
 Technology peripherals
AI
Barrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship
Technology peripherals
AI
Barrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship
Barrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship

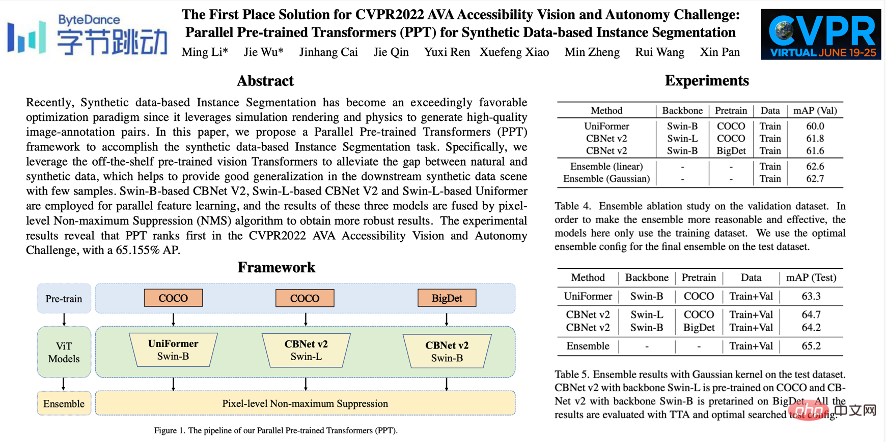
Recently, the results of various CVPR2022 competitions have been announced one after another. The ByteDance intelligent creation AI platform "Byte-IC-AutoML" team won the Instance Segmentation Challenge based on synthetic data (Accessibility Vision and Autonomy Challenge, hereinafter referred to as AVA). ), with the self-developed Parallel Pre-trained Transformers (PPT) framework, he stood out and became the winner of the only track in the competition.
Paper address:https:/ /www.php.cn/link/ede529dfcbb2907e9760eea0875cdd12
This AVA competition is jointly organized by Boston University and Carnegie Mellon University .
The competition derives a synthetic instance segmentation dataset via a rendering engine containing data samples of autonomous systems interacting with disabled pedestrians. The goal of the competition is to provide benchmarks and methods for target detection and instance segmentation for people and objects related to accessibility.

Dataset visualization
Analysis of competition difficulties
- Domain generalization problem: The data sets of this competition are all images synthesized by the rendering engine, and there are significant differences between the data domain and natural images;
- Long-tail/few-sample problem: The data has a long-tail distribution, such as "Crutches" and "Wheelchair" categories are fewer in the data set, and the segmentation effect is also worse;
- Segmentation robustness problem: The segmentation effect of some categories is very poor. The instance segmentation mAP is 30 lower than the target detection segmentation mAP
Detailed explanation of the technical solution
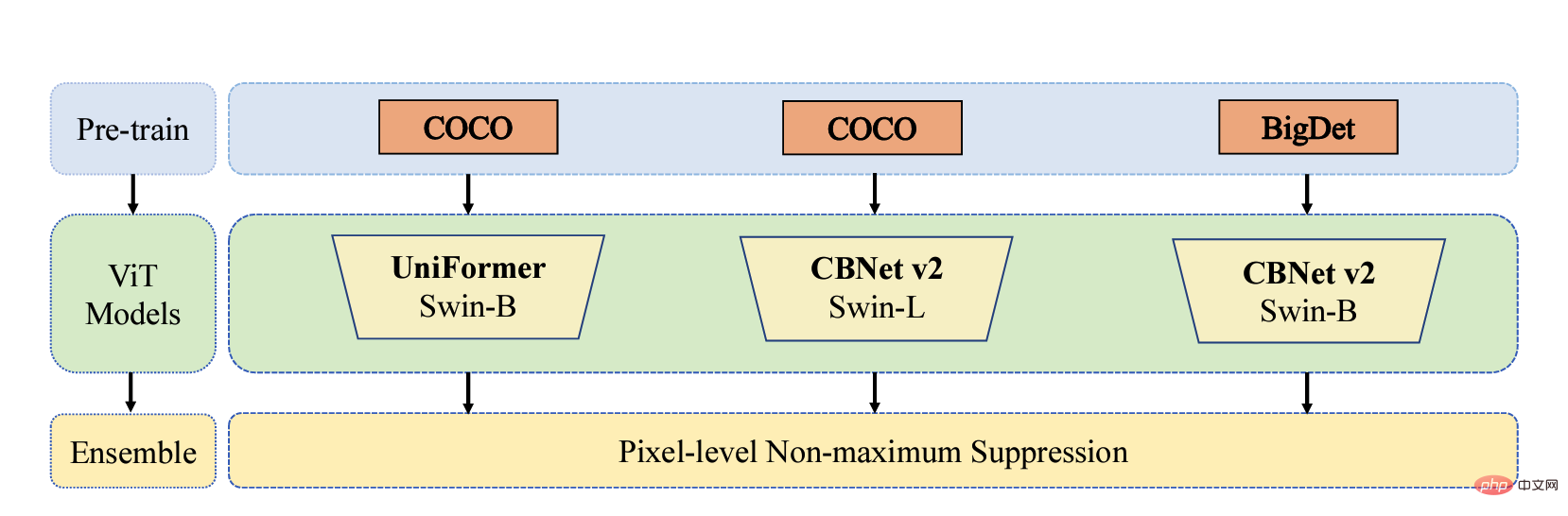
The Byte-IC-AutoML team proposed a Parallel Pre-trained Transformers (PPT) framework to accomplish this. The framework mainly consists of three modules: 1) Parallel large-scale pre-trained Transformers; 2) Balance Copy-Paste data enhancement; 3) Pixel-level non-maximum suppression and model fusion;
