

Rapidly build 3D models based on artificial intelligence technology

Translator|Zhu Xianzhong
Reviewer|Sun Shujuan

Figure 1: Cover
Generating a 3D model can be time-consuming , or require a large number of reference images. One way to solve this problem is to use neural radiance fields (NeRF), an artificial intelligence method of generating images. The main idea of NERF is to take a small set of 2D images of the object or scene you photographed, and then use these 2D images to efficiently build a 3D representation. This is achieved by learning to transform between existing images. Now this jumping (also called "interpolation") technique can help you create images of new perspectives on objects!
Sounds good, right? With the help of a small set of images, you can make a 3D model! This works better than standard photogrammetry, which requires a huge library of images to generate some pictures (you need shots from every angle). However, NVIDIA did initially promise that NeRFs would be fast; however, until recently this was not the case. Previously, NeRFs tended to take a long time to learn how to convert a set of images into a 3D model.
But today, this is no longer the case. Recently, NVIDIA developed instant NeRF software that leverages GPU hardware to run the necessary complex calculations. This approach reduces the time required to create a model from days to seconds! NVIDIA makes many exciting claims about the usability and speed of instant-ngp software. Moreover, the results and examples they provided are also very impressive:

#Figure 2: NeRF image display-NVIDIA has a cool robotics lab
I find it hard not to be impressed by this demo - it looks amazing! So, I wanted to see how easy it would be to transfer this to my own images and generate my own NeRF model. So, I decided to install and use this software myself. In this article I will describe my experience with the experiment and detail the model I made!
Main task division
So what should we do? The roughly staged tasks are divided as follows:
- First of all, we need to quote some footage. Let's go record some videos we want to make in 3D!
- Then we start shooting the scene and convert the captured video into multiple still images.
- We pass the continuous image data obtained above to instant-ngp. Then, the AI is trained to understand the spaces between the images we generate. This is actually the same as making a 3D model.
- Finally, we wanted to create a video showing off our creation! In the software developed by NVIDIA, we will draw a path, let the camera take us through the model we made, and then render the video.
I won’t go into detail about how this all works, but I will provide links to many resources that I have found helpful. So, next, I'm going to focus on the videos I made, and some tidbits of knowledge I stumbled upon along the way.
Start My Experiment
NVIDIA's instant NeRF software is not easy to install. While the instructions for the software are clear, I feel like the required portion of the instructions doesn't offer a lot of wiggle room when it comes to the specific version of the software a person needs. It seemed impossible to me to use CUDA 11.7 or VS2022, but I think it was switching back to the CUDA 11.6 version and VS2019 that finally made the installation successful. Among them, I encountered many errors, such as "CUDA_ARCHITECTURES is empty for target", etc. This is because the cooperation between CUDA and Visual Studio is not friendly. Therefore, I sincerely recommend interested readers to refer to the video and the warehouse resources on Github to further help you set everything up smoothly. Work!
Other than that, this process is going smoothly. The official also provides a Python script to help guide the steps of converting the captured video into an image, and subsequently converting it into a model and video.
Experiment 1: LEGO Car
At first, I tried to NeRF-ify a small LEGO car in my office. I felt like my photography skills were nowhere near enough as I simply couldn't create any meaningful images. Just a weird 3D blemish. Forget it, let's take a look at an example provided by NVIDIA. Please note the position of the camera in the picture:
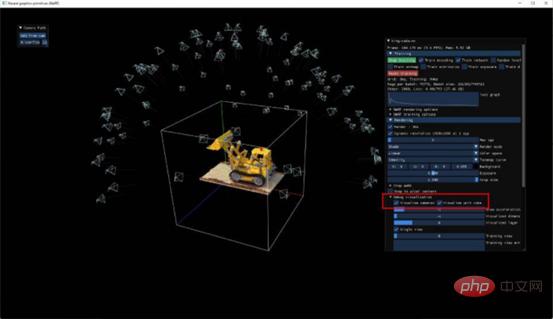
Figure 3: The "camera" position of the default NeRF model of the excavator provided by NVIDIA
One of the preparation settings that can work well for training is to place a "camera" in the scene as described in the picture above . These cameras are the angles the software thinks you're facing when shooting video. It should be a nice circle. Of course, my first Lego car didn’t look like this at all, but a squashed semicircle.
Experiment 2: Slightly Larger LEGO Car
To learn from the first experiment, I found a table with full mobility and found a larger Lego cars. I try to make sure I capture photos for longer periods of time than before, too. Finally, I shot a smooth 1-minute video from all angles. In total, it took me less than 30 seconds to train the model. Here’s the video I made after 4 hours of rendering at 720p:

