
 Technology peripherals
AI
Datasets and driving perception in repetitive and challenging weather conditions
Technology peripherals
AI
Datasets and driving perception in repetitive and challenging weather conditions
Datasets and driving perception in repetitive and challenging weather conditions

arXiv paper "Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions", uploaded on August 1, 22, work from Cornell and Ohio State universities.

In recent years, the perception capabilities of autonomous vehicles have improved due to the use of large-scale data sets, which are often collected in specific locations and under good weather conditions. However, in order to meet high safety requirements, these sensing systems must operate robustly in various weather conditions, including snow and rain conditions.
This article proposes a data set to achieve robust autonomous driving, using a new data collection process, that is, in different scenarios (cities, highways, rural areas, campuses), weather (snow, rain, sun), time Data were recorded repeatedly along a 15 km route under (day/night) and traffic conditions (pedestrians, cyclists and cars).
The dataset includes images and point clouds from cameras and lidar sensors, as well as high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations, local occlusions and 3-D bounding boxes captured with amodal masks.
Repeated paths open up new research directions for target discovery, continuous learning, and anomaly detection.
Ithaca365 link: A new dataset to enable robust autonomous driving via a novel data collection process
The picture shows the sensor configuration of data collection:
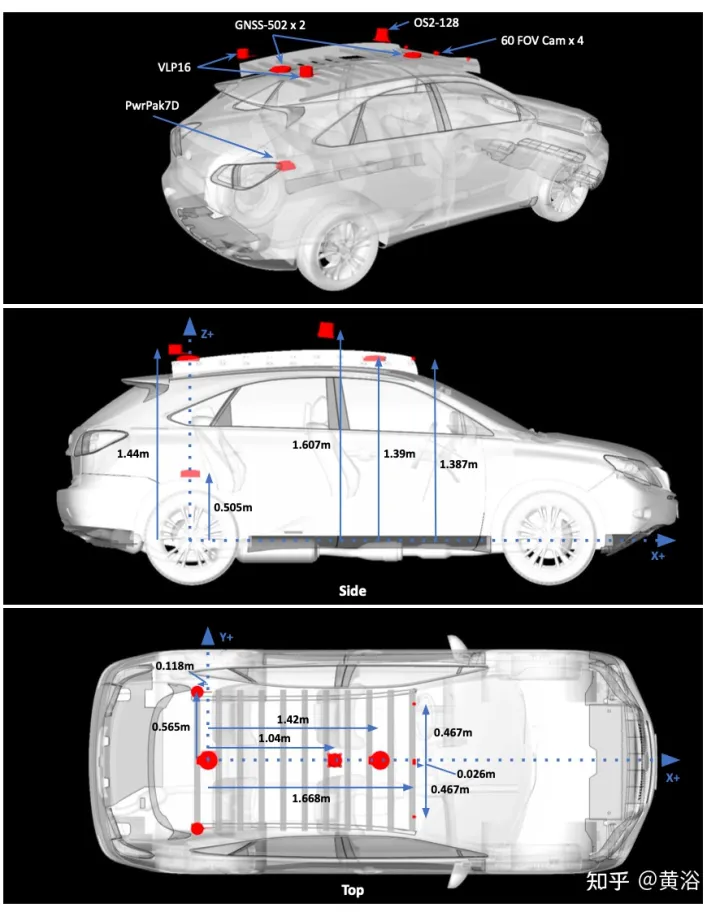
Figure a shows the route map with images captured at multiple locations. Drives were scheduled to collect data at different times of the day, including at night. Record heavy snow conditions before and after road clearing.
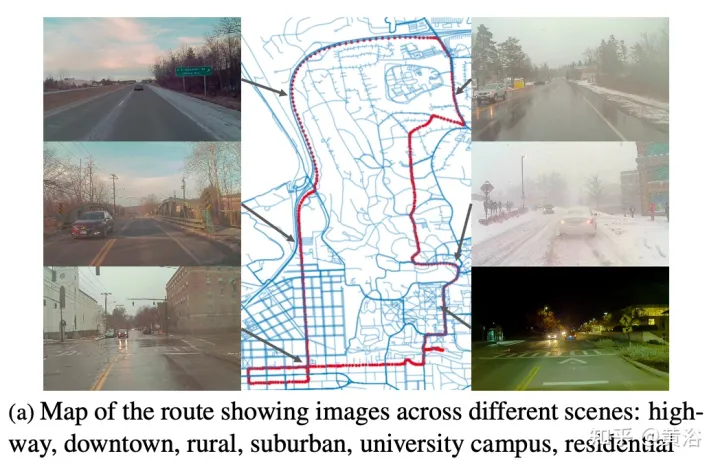
A key feature of the dataset is that the same locations can be observed under different conditions; an example is shown in Figure b.

