
 Technology peripherals
AI
Google has created a machine translation system for 1,000+ 'long tail' languages and already supports some niche languages.
Technology peripherals
AI
Google has created a machine translation system for 1,000+ 'long tail' languages and already supports some niche languages.
Google has created a machine translation system for 1,000+ 'long tail' languages and already supports some niche languages.

The quality of academic and commercial machine translation systems (MT) has improved dramatically over the past decade. These improvements are largely due to advances in machine learning and the availability of large-scale web mining datasets. At the same time, the emergence of deep learning (DL) and E2E models, large-scale parallel single-language data sets obtained from web mining, data enhancement methods such as back-translation and self-training, and large-scale multi-language modeling have brought about the ability to support more than 100 High-quality machine translation system for languages.
However, despite the huge progress in low-resource machine translation, the number of languages for which widely available and general machine translation systems have been built is limited to about 100, which are obviously only the most comprehensive ones today. A few of the more than 7,000 languages spoken in the world. In addition to the limited number of languages, the distribution of languages supported by current machine translation systems is also greatly tilted towards European languages.
We can see that despite their large populations, there are fewer services for languages spoken in Africa, South and Southeast Asia, and Native American languages. For example, Google Translate supports Frisian, Maltese, Icelandic, and Corsican, all of which have fewer than 1 million native speakers. By comparison, the Bihar dialect population not served by Google Translate is about 51 million, the Oromo population is about 24 million, the Quechua population is about 9 million, and the Tigrinya population is about 9 million (2022). These languages are known as "long tail" languages, and the lack of data requires the application of machine learning techniques that can generalize beyond languages with sufficient training data.
Building machine translation systems for these long-tail languages is largely limited by the lack of available digitized data sets and NLP tools such as language identification (LangID) models. These are ubiquitous for high-resource languages.
In a recent Google paper "Building Machine Translation Systems for the Next Thousand Languages", more than two dozen researchers demonstrated their efforts to build practical machines that support more than 1,000 languages. Translation system results.

Paper address: https://arxiv.org/pdf/2205.03983.pdf
Specific Specifically, the researchers describe their results from the following three research areas.
First, a clean, web-mined dataset is created for 1500 languages through semi-supervised pre-training for language recognition and data-driven filtering techniques.
Second, through large-scale multilingual models trained with supervised parallel data for more than 100 high-resource languages, as well as monolingual datasets for 1,000 additional languages. Create machine translation models that actually work for underserved languages.
Third, study the limitations of evaluation metrics for these languages, conduct a qualitative analysis of the output of machine translation models, and focus on several common error patterns of such models.
We hope this work will provide useful insights to practitioners working on building machine translation systems for currently under-researched languages. In addition, the researchers hope that this work can lead to research directions that address the weaknesses of large-scale multilingual models in data sparse settings.
At the I/O conference on May 12, Google announced that its translation system has added 24 new languages, including some niche Native American languages. For example, the Bihar dialect, Oromo, Quechua and Tigrinya mentioned above.