parallel large-scale pre-training Transformers
Many recent pre-training articles have shown that models pre-trained on large-scale data sets can generalize well to different downstream scenarios. Therefore, the team uses the COCO and BigDetection data sets to pre-train the model first, which can alleviate the domain deviation between natural data and synthetic data to a greater extent so that it can be used downstream Fast training with fewer samples in synthetic data scenarios. At the model level, considering that Vision Transformers do not have the inductive bias of CNN and can enjoy the benefits of pre-training, the team uses UniFormer and CBNetV2. UniFormer unifies convolution and self-attention, simultaneously solves the two major problems of local redundancy and global dependency, and achieves efficient feature learning. The CBNetV2 architecture concatenates multiple identical backbone packets through composite connections to build high-performance detectors. The backbone feature extractors of the model are all Swin Transformer. Multiple large-scale pre-trained Transformers are arranged in parallel, and the output results are integrated and learned to output the final result.
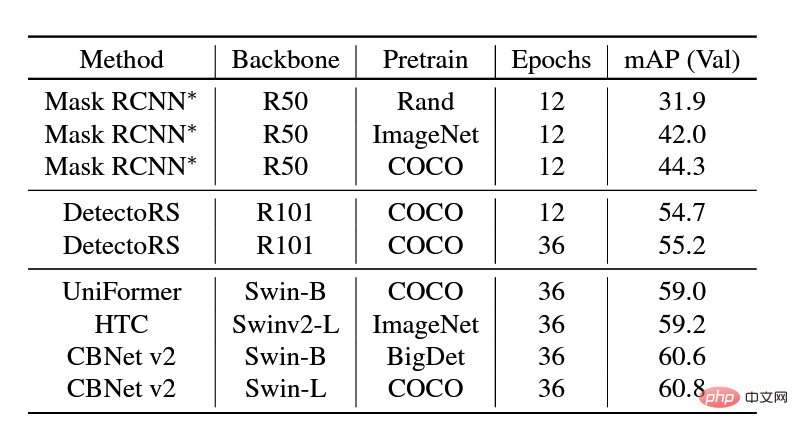
mAP of different methods on the validation data set
Balance Copy-Paste Data Enhancement
Copy-Paste technique provides impressive results for instance segmentation models by randomly pasting objects, especially for datasets under long-tail distribution. However, this method evenly increases the samples of all categories and fails to fundamentally alleviate the long-tail problem of category distribution. Therefore, the team proposed the Balance Copy-Paste data enhancement method. Balance Copy-Paste adaptively samples categories according to the effective number of categories, improves the overall sample quality, alleviates the problems of small number of samples and long-tail distribution, and ultimately greatly improves the mAP of the model in instance segmentation.