The figure shows the traversal analysis under different conditions:
Develop a custom marking tool , used to obtain amodal masks of roads and objects. For road labels under different environmental conditions, such as snow-covered roads, use repeated traversals of the same route. Specifically, the point cloud road map constructed from GPS attitude and lidar data converts the road label of "good weather" into "bad weather".
Routes/data are divided into 76 intervals. Project the point cloud into BEV and label the road using polygon annotator. Once the road is marked in BEV (generating a 2-D road boundary), the polygon is decomposed into smaller 150 m^2 polygons, using a threshold of 1.5 m average height, and a plane fit is done to the points within the polygon boundary to determine the road height. .
Use RANSAC and a regressor to fit a plane to these points; then use the estimated ground plane to calculate the height of each point along the boundary. Project the road points into the image and create a depth mask to obtain the non-modal label of the road. Matching locations to marked maps with GPS and optimizing routes with ICP can project ground planes to specific locations on new collection routes.
A final check on the ICP solution by verifying that the average projected ground truth mask of the road label conforms to 80% mIOU with all other ground truth masks at the same location; if not, querying the location data will not be retrieved.
Non-modal targets are labeled with Scale AI for six foreground target categories: cars, buses, trucks (including cargo, fire trucks, pickup trucks, ambulances), pedestrians, cyclists, and motorcyclists.
This labeling paradigm has three main components: first identifying visible instances of an object, then inferring occluded instance segmentation masks, and finally labeling the occlusion order of each object. Marking is performed on the leftmost forward camera view. Follows the same standards as KINS ("Amodal instance segmentation with kins dataset". CVPR, 2019).
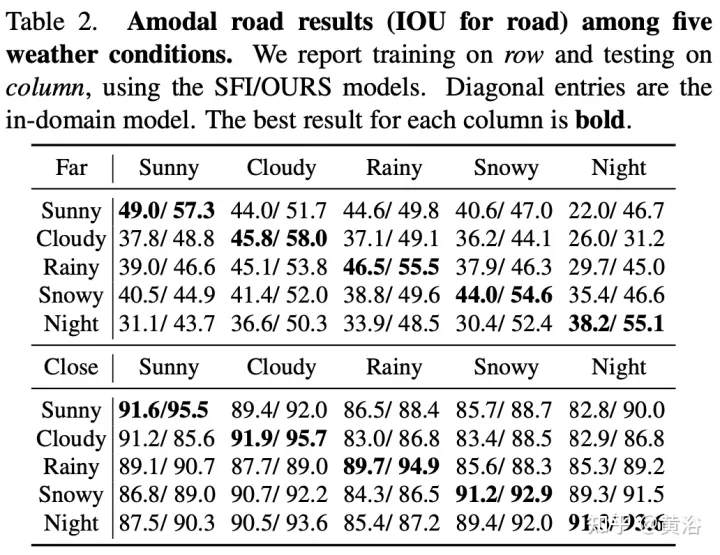
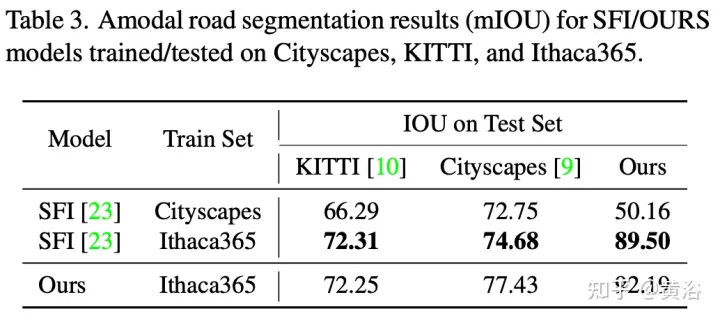
To demonstrate the environmental diversity and amodal quality of the dataset, two baseline networks were trained and tested to identify amodal roads at the pixel level, working even when the roads are covered with snow or cars. The first baseline network is Semantic Foreground Inpainting (SFI). The second baseline, as shown in the figure, adopts the following three innovations to improve SFI.