Paper Overview
This work is mainly divided into four major chapters. Here we only discuss each chapter. The contents of each chapter are briefly introduced.
Create a 1000-language web text data set
This chapter details the researcher’s efforts to crawl single-language text data for 1500 languages method used in the collection process. These methods focus on recovering high-precision data (i.e., a high proportion of clean, in-language text), so a large part are various filtering methods.
In general, the methods used by researchers include the following:
- Remove languages with poor training data quality and poor LangID performance from the LangID model, and train a 1629-language CLD3 LangID model and semi-supervised LangID (SSLID) model;
- Perform clustering operation based on the error rate of language in the CLD3 model;
- Use the CLD3 model to perform the first round of web crawling;
- Filter sentences using document consistency;
- Filter all corpora using a percentage threshold word list;
- Use semi-supervised LangID (SSLID ) Filter all corpora;
- Use relative recall to detect outlier languages and filter using Term-Frequency-Inverse-Internet-Frequency (TF-IIF) ;
- Use Token-Frequency Anomalousness scores to detect outlier languages and manually design filters for them;
- Face all corpora at the sentence level Perform deduplication operations.
The following is a histogram of document consistency scores on web text using the CLD3 LangID model of 1745-language.
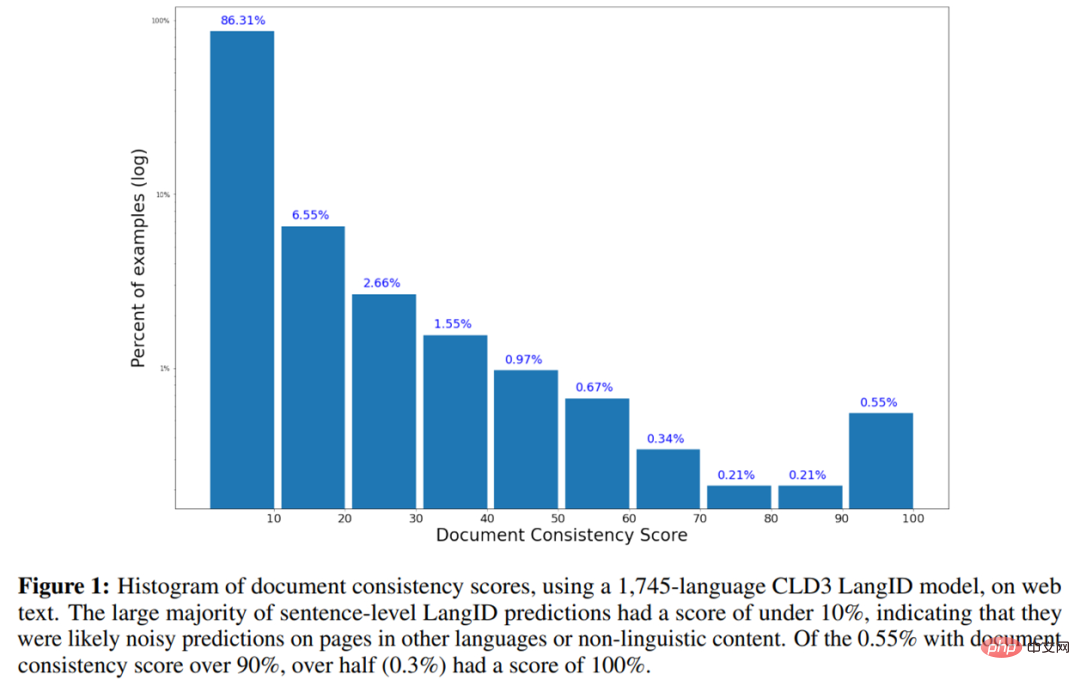
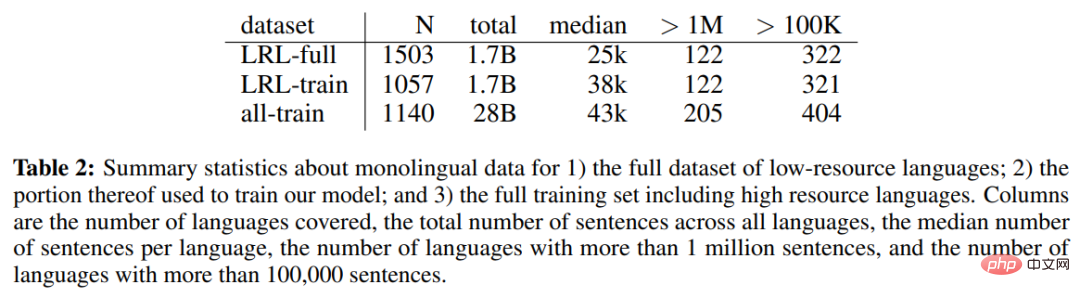
Table 2 below shows the single-language data of the complete low-resource language (LRL) data set, part of the single-language data used to train the model, and includes Single-language statistics for the complete training set including high-resource languages.
The chapter directory is as follows:

is a long-tail language Building a machine translation model
For monolingual data mined from the web, the next challenge is to create a high-quality general machine translation model from a limited amount of monolingual training data. To this end, the researchers adopted a pragmatic approach of leveraging all parallel data available for higher-resource languages to improve the quality of long-tail languages where only monolingual data is available. They call this setup "zero-resource" because there is no direct oversight for long-tail languages.
Researchers have used several techniques developed for machine translation over the past few years to improve the quality of zero-resource translation of long-tail languages. These techniques include self-supervised learning from monolingual data, large-scale multilingual supervised learning, large-scale back-translation, and self-training of high-capacity models. They used these tools to create a machine translation model capable of translating 1,000 languages, leveraging existing parallel corpora covering approximately 100 languages and a 1,000-language monolingual dataset built from the web.
Specifically, the researchers first emphasized the importance of model capacity in highly multilingual models by comparing the performance of 1.5 billion and 6 billion parameter Transformers on zero-resource translation (3.2) , and then increased the number of self-supervised languages to 1000, verifying that as more monolingual data from similar languages becomes available, performance improves for most long-tail languages (3.3). While the researchers' 1000-language model demonstrated reasonable performance, they incorporated large-scale data augmentation to understand the strengths and limitations of their approach.
In addition, the researchers fine-tuned the generative model on a subset of 30 languages containing a large amount of synthetic data through self-training and back-translation (3.4). They further describe practical methods for filtering synthetic data to enhance the robustness of these fine-tuned models to hallucinations and incorrect language translation (3.5).
We also used sequence-level distillation to refine these models into smaller, easier-to-reason architectures and highlighted the performance gap between teacher and student models (3.6).
The chapter directory is as follows:

