
 Technology peripherals
AI
Large models accurately feed back small models, and knowledge distillation helps improve AI algorithm performance.
Technology peripherals
AI
Large models accurately feed back small models, and knowledge distillation helps improve AI algorithm performance.
Large models accurately feed back small models, and knowledge distillation helps improve AI algorithm performance.

01 Background of the birth of knowledge distillation
Since then, deep neural networks (DNN) have achieved great success in both industry and academia, especially in computer vision tasks. The success of deep learning is largely due to its scalable architecture for encoding data with billions of parameters. Its training goal is to model the relationship between inputs and outputs on an existing training data set. Performance is highly dependent on the complexity of the network and the amount and quality of labeled training data.
Compared with traditional algorithms in the field of computer vision, most DNN-based models have strong generalization capabilities due to over-parameterization. This kind of generalization The ability to model is reflected in the fact that the model can give better prediction results for all data input to a certain problem, whether it is training data, test data, or unknown data belonging to the problem.
In the current context of deep learning, in order to improve the prediction effect of business algorithms, algorithm engineers often have two solutions:
Use parameterized more complex networks. This type of network The learning ability is very strong, but it requires a lot of computing resources to train, and the inference speed is slow.
Integrated model integrates many models with weaker effects, usually including the integration of parameters and the integration of results.
These two solutions can significantly improve the effect of existing algorithms, but they both increase the scale of the model, generate a greater computational burden, and require large computing and storage resources.
In work, the ultimate purpose of various algorithm models is to serve a certain application. Just like in buying and selling we need to control our income and expenses. In industrial applications, in addition to requiring models to have good predictions, the use of computing resources must also be strictly controlled, and we cannot only consider results without considering efficiency. In the field of computer vision where the amount of input data encoding is high, computing resources are even more limited, and the resource occupancy of the control algorithm is even more important.
Generally speaking, larger models have better prediction results, but the long training time and slow inference speed make it difficult to deploy the model in real time. Especially on devices with limited computing resources, such as video surveillance, self-driving cars, and high-throughput cloud environments, the response speed is obviously not enough. Although smaller models have faster inference speed, due to insufficient parameters, the inference effect and generalization performance may not be as good. How to weigh large-scale models and small-scale models has always been a hot topic. Most of the current solutions are to select a DNN model of appropriate size based on the performance of the terminal device in the deployment environment.
If we want to have a smaller model that can achieve the same or close effect as the large model while maintaining a fast inference speed, how can we do it?
In machine learning, we often assume that there is a potential mapping function relationship between input and output. Learning a new model from scratch is an approximately unknown mapping function between the input data and the corresponding label. On the premise that the input data remains unchanged, training a small model from scratch is difficult to approach the effect of a large model from an empirical point of view. In order to improve the performance of small model algorithms, generally speaking, the most effective way is to label more input data, that is, to provide more supervision information, which can make the learned mapping function more robust and perform better. To give two examples, in the field of computer vision, the instance segmentation task can improve the effect of target bounding box detection by providing additional mask information; the transfer learning task can significantly improve new tasks by providing a pre-trained model on a larger data set. prediction effect. Therefore Providing more supervision information may be the key to shortening the gap between small-scale models and large-scale models.
According to the previous statement, obtaining more supervision information means labeling more training data, which often requires huge costs. So is there a low-cost and efficient method of obtaining supervision information? ? The 2006 article [1] pointed out that the new model can be made to approximate the original model (the model is a function). Because the function of the original model is known, more supervision information is naturally added when training the new model, which is obviously more feasible.
Thinking further, the supervision information brought by the original model may contain different dimensions of knowledge. These unique information may not be captured by the new model itself. To some extent, this is important for the new model. The model is also a kind of "cross-domain" learning.
In 2015, Hinton followed the idea of approximation in the paper "Distilling the Knowledge in a Neural Network" [2] and took the lead in proposing the concept of "Knowledge Distillation (Knowledge Distillation, KD)": you can first train By building a large and powerful model and then transferring the knowledge contained in it to a small model, the purpose of "maintaining the fast reasoning speed of the small model while achieving an effect equivalent to or close to that of the large model" is achieved. The large model trained first can be called the teacher model, and the small model trained later is called the student model. The entire training process can be vividly compared to "teacher-student learning." In the following years, a large amount of knowledge distillation and teacher-student learning work emerged, providing the industry with more new solutions. Currently, KD has been widely used in two different fields: model compression and knowledge transfer [3].

02 Knowledge Distillation
Introduction
Knowledge Distillation is a method based on "teacher-student The model compression method based on the "network" idea is widely used in the industry because of its simplicity and effectiveness. Its purpose is to extract the knowledge contained in the trained large model - Distill (Distill) - into another small model. So how to transfer the knowledge or generalization ability of the large model to the small model? The KD paper provides the probability vector of the sample output of the large model to the small model as a soft target, so that the output of the small model can be as close to this soft target as possible (originally it is to one-hot encoding) to approximate the learning of large models. model behavior.