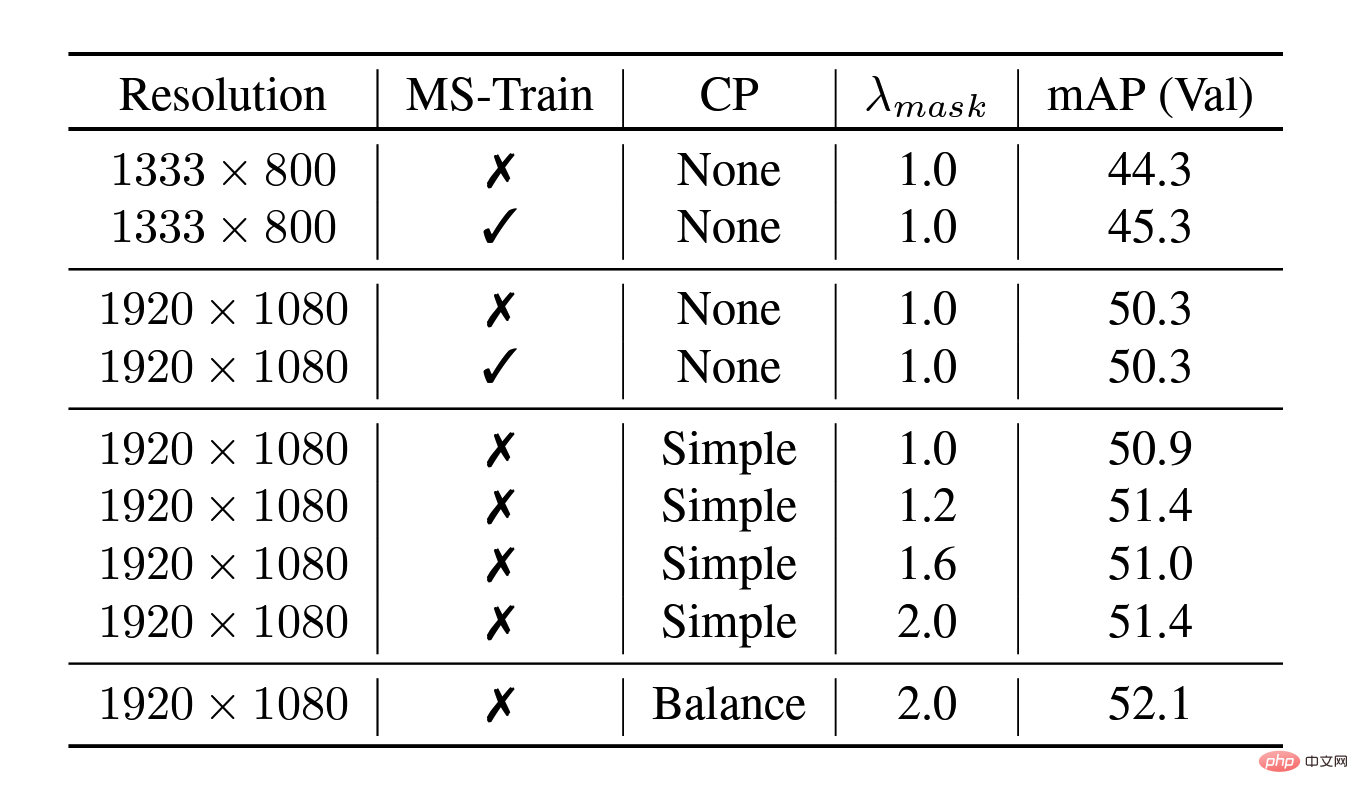
Improvements brought by Balance Copy-Paste data enhancement technology
Pixel-level non-maximum suppression and Model fusion
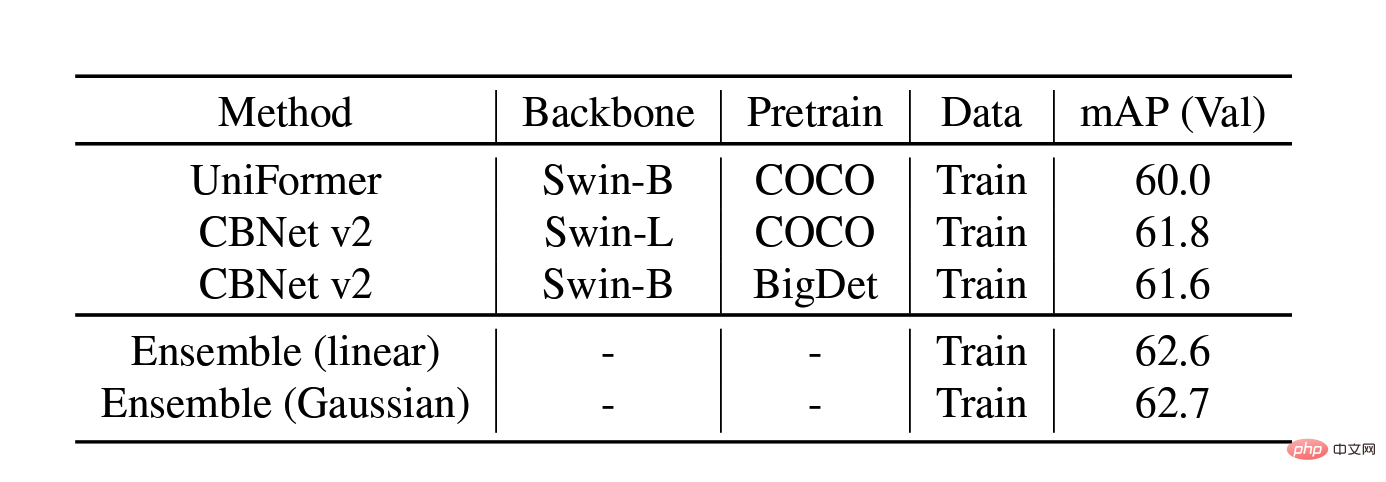
Model fusion ablation experiment on the validation set
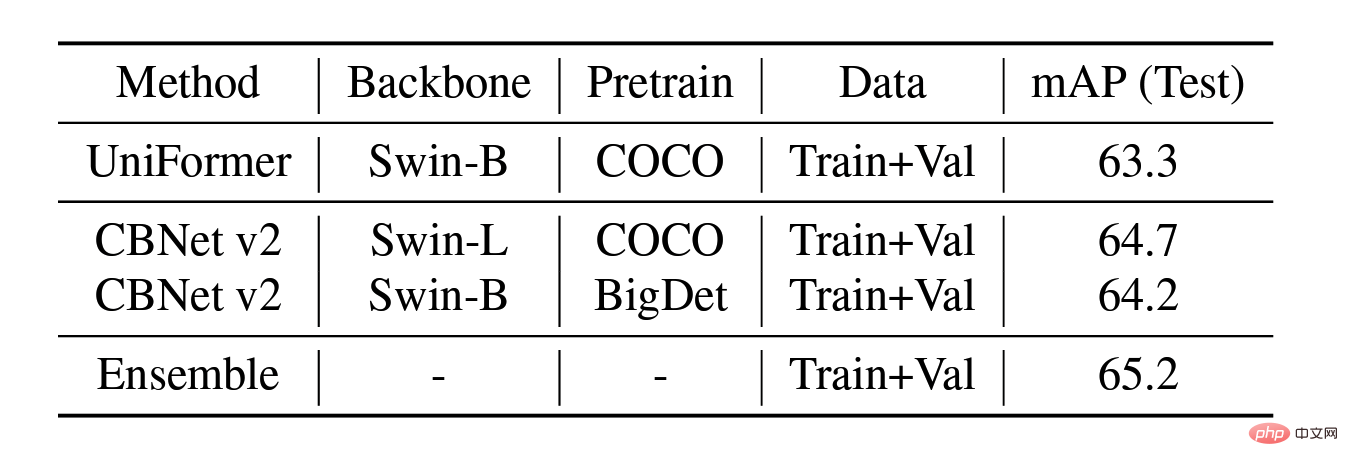
Test Model fusion ablation experiment on the set
Currently, urban and traffic data sets are more general scenes, including only normal transportation and pedestrians. The data set lacks information about disabled people and their actions. Inconvenient people and the types of their assistive devices cannot be detected by detection models using currently existing data sets.