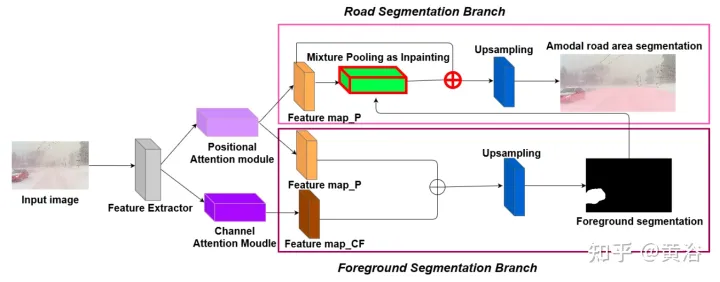
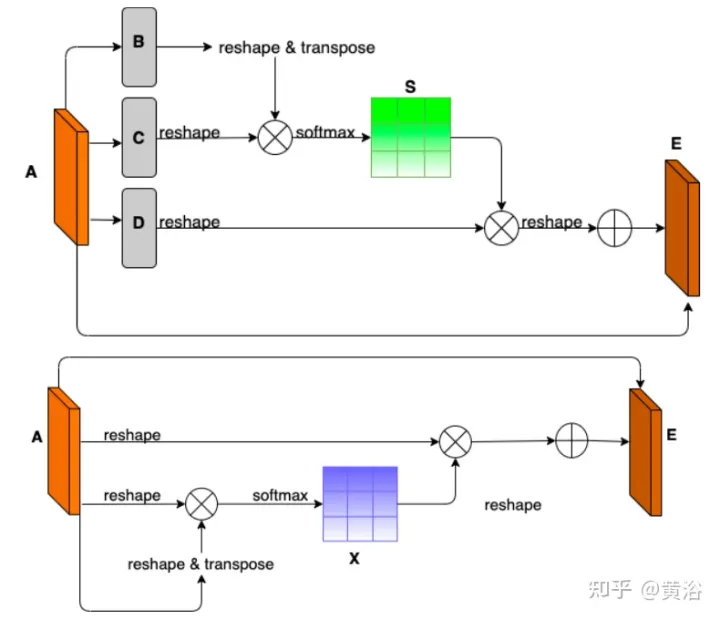
- Position and Channel Note: Because amodal segmentation mainly infers what is invisible, context is a very important clue. DAN ("Dual attention network for scene segmentation", CVPR’2019) introduces two innovations to capture two different backgrounds. The Position Attention Module (PAM) uses pixel features to focus on other pixels of the image, actually capturing context from other parts of the image. The Channel Attention Module (CAM) uses a similar attention mechanism to efficiently aggregate channel information. Here these two modules are applied on the backbone feature extractor. Combining CAM and PAM for better localization of fine mask boundaries. The final foreground instance mask is obtained through an upsampling layer.
- Hybrid pooling as inpainting: Maximum pooling is used as a patching operation to replace overlapping foreground features with nearby background features to help restore non-modal road features. However, since background features are usually smoothly distributed, the max pooling operation is very sensitive to any added noise. In contrast, average pooling operations naturally mitigate noise. To this end, average pooling and maximum pooling are combined for patching, which is called Mixture Pooling.
- Sum operation: Before the final upsampling layer, the features from the hybrid pooling module are not passed directly, but the residual links from the output of the PAM module are included. By jointly optimizing two feature maps in the road segmentation branch, the PAM module can also learn background features of occluded areas. This can lead to more accurate recovery of background features.
