specifically,
The latest supernatural dialogue speech synthesis technology released by the Volcano Voice Team is more realistic and natural than traditional TTS, that is, modal particles Details such as inhalation sounds, pauses during hesitation, and pronunciation of pronunciation are all perfectly reproduced. And only 1/4 of the data of the conventional sound library can be used to perfectly restore the subtle rhythmic characteristics and pronunciation habits of real people, allowing you to Compositing effects are more realistic. Professional evaluation results show that there is basically no difference between this new technology of Huoshan Voice and real-person recordings, and it is difficult for reviewers to distinguish it. In addition, this technology has been put into use in many scenarios such as video dubbing and telephone customer service. It will be launched on the official website of Volcano Engine Voice Technology in the near future.
According to reports, the above-mentioned manifestations such as gasping, swallowing, involuntary prolongation of word pronunciation when thinking, and low laughter that often occur in actual communication have been It is called paralinguistic phenomenon (paralanguage). Although this is the most realistic manifestation of the human brain's thinking and expression process, because the traditional speech synthesis technology framework cannot effectively model sparsely distributed paralinguistic phenomena, so in The restoration of rhythm when speaking is limited and too "correct".
Based on the above difficulties, the Volcano Voice supernatural speech synthesis technology makes breakthroughs from two levels:text and speech modeling. Specifically, :
# •On the text level, the volcanic voice uses ingredient style migration model , and the way of simulating people can speak text. Controlled colloquial transliteration allows the text to better embrace colloquialism and avoid the final effect being too written.
• At the speech level, the team has made a breakthrough in the text analysis model and added an additional paralanguage prediction to the input side of TTS. , imitating the pronunciation characteristics of real people to achieve natural and spontaneous speech effects. It is worth mentioning that the team effectively improved the stability and expressiveness of the model by using the TTS modeling solution with unsupervised features, using only 1/4 of the data scale of conventional sound libraries. You can achieve very natural and changeable rhythmic effects, isn’t it great? Text is the input of speech synthesis technology. Whether its style is close to the expression of real people is the first step to improve the synthesis effect. However, due to deep-rooted writing habits, most pre-synthesis texts are not natural enough. , or it requires a lot of effort and constant adjustment, which is time-consuming and labor-intensive. In order to solve such problems, the Huoshan Voice team adopted a two-stage solution and achieved good results: Phase One: Adoption The self-supervised method uses pseudo data to pre-train the spoken language model, which reduces the amount of data required; at the same time, a pointer network structure is introduced into the model to enhance text controllability. Phase 2: Use a small amount of high-quality manually labeled data to fine-tune the pre-trained spoken language model, and finally achieve controllable and natural spoken language text effects.
Well, for southern cuisine, I prefer to use dipping sauce or something, For exampleMy first timeuh, my first time went to Shanghai, and I realized that the vegetables in the barbecue must also be accompanied by dipping sauce
, the northerners said I brought half a cart of cabbage In fact, southern cuisine places more emphasis on the taste of seasonings, that is, the chef uses seasonings to display his skills Yes, in fact, southern cuisine pays more attention to the taste of its seasonings. In other words, the chef uses seasonings to display his skills In order to better restore real people, it is different from traditional In terms of speech synthesis technology, Huoshan Speech has also conducted in-depth research on paralanguage modeling and prosodic diversity respectively. In terms of paralanguage modeling, the synthesis technology introduced by the team enables the acoustic model to model a variety of paralinguistic phenomena such as inhalation, laughter, hesitation, and correction that appear in natural expressions, and combines it with text Semantic information is automatically inserted into paralinguistic phenomena . Consider rationality and randomness at the same time during the insertion process, making the performance more natural and real.