In the traditional hard label training process, all negative labels are treated uniformly, but this method separates the relationship between categories. For example, if you want to recognize handwritten digits, some pictures with the same label as "3" may look more like "8", and some may look more like "2". Hard labels cannot distinguish this information, but a well-trained large model can give out. The output of the softmax layer of the large model, in addition to positive examples, negative labels also contain a lot of information. For example, the probability corresponding to some negative labels is much greater than other negative labels. The behavior of approximate learning allows each sample to bring more information to the student network than traditional training methods.
Therefore, the author modified the loss function when training the student network, allowing the small model to fit the probability distribution of the large model output while fitting the ground truth labels of the training data. This method is called Knowledge Distillation Training, KD Training. The training samples used in the knowledge distillation process can be the same as those used to train the large model, or an independent Transfer set can be found.
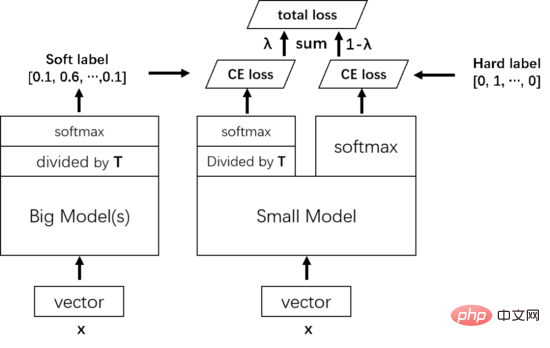 Detailed explanation of method
Detailed explanation of method
Specifically, knowledge distillation uses the Teacher-Student model, where teacher is the output of "knowledge" and student is " recipient of knowledge. The process of knowledge distillation is divided into 2 stages:
- Teacher model training:
- Training "Teacher model", referred to as Net-T, is characterized by a relatively complex model and It can be integrated from multiple separately trained models. There are no restrictions on the model architecture, parameter amount, or integration for the "Teacher model" because the model does not need to be deployed. The only requirement is that for the input X, it can output Y, where Y is mapped by softmax and the output The values correspond to the probability values of the corresponding categories. Student model training:
- Training "Student model", referred to as Net-S, is a single model with a small number of parameters and a relatively simple model structure. Similarly, for input X, it can output Y, and Y can also output the probability value corresponding to the corresponding category after softmax mapping. Because the results of the network using softmax can easily go to extremes, that is, the confidence of a certain class is extremely high, and the confidence of other classes is very low. At this time, the positive class information that the student model pays attention to Maybe it still only belongs to a certain category. In addition, because different categories of negative information also have relative importance, it is not good for all negative scores to be similar, and cannot achieve the purpose of knowledge distillation. In order to solve this problem, the concept of temperature (Temperature) is introduced, and high temperature is used to distill out the information carried by small probability values. Specifically, logits are divided by the temperature T before passing through the softmax function.
During training, the knowledge learned by the teacher model is first distilled to the small model. Specifically, for sample X, the penultimate layer of the large model is first divided by a temperature T, and then a soft target is predicted through softmax. The same goes for the model. The penultimate layer is divided by the same temperature T, and then predicts a result through softmax, and then uses the cross entropy of this result and the soft target as part of the total loss of training. Then the cross entropy of the normal output of the small model and the true value label (hard target) is used as another part of the total loss of training. Total loss weights the two losses together as the final loss for training the small model.
When the small model is trained and needs to be predicted, there is no need for the temperature T anymore, and it can be output directly according to the conventional softmax.
03 FitNet
Introduction
The FitNet paper introduces intermediate-level hints during distillation to guide the training of student models. Use a wide and shallow teacher model to train a narrow and deep student model. When performing hint guidance, it is proposed to use a layer to match the output shapes of the hint layer and the guided layer. This is often called an adaptation layer in the work of future generations.
In general, it is equivalent to using not only the logit output of the teacher model, but also the middle layer feature map of the teacher model as supervision information when doing knowledge distillation. What can be imagined is that it is too difficult for small models to directly imitate large models at the output end (the deeper the model, the more difficult it is to train, and it is quite tiring to transmit the last layer of supervision signals to the front). It is better to add some supervision signals in the middle, so that the model can learn more difficult mapping functions layer by layer during training, instead of directly learning the most difficult mapping function; in addition, hint guidance accelerates the convergence of the student model. Finding better local minima on a non-convex problem allows the student network to be deeper and train faster. It feels like our purpose is to let students do college entrance examination questions, so we first teach them the junior high school questions (first let the small model use the first half of the model to learn to extract the underlying features of the image), and then return to the original purpose , to learn college entrance examination questions (use KD to adjust all parameters of the small model).
This article is the ancestor of the proposed distillation intermediate feature map. The algorithm proposed is very simple, but the idea is groundbreaking.