The picture shows the architecture diagram of PAM and CAM:
The pseudo code of the hybrid pooling patching algorithm is as follows:

The training and testing codes for non-modal road segmentation are as follows: https://github.com/coolgrasshopper/amodal_road_segmentation
The experimental results are as follows:
##
The above is the detailed content of Datasets and driving perception in repetitive and challenging weather conditions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Intelligent App Control is a very useful tool in Windows 11 that helps protect your PC from unauthorized apps that can damage your data, such as ransomware or spyware. This article explains what Smart App Control is, how it works, and how to turn it on or off in Windows 11. What is Smart App Control in Windows 11? Smart App Control (SAC) is a new security feature introduced in the Windows 1122H2 update. It works with Microsoft Defender or third-party antivirus software to block potentially unnecessary apps that can slow down your device, display unexpected ads, or perform other unexpected actions. Smart application
 The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
With such a powerful AI imitation ability, it is really impossible to prevent it. It is completely impossible to prevent it. Has the development of AI reached this level now? Your front foot makes your facial features fly, and on your back foot, the exact same expression is reproduced. Staring, raising eyebrows, pouting, no matter how exaggerated the expression is, it is all imitated perfectly. Increase the difficulty, raise the eyebrows higher, open the eyes wider, and even the mouth shape is crooked, and the virtual character avatar can perfectly reproduce the expression. When you adjust the parameters on the left, the virtual avatar on the right will also change its movements accordingly to give a close-up of the mouth and eyes. The imitation cannot be said to be exactly the same, but the expression is exactly the same (far right). The research comes from institutions such as the Technical University of Munich, which proposes GaussianAvatars, which
 MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
This article is reprinted with permission from the Autonomous Driving Heart public account. Please contact the source for reprinting. Original title: MotionLM: Multi-Agent Motion Forecasting as Language Modeling Paper link: https://arxiv.org/pdf/2309.16534.pdf Author affiliation: Waymo Conference: ICCV2023 Paper idea: For autonomous vehicle safety planning, reliably predict the future behavior of road agents is crucial. This study represents continuous trajectories as sequences of discrete motion tokens and treats multi-agent motion prediction as a language modeling task. The model we propose, MotionLM, has the following advantages: First
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
"ComputerWorld" magazine once wrote an article saying that "programming will disappear by 1960" because IBM developed a new language FORTRAN, which allows engineers to write the mathematical formulas they need and then submit them. Give the computer a run, so programming ends. A few years later, we heard a new saying: any business person can use business terms to describe their problems and tell the computer what to do. Using this programming language called COBOL, companies no longer need programmers. . Later, it is said that IBM developed a new programming language called RPG that allows employees to fill in forms and generate reports, so most of the company's programming needs can be completed through it.
 Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
In January 2021, OpenAI announced two new models: DALL-E and CLIP. Both models are multimodal models that connect text and images in some way. The full name of CLIP is Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), which is a pre-training method based on contrasting text-image pairs. Why introduce CLIP? Because the currently popular StableDiffusion is not a single model, but consists of multiple models. One of the key components is the text encoder, which is used to encode the user's text input, and this text encoder is the text encoder CL in the CLIP model
 GR-1 Fourier Intelligent Universal Humanoid Robot is about to start pre-sale!
Sep 27, 2023 pm 08:41 PM
GR-1 Fourier Intelligent Universal Humanoid Robot is about to start pre-sale!
Sep 27, 2023 pm 08:41 PM
The humanoid robot is 1.65 meters tall, weighs 55 kilograms, and has 44 degrees of freedom in its body. It can walk quickly, avoid obstacles quickly, climb steadily up and down slopes, and resist impact interference. You can now take it home! Fourier Intelligence's universal humanoid robot GR-1 has started pre-sale. Robot Lecture Hall Fourier Intelligence's Fourier GR-1 universal humanoid robot has now opened for pre-sale. GR-1 has a highly bionic trunk configuration and anthropomorphic motion control. The whole body has 44 degrees of freedom. It has the ability to walk, avoid obstacles, cross obstacles, go up and down slopes, resist interference, and adapt to different road surfaces. It is a general artificial intelligence system. Ideal carrier. Official website pre-sale page: www.fftai.cn/order#FourierGR-1# Fourier Intelligence needs to be rewritten.
 What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
Trajectory prediction has been gaining momentum in the past two years, but most of it focuses on the direction of vehicle trajectory prediction. Today, Autonomous Driving Heart will share with you the algorithm for pedestrian trajectory prediction on NeurIPS - SHENet. In restricted scenes, human movement patterns are usually To a certain extent, it conforms to limited rules. Based on this assumption, SHENet predicts a person's future trajectory by learning implicit scene rules. The article has been authorized to be original by Autonomous Driving Heart! The author's personal understanding is that currently predicting a person's future trajectory is still a challenging problem due to the randomness and subjectivity of human movement. However, human movement patterns in constrained scenes often vary due to scene constraints (such as floor plans, roads, and obstacles) and human-to-human or human-to-object interactivity.