Figure 4: My second NeRF model – a LEGO Technic car!
Experiment 3: Plants
The results prove that the above experiment 2 is better, at least technically feasible. However, there is still a strange fog, which is certainly not super troublesome. In my next experiment, I also tried shooting from further back (I'm assuming the fog is caused by the AI being "confused" about what's there). I'm trying to have more control over the aabc_scale parameter (which measures how big the scene is) and then train it for a few minutes. At the end of the rendering, the video result is obtained as shown below:

Figure 5: A NeRF model I made from a plant on the living room table
much better! It’s impressive how it represents the intricacies of the crocheted plant pots, the grooves in the wood, and the foliage with such precision. Look at the camera swooping over the leaves!
Test 4:
Now, our test results are getting better and better! However, I would like an outdoor video. I shot less than 2 minutes of video outside my apartment and started processing it. This is especially cumbersome for rendering/training. My guess here is that my aabc_scale value is quite high (8), so the rendering "rays" must go very far (i.e. the number of things I want to render is higher). So, I had to switch to 480p and lower the rendering FPS from 30 to 10. It turns out that the choice of setting parameters does affect rendering time. After 8 hours of rendering, I ended up with the following:

Figure 6: A NeRF model I used outside my apartment
However, I think The third trial is still my favorite. I think I could have done the fourth trial a little better. However, when render times become very long, it becomes difficult to iterate through versions and experiment with different rendering and training settings. It's now difficult to even set the camera angle for rendering, which causes my program to become extremely slow.
However, this is truly a pretty amazing output, since only a minute or two of video data was used. Finally, I finally have a detailed and realistic 3D model!
Pros and cons analysis
What I think is most impressive is that in 1-2 minutes of shooting, someone with absolutely no photogrammetry training (me) could create a workable 3D model. The process does require some technical know-how, but once you have everything set up, it's easy to use. Using a Python script to convert videos to images works great. Once this is done, inputting into the AI will proceed smoothly.
However, while it's hard to fault Nvidia for this aspect, I feel I should bring it up: this thing requires a pretty powerful GPU. I have a T500 in my laptop and this task simply pushed it to its absolute limits. The training time is indeed much longer than the advertised 5 seconds, and trying to render at 1080p will cause the program to crash (I chose to render dynamically around the 135*74 indicator). Now, this is still a huge improvement, as previous NeRF model experiments took several days.
I don't think everyone will have a 3090p device for a project like this, so it's worth briefly explaining. The low performance computer made the program difficult to use, especially when I was trying to get the camera to "fly" in order to have a more conducive setup for rendering video. Still, the results of the process are impressive.
Also, another problem I faced was not being able to find the render file render.py (which, as you might guess, is crucial for rendering videos). Very strangely, it is not in the officially provided open source code repositories, despite being heavily mentioned in most advertising articles and other documentation. Therefore, I have to dig out this treasure from the link https://www.php.cn/link/b943325cc7b7422d2871b345bf9b067f.
Finally, I also hope to convert the above 3D model into an .obj file. Maybe now, this is possible.

Figure 7: GIF animation of a fox - this is not made by me, it is made by NVIDIA. Not bad, right?
Summary and next thoughts
Personally, I am looking forward to more experimental results in this area. I want to be able to generate super realistic models and then dump them into AR/VR. Based on these technologies, you can even host web meetings – isn’t that fun? Because you only need to use the camera on your phone to achieve this goal, and most users already have this hardware configuration in their phones today. Overall, I'm impressed. It's great to be able to record a 1 minute video on your phone and turn it into a model you can step through. Although it takes a while to render and is a bit difficult to install, it works great. After a few experiments, I've got pretty cool output! I'm looking forward to more experiments! ReferencesNVIDIA Git
NVIDIA blog
Supplemental Git
Translator introduction Zhu Xianzhong, 51CTO community editor, 51CTO expert blogger, lecturer, computer teacher at a university in Weifang, veteran in the freelance programming industry One piece. In the early days, he focused on various Microsoft technologies (compiled three technical books related to ASP.NET AJX and Cocos 2d-X). In the past ten years, he has devoted himself to the open source world (familiar with popular full-stack web development technology) and learned about OneNet/AliOS Arduino/ IoT development technologies such as ESP32/Raspberry Pi and big data development technologies such as Scala Hadoop Spark Flink.Original title: Using AI to Generate 3D Models, Fast!, author: Andrew Blance
The above is the detailed content of Rapidly build 3D models based on artificial intelligence technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