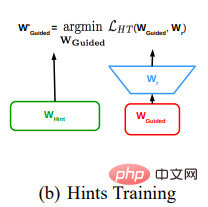
Detailed explanation of the method
The specific method of FitNets is:
- Determine the teacher network and train it Mature, extract the hint from the middle feature layer of the teacher network.
- Set the student network. This network is generally narrower and deeper than the teacher network. The student network is trained so that the intermediate feature layers of the student network match the hints of the teacher model. Since the middle feature layer of the student network and the teacher hint size are different, it is necessary to add a regressor after the middle feature layer of the student network for feature dimensionality enhancement to match the hint layer size. The loss function that matches the hint layer of the teacher network and the intermediate feature layer of the student network transformed by the regressor is the mean square error loss function.
In actual training, it is often used in conjunction with KD Training in the previous section, using a two-stage method for training: first use hint training to pretrain the parameters of the first half of the small model, and then use KD Training to train the entire parameter. Since more supervision information is used in the distillation process, the distillation method based on the intermediate feature map performs better than the distillation method based on the result logits, but the training time is longer.
04 Summary
Knowledge distillation is very effective for transferring knowledge from an ensemble or from a highly regularized large model to a smaller model. Distillation works very well even when data for any one or more classes is missing from the migration dataset used to train the distillation model. After the classics KD and FitNet were proposed, a variety of distillation methods sprung up. In the future, we also hope to make further exploration in the fields of model compression and knowledge transfer.
About the author
Ma Jialiang is a senior computer vision algorithm engineer at NetEase Yidun. He is mainly responsible for the research, development, optimization and innovation of computer vision algorithms in the field of content security.
The above is the detailed content of Large models accurately feed back small models, and knowledge distillation helps improve AI algorithm performance.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C? Answer: Use loop statements. Steps: 1. Define the variable n and store the countdown number to output; 2. Use the while loop to continuously print n until n is less than 1; 3. In the loop body, print out the value of n; 4. At the end of the loop, subtract n by 1 to output the next smaller reciprocal.
 What are the rules for function definition and call in C language?
Apr 03, 2025 pm 11:57 PM
What are the rules for function definition and call in C language?
Apr 03, 2025 pm 11:57 PM
A C language function consists of a parameter list, function body, return value type and function name. When a function is called, the parameters are copied to the function through the value transfer mechanism, and will not affect external variables. Pointer passes directly to the memory address, modifying the pointer will affect external variables. Function prototype declaration is used to inform the compiler of function signatures to avoid compilation errors. Stack space is used to store function local variables and parameters. Too much recursion or too much space can cause stack overflow.
 How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to achieve the playback of pictures like videos? Many times, we need to implement similar video player functions, but the playback content is a sequence of images. direct...
 CS-Week 3
Apr 04, 2025 am 06:06 AM
CS-Week 3
Apr 04, 2025 am 06:06 AM
Algorithms are the set of instructions to solve problems, and their execution speed and memory usage vary. In programming, many algorithms are based on data search and sorting. This article will introduce several data retrieval and sorting algorithms. Linear search assumes that there is an array [20,500,10,5,100,1,50] and needs to find the number 50. The linear search algorithm checks each element in the array one by one until the target value is found or the complete array is traversed. The algorithm flowchart is as follows: The pseudo-code for linear search is as follows: Check each element: If the target value is found: Return true Return false C language implementation: #include#includeintmain(void){i
 Integers in C: a little history
Apr 04, 2025 am 06:09 AM
Integers in C: a little history
Apr 04, 2025 am 06:09 AM
Integers are the most basic data type in programming and can be regarded as the cornerstone of programming. The job of a programmer is to give these numbers meanings. No matter how complex the software is, it ultimately comes down to integer operations, because the processor only understands integers. To represent negative numbers, we introduced two's complement; to represent decimal numbers, we created scientific notation, so there are floating-point numbers. But in the final analysis, everything is still inseparable from 0 and 1. A brief history of integers In C, int is almost the default type. Although the compiler may issue a warning, in many cases you can still write code like this: main(void){return0;} From a technical point of view, this is equivalent to the following code: intmain(void){return0;}
 How to define the call declaration format of c language function
Apr 04, 2025 am 06:03 AM
How to define the call declaration format of c language function
Apr 04, 2025 am 06:03 AM
C language functions include definitions, calls and declarations. Function definition specifies function name, parameters and return type, function body implements functions; function calls execute functions and provide parameters; function declarations inform the compiler of function type. Value pass is used for parameter pass, pay attention to the return type, maintain a consistent code style, and handle errors in functions. Mastering this knowledge can help write elegant, robust C code.
 Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Data update problems in zustand asynchronous operations. When using the zustand state management library, you often encounter the problem of data updates that cause asynchronous operations to be untimely. �...
 How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
A solution to implement text annotation nesting in Quill Editor. When using Quill Editor for text annotation, we often need to use the Quill Editor to...