This technical solution of ByteDance’s Byte-IC-AutoML team is widely used in current autonomous driving and street scene understanding: the model obtained through these synthetic data can identify “ Rare categories such as "wheelchair", "person in wheelchair", "person on crutches", etc. can not only classify people/objects more precisely, but also avoid misjudgment and misjudgment leading to misunderstanding of the scene. In addition, through this method of synthesizing data, data of relatively rare categories in the real world can be constructed, thereby training a more versatile and complete target detection model.
Intelligent Creation is ByteDance’s multimedia innovation technology research institute and comprehensive service provider. Covering computer vision, graphics, voice, shooting and editing, special effects, clients, AI platforms, server engineering and other technical fields, a closed loop of cutting-edge algorithms-engineering systems-products has been implemented within the department, aiming to use multiple In this way, we provide the company's internal business lines and external cooperative customers with the industry's most cutting-edge content understanding, content creation, interactive experience and consumption capabilities and industry solutions. The team's technical capabilities are being opened to the outside world through Volcano Engine.
Volcano Engine is a cloud service platform owned by Bytedance. It opens the growth methods, technical capabilities and tools accumulated during the rapid development of Bytedance to external enterprises, providing cloud foundation, Services such as video and content distribution, big data, artificial intelligence, development and operation and maintenance help enterprises achieve sustained growth during digital upgrades.
The above is the detailed content of Barrier-free travel is safer! ByteDance's research results won the CVPR2022 AVA competition championship. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 The marketing effect has been greatly improved, this is how AIGC video creation should be used
Jun 25, 2024 am 12:01 AM
The marketing effect has been greatly improved, this is how AIGC video creation should be used
Jun 25, 2024 am 12:01 AM
After more than a year of development, AIGC has gradually moved from text dialogue and picture generation to video generation. Looking back four months ago, the birth of Sora caused a reshuffle in the video generation track and vigorously promoted the scope and depth of AIGC's application in the field of video creation. In an era when everyone is talking about large models, on the one hand we are surprised by the visual shock brought by video generation, on the other hand we are faced with the difficulty of implementation. It is true that large models are still in a running-in period from technology research and development to application practice, and they still need to be tuned based on actual business scenarios, but the distance between ideal and reality is gradually being narrowed. Marketing, as an important implementation scenario for artificial intelligence technology, has become a direction that many companies and practitioners want to make breakthroughs. Once you master the appropriate methods, the creative process of marketing videos will be
 How to explore and visualize ML data for object detection in images
Feb 16, 2024 am 11:33 AM
How to explore and visualize ML data for object detection in images
Feb 16, 2024 am 11:33 AM
In recent years, people have gained a deeper understanding of the importance of deeply understanding machine learning data (ML-data). However, since detecting large data sets usually requires a lot of human and material investment, its widespread application in the field of computer vision still requires further development. Usually, in object detection (a subset of computer vision), objects in the image are positioned by defining bounding boxes. Not only can the object be identified, but the context, size, and relationship between the object and other elements in the scene can also be understood. Relationship. At the same time, a comprehensive understanding of the distribution of classes, the diversity of object sizes, and the common environments in which classes appear will also help to discover error patterns in the training model during evaluation and debugging, thereby
 Detailed explanation of deep learning pre-training model in Python
Jun 11, 2023 am 08:12 AM
Detailed explanation of deep learning pre-training model in Python
Jun 11, 2023 am 08:12 AM
With the development of artificial intelligence and deep learning, pre-training models have become a popular technology in natural language processing (NLP), computer vision (CV), speech recognition and other fields. As one of the most popular programming languages at present, Python naturally plays an important role in the application of pre-trained models. This article will focus on the deep learning pre-training model in Python, including its definition, types, applications and how to use the pre-training model. What is a pretrained model? The main difficulty of deep learning models is to analyze a large number of high-quality
 The technical strength of Huoshan Voice TTS has been certified by the National Inspection and Quarantine Center, with a MOS score as high as 4.64
Apr 12, 2023 am 10:40 AM
The technical strength of Huoshan Voice TTS has been certified by the National Inspection and Quarantine Center, with a MOS score as high as 4.64
Apr 12, 2023 am 10:40 AM
Recently, the Volcano Engine speech synthesis product has obtained the speech synthesis enhanced inspection and testing certificate issued by the National Speech and Image Recognition Product Quality Inspection and Testing Center (hereinafter referred to as the "AI National Inspection Center"). It has met the basic requirements and extended requirements of speech synthesis. The highest level standard of AI National Inspection Center. This evaluation is conducted from the dimensions of Mandarin Chinese, multi-dialects, multi-languages, mixed languages, multi-timbrals, and personalization. The product’s technical support team, the Volcano Voice Team, provides a rich sound library. After evaluation, its timbre MOS score is the highest. It reached 4.64 points, which is at the leading level in the industry. As the first and only national quality inspection and testing agency for voice and image products in the field of artificial intelligence in my country’s quality inspection system, the AI National Inspection Center has been committed to promoting intelligent
 Focusing on personalized experience, retaining users depends entirely on AIGC?