Assessment
To evaluate their machine translation model, the researchers first translated English sentences into these languages and constructed an evaluation set (4.1) for the 38 selected long-tail languages. They highlight the limitations of BLEU in long-tail settings and evaluate these languages using CHRF (4.2).
The researchers also proposed an approximate reference-free metric based on round-trip translation to understand the quality of the model in languages where the reference set is not available, and The quality of the model as measured by this metric is reported (4.3). They performed human evaluation of the model on a subset of 28 languages and reported the results, confirming that it is possible to build useful machine translation systems following the approach described in the paper (4.4).
In order to understand the weaknesses of large-scale multilingual zero-resource models, researchers conducted qualitative error analysis on several languages. It was found that the model often confused words and concepts that were similar in distribution, such as "tiger" became "small crocodile" (4.5). And under lower resource settings (4.6), the model's ability to translate tokens decreases on tokens that appear less frequently.
The researchers also found that these models often cannot accurately translate short or single-word input (4.7). Research on refined models shows that all models are more likely to amplify bias or noise present in the training data (4.8).
The chapter table of contents is as follows:

##Additional experiments and notes
The researchers conducted some additional experiments on the above models, showing that they generally perform better at directly translating between similar languages without using English as a pivot (5.1), and that they can be used between different scripts Zero-sample transliteration of (5.2).
They describe a practical technique for appending terminal punctuation to any input, called the period trick, which can be used to improve translation quality (5.3) .
Additionally, we demonstrate that these models are robust to the use of non-standard Unicode glyphs in some but not all languages (5.4), and explore several non-Unicode fonts. (5.5).
The chapter list is as follows:

For more research details, please refer to the original paper.
The above is the detailed content of Google has created a machine translation system for 1,000+ 'long tail' languages and already supports some niche languages.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 How to comment deepseek
Feb 19, 2025 pm 05:42 PM
How to comment deepseek
Feb 19, 2025 pm 05:42 PM
DeepSeek is a powerful information retrieval tool. Its advantage is that it can deeply mine information, but its disadvantages are that it is slow, the result presentation method is simple, and the database coverage is limited. It needs to be weighed according to specific needs.
 How to search deepseek
Feb 19, 2025 pm 05:39 PM
How to search deepseek
Feb 19, 2025 pm 05:39 PM
DeepSeek is a proprietary search engine that only searches in a specific database or system, faster and more accurate. When using it, users are advised to read the document, try different search strategies, seek help and feedback on the user experience in order to make the most of their advantages.
 Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
This article introduces the registration process of the Sesame Open Exchange (Gate.io) web version and the Gate trading app in detail. Whether it is web registration or app registration, you need to visit the official website or app store to download the genuine app, then fill in the user name, password, email, mobile phone number and other information, and complete email or mobile phone verification.
 Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can’t the Bybit exchange link be directly downloaded and installed? Bybit is a cryptocurrency exchange that provides trading services to users. The exchange's mobile apps cannot be downloaded directly through AppStore or GooglePlay for the following reasons: 1. App Store policy restricts Apple and Google from having strict requirements on the types of applications allowed in the app store. Cryptocurrency exchange applications often do not meet these requirements because they involve financial services and require specific regulations and security standards. 2. Laws and regulations Compliance In many countries, activities related to cryptocurrency transactions are regulated or restricted. To comply with these regulations, Bybit Application can only be used through official websites or other authorized channels
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
It is crucial to choose a formal channel to download the app and ensure the safety of your account.
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
To access the latest version of Binance website login portal, just follow these simple steps. Go to the official website and click the "Login" button in the upper right corner. Select your existing login method. If you are a new user, please "Register". Enter your registered mobile number or email and password and complete authentication (such as mobile verification code or Google Authenticator). After successful verification, you can access the latest version of Binance official website login portal.