Inhale>It’s actually very good for the body. C.wav ## Look at our current work, in the morning extended >Basically I don’t eat much breakfast. #Audio D.wav ##AudioE.wav Slip correction##>, I really want to eat meat. # Copy of ##.wav Huoshan Voice, ByteDance AI Lab Speech&Audio intelligent voice and audio team, has long been serving Douyin, Jianying, Tomato Novels, and Feishu Other businesses provide leading AI voice technology capabilities and full-stack voice product solutions, and open technical services to external enterprises through the Volcano Engine. 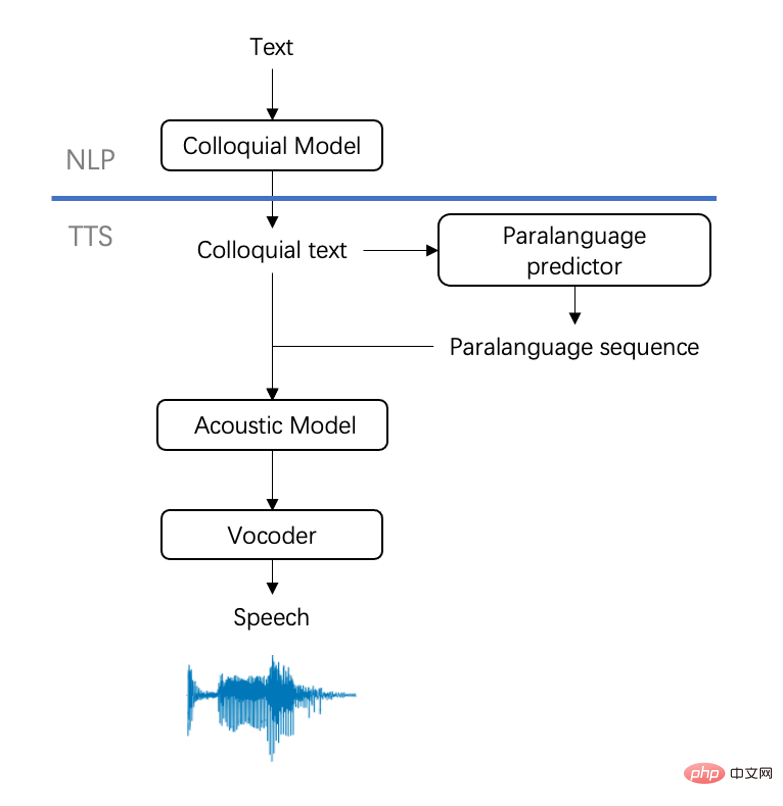
## Committed to colloquial text, making "real-person expression" vivid on the page
##Text after automated prediction
## Southern cuisine prefers dipping sauces, such as mine It was my first time in Shanghai that I learned that vegetables in barbecue also need to be served with dipping sauce
##Well this It’s almost like
The rhythmic diversity of paralanguage modeling is remarkable and the voice realism has been fully upgraded
## Like our morning basically
In the exploration of prosody diversification, we combined unsupervised representation learning technology and independently developed a highly expressive acoustic model framework. Through pronunciation, rhythm, and timbre decoupling, we not only It reduces the demand for data volume and achieves efficient modeling of extremely low-frequency pronunciation phenomena. At the same time, it uses unsupervised representation features and combines phoneme-level fundamental frequency and energy information to achieve natural changes in prosody and promote high-quality dialogue. Speech generation,” concluded the Volcano Voice team.
##“
ParalangTest_is_000008_npy_01_new2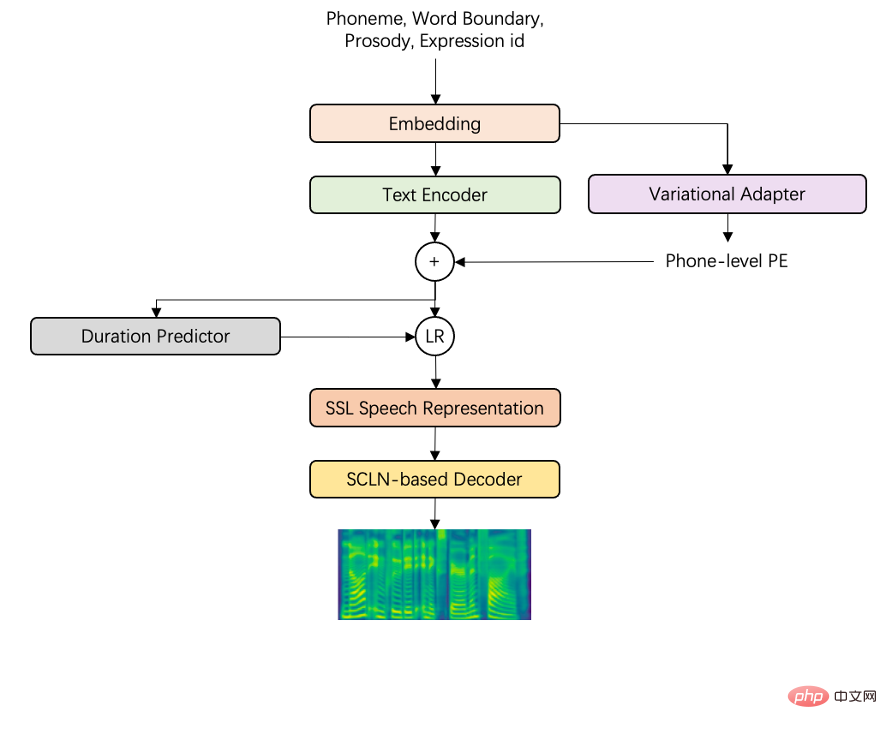
The above is the detailed content of Only 1/4 the amount of data is used to restore 100% details of real-life voices, using the latest supernatural dialogue speech synthesis technology on Volcano Voice!. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