Jul 15, 2024 pm 06:48 PM
Focusing on personalized experience, retaining users depends entirely on AIGC?
Jul 15, 2024 pm 06:48 PM
1. Before purchasing a product, consumers will search and browse product reviews on social media. Therefore, it is becoming increasingly important for companies to market their products on social platforms. The purpose of marketing is to: Promote the sale of products Establish a brand image Improve brand awareness Attract and retain customers Ultimately improve the profitability of the company The large model has excellent understanding and generation capabilities and can provide users with personalized information by browsing and analyzing user data content recommendations. In the fourth issue of "AIGC Experience School", two guests will discuss in depth the role of AIGC technology in improving "marketing conversion rate". Live broadcast time: July 10, 19:00-19:45 Live broadcast topic: Retaining users, how does AIGC improve conversion rate through personalization? The fourth episode of the program invited two important
 An in-depth exploration of the implementation of unsupervised pre-training technology and 'algorithm optimization + engineering innovation' of Huoshan Voice
Apr 08, 2023 pm 12:44 PM
An in-depth exploration of the implementation of unsupervised pre-training technology and 'algorithm optimization + engineering innovation' of Huoshan Voice
Apr 08, 2023 pm 12:44 PM
For a long time, Volcano Engine has provided intelligent video subtitle solutions based on speech recognition technology for popular video platforms. To put it simply, it is a function that uses AI technology to automatically convert the voices and lyrics in the video into text to assist in video creation. However, with the rapid growth of platform users and the requirement for richer and more diverse language types, the traditionally used supervised learning technology has increasingly reached its bottleneck, which has put the team in real trouble. As we all know, traditional supervised learning will rely heavily on manually annotated supervised data, especially in the continuous optimization of large languages and the cold start of small languages. Taking major languages such as Chinese, Mandarin and English as an example, although the video platform provides sufficient voice data for business scenarios, after the supervised data reaches a certain scale, it will continue to
 All Douyin is speaking native dialects, two key technologies help you 'understand” local dialects
Oct 12, 2023 pm 08:13 PM
All Douyin is speaking native dialects, two key technologies help you 'understand” local dialects
Oct 12, 2023 pm 08:13 PM
During the National Day, Douyin’s “A word of dialect proves that you are from your hometown” campaign attracted enthusiastic participation from netizens from all over the country. The topic topped the Douyin challenge list, with more than 50 million views. This “Local Dialect Awards” quickly became popular on the Internet, which is inseparable from the contribution of Douyin’s newly launched local dialect automatic translation function. When the creators recorded short videos in their native dialect, they used the "automatic subtitles" function and selected "convert to Mandarin subtitles", so that the dialect speech in the video can be automatically recognized and the dialect content can be converted into Mandarin subtitles. This allows netizens from other regions to easily understand various "encrypted Mandarin" languages. Netizens from Fujian personally tested it and said that even the southern Fujian region with "different pronunciation" is a region in Fujian Province, China.
